
预测Instance Mask的一种直接方法是采用全卷积网络,例如语义分割中的FCN 。然而,常规的卷积运算在某种程度上在空间上是不变的。空间不变性对于某些任务(例如图像分类)是理想的,因为它会引入鲁棒性。但是,因为我们的分割mask以网格为条件,并且必须由不同的特征通道分开,因此在这里我们需要一个空间变化的模型,或者更精确地说,是位置敏感的模型。
做法比较简单,在网络初期引入两个feature map,一个是x坐标,一个y坐标,归一化在[-1,1]之间,以concatenate的方式与原始tensor结合。
SOLO是怎样起作用的

上图显示了由S = 12个网格生成的网络输出。子图(i,j)表示相应的mask通道产生的soft mask预测结果。 在这里我们可以看到不同的实例在不同的掩码预测通道上激活。 通过在不同位置显式分割实例,SOLO将实例分割问题转换为位置感知分类任务。在每个网格处将仅激活一个实例,并且可以通过多个相邻的mask通道来预测一个实例。 在推理期间,我们使用NMS来抑制这些冗余mask。
Decoupled SOLO
当格子数量比较大时,如S取20,则会生成400个Instance Mask,在大部分情况下,图像中的目标比较稀疏且少,没必要太多的Instance Mask。
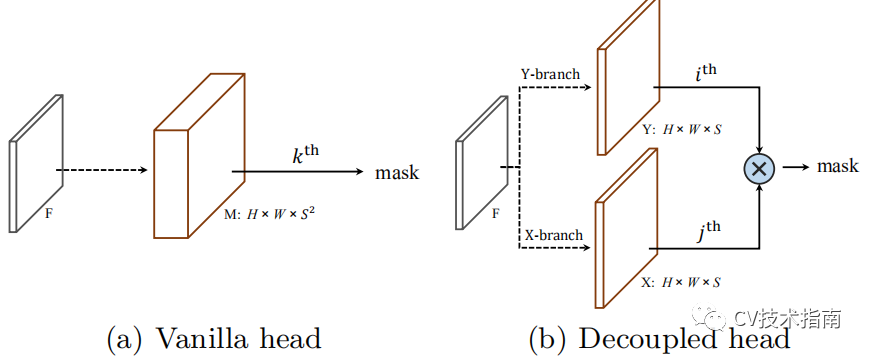
如上图所示,将原来的输出tensor HxWxS^2用两个形状为HxWxS的tensor来代替,分别为x, y。而位置(i,j)的mask通过Xj 与Yi逐元素相乘获得。
这种分解方式比原来的方式需要的内存更少,而精度几乎一样。
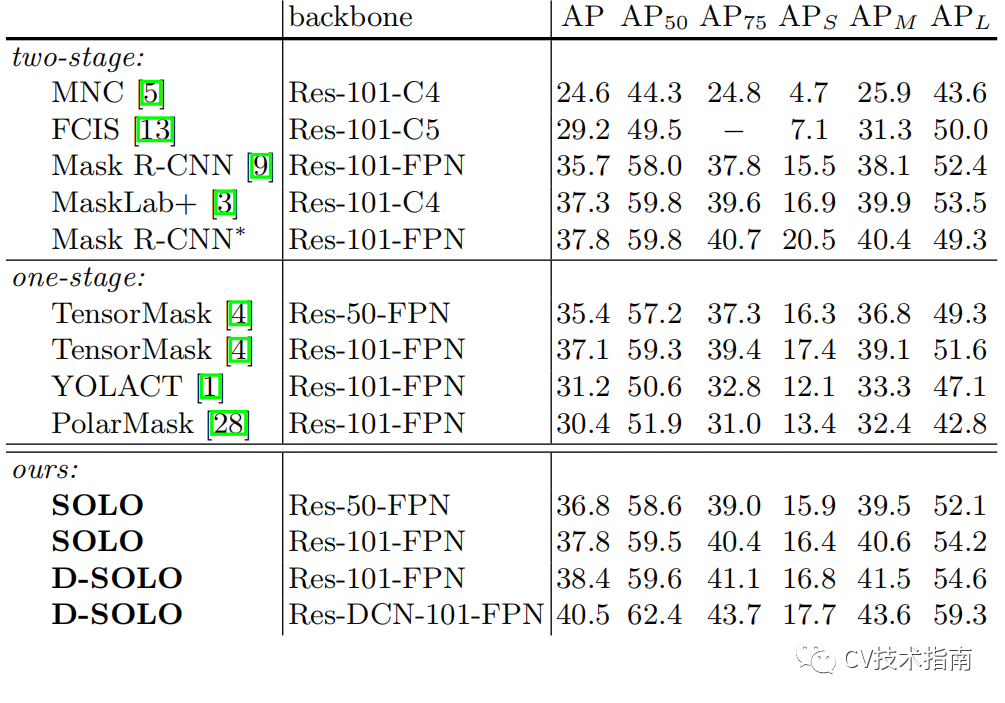
Conclusion
本文来源于公众号CV技术指南的论文分享系列,更多内容请扫描文末二维码关注公众号。