
这是实例分割中的一篇经典论文,以往的实例分割模型都比较复杂,这篇论文提出了一个简单且直接的实例分割模型,如何设计这种简单直接的模型且要达到一定的精度往往会存在一些困难,论文中有很多思路或思想值得借鉴,因此十分值得一读。
在本文中,为让各个方向的读者都能看得懂并抓住重点,较为详细地介绍了本文的创新或改进思路,而对一些细节不予赘述。
论文:SOLO: Segmenting Objects by Locations*
代码:https://git.io/AdelaiDet
Introduction
实例分割需要正确分离图像中所有对象,同时还需要在像素级别对每个实例进行语义分割。最近的实例分割方法可以分类为两组,即自上而下和自下而上的范式。
第一种方法“detect-then-segment”,首先检测边界框,然后在每个边界框中分割instance mask。第二种方法通过推开属于不同实例的像素并拉近同一实例中的像素来学习亲和关系,将embedding vector分配给每个像素,然后需要进行分组后处理以分离实例。这两种范式都是step-wise的和indirect,它们要么严重依赖于精确的边界框检测,要么依赖于每个像素的embedding 学习和分组处理。
相比之下,我们的目标是在完整instance mask标注的监督下直接分割instance mask,而不是检测框内的mask或其他像素对关系。我们重新开始思考一个问题:在一张图片中,什么是目标实例之间最本质的区别呢?
作者分析了MS COCO数据集,验证子集中总共有36个,780个对象,其中98.3%的对象对的中心距离大于30个像素。至于其余的1.7%的对象对,其中40.5%的大小比大于1.5倍。总之,在大多数情况下,图像中的两个实例要么具有不同的中心位置,要么具有不同的对象大小。这一发现使我们怀疑是否可以通过中心位置和对象大小直接区分实例?
在语义分割中,现在的主流范式利用全卷积网络(FCN)来输出具有N个通道的密集预测。每个输出通道负责一个语义类别(包括背景)。语义分割旨在区分不同的语义类别。类似地,在这项工作中,我们建议通过引入“ instance categories ”的概念来区分图像中的对象实例,即量化的中心位置和对象大小,从而可以按位置对对象进行分割,因此我们的方法名称为SOLO。
SOLO结构
前面提到作者认为图像中实例对象之间最基础的区别在于大小和位置,因此,SOLO使用FPN来生成通道数相同但大小不同的特征金字塔,来实现不同大小的实例对象在不同的level进行检测。对于金字塔每一层的feature maps都输入到两个预测头中。
注:为了简化图示,在这里没有显示特征金字塔网络(FPN),下图中的FCN没写错,后面会介绍。
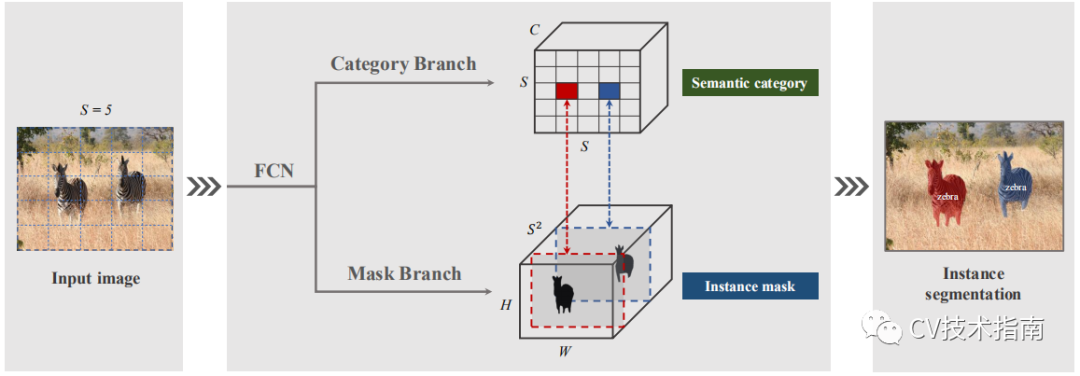
如上图所示,将实例细分重新定义为两个子任务:类别预测和instance mask生成。输入图像被分成均匀的网格,即S×S。如果目标的中心落入网格单元,则该网格单元负责预测语义类别(Category Branch)和实例掩码(Mask Branch)。
注:金字塔每层的预测头的权重是共享的。
格子数量(即S)在不同层是不一样的。
Semantic Category
这个做法与YOLO相同,通过FPN把图像分成S x S 的网格,其张量形状为S x S x C。其中每个格子属于一个单独的实例,因此每个格子只属于一个语义类别。每个格子只要是在ground truth的区域内,它就是positive。在推理阶段,C维通道预测该格子属于每个目标实例的可能性,C =类别数量。
Instance Mask
可以看到上面那个图中,Semantic Category中的每个格子是跟下方Instance Mask中的mask是一一对应的。由于每个格子都会预测一个实例对象,也就是会预测S^2个mask,而mask的大小为原图大小,即H x W。因此,Instance Mask的形状为H x W x S^2。
它们的对应关系是Semantic Category中第i行第j列的格子对应Instance Mask中第k维 ( k = i·S + j )的mask。