
HBase的集群是在不断扩展的,分布式系统的最大好处除了性能外,不停服横向扩展也是其中之一,扩展过程中有一个问题:每次扩展的机器的配置是不一样的,一般,后面新加入的机器性能会比老的机器好,但是后面加入的机器经常被分配很少的region,这样就造成了资源分布不均匀,随之而来的就是性能上的损失,如下:
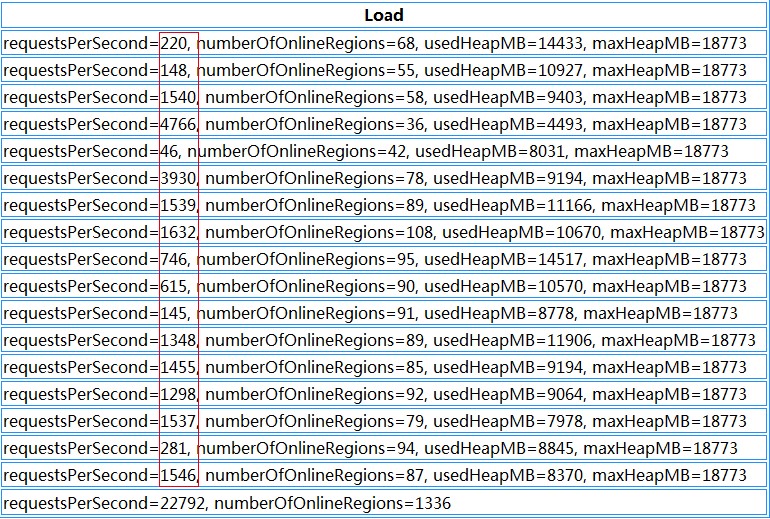
HBase各个RegionServer请求
上图中我们可以看到,每台RegionServer上的请求极为不均匀,多的好几千,少的只有几十
原因
资源分配不均匀,造成部分机器压力较大,部分机器负载较低,并且部分Region过大过热,导致请求相对较集中。
解决
迁移部分老的RegionServer上的region到新加入的机器上,使每个RegionServer的负载均匀。通过split切分部分较大region,均匀分布热点region到各个RegionServer上。
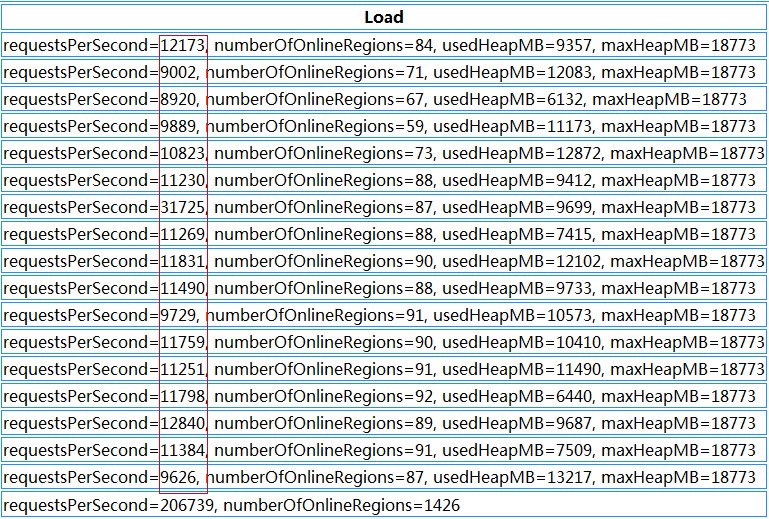
HBase region请求分布
对比前后两张截图我们可以看到,Region总数量从1336增加到了1426,而增加的这90个region就是通过split切分大的region得到的。而对region重新分布后,整个HBase的性能有了大幅度提高。
建议
Region迁移的时候不能简单开启自动balance,因为balance主要的问题是不会根据表来进行balance,HBase的自动balance只会根据每个RegionServer上的Region数量来进行balance,所以自动balance可能会造成同张表的region会被集中迁移到同一个台RegionServer上,这样就达不到分布式的效果。
基本上,新增RegionServer后的region调整,可以手工进行,尽量使表的Region都平均分配到各个RegionServer上,另外一点,新增的RegionServer机器,配置最好与前面的一致,否则资源无法更好利用。
对于过大,过热的region,可以通过切分的方法生成多个小region后均匀分布(注意:region切分会触发major compact操作,会带来较大的I/O请求,请务必在业务低峰期进行)
HDFS写入超时 现象
HBase写入缓慢,查看HBase日志,经常有慢日志如下:
WARN org.apache.hadoop.ipc.HBaseServer- (responseTooSlow): {"processingtimems":36096, "call":"multi(org.apache.hadoop.hbase.client.MultiAction@7884377e), rpc version=1, client version=29, methodsFingerPrint=1891768260", "client":"xxxx.xxx.xxx.xxxx:44367", "starttimems":1440239670790, "queuetimems":42081, "class":"HRegionServer", "responsesize":0, "method":"multi"}
并且伴有HDFS创建block异常如下:
INFO org.apache.hadoop.hdfs.DFSClient - Exception in createBlockOutputStream
org.apache.hadoop.hdfs.protocol.HdfsProtoUtil.vintPrefixed(HdfsProtoUtil.java:171)
org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.createBlockOutputStream(DFSOutputStream.java:1105)
org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.nextBlockOutputStream(DFSOutputStream.java:1039)
org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:487)
一般地,HBase客户端的写入到RegionServer下某个region的memstore后就返回,除了网络外,其他都是内存操作,应该不会有长达30多秒的延迟,外加HDFS层抛出的异常,我们怀疑很可能跟底层数据存储有关。
原因
定位到可能是HDFS层出现了问题,那就先从底层开始排查,发现该台机器上10块盘的空间利用率都已经达到100%。按理说,作为一个成熟的分布式文件系统,对于部分数据盘满的情况,应该有其应对措施。的确,HDFS本身可以设置数据盘预留空间,如果部分数据盘的预留空间小于该值时,HDFS会自动把数据写入到另外的空盘上面,那么我们这个又是什么情况?
最终通过多方面的沟通确认,发现了主要原因:我们这批机器,在上线前SA已经经过处理,每块盘默认预留100G空间,所以当通过df命令查看盘使用率为100%时,其实盘还有100G的预留空间,而HDFS层面我们配置的预留空间是50G,那么问题就来了:HDFS认为盘还有100G空间,并且多于50G的预留,所以数据可以写入本地盘,但是系统层面却禁止了该写入操作,从而导致数据写入异常。
解决
解决的方法可以让SA释放些空间出来便于数据写入。当然,最直接有效的就是把HDFS的预留空间调整至100G以上,我们也正是这样做的,通过调整后,异常不再出现,HBase层面的slow log也没有再出现。同时我们也开启了HDFS层面的balance,使数据自动在各个服务器之间保持平衡。
建议