
磁盘满了导致的问题很难预料,HDFS可能会导致部分数据写入异常,MySQL可能会出现直接宕机等等,所以最好的办法就是:不要使盘的利用率达到100%。
网络拓扑现象
通过rowkey调整,HDFS数据balance等操作后,HBase的确稳定了许多,在很长一段时间都没有出现写入缓慢问题,整体的性能也上涨了很多。但时常会隔一段时间出现些slow log,虽然对整体的性能影响不大,但性能上的抖动还是很明显。
原因
由于该问题不经常出现,对系统的诊断带来不小的麻烦,排查了HBase层和HDFS层,几乎一无所获,因为在大多数情况下,系统的吞吐量都是正常的。通过脚本收集RegionServer所在服务器的系统资源信息,也看不出问题所在,最后怀疑到系统的物理拓扑上,HBase集群的最大特点是数据量巨大,在做一些操作时,很容易把物理机的千兆网卡都吃满,这样如果网络拓扑结构存在问题,HBase的所有机器没有部署在同一个交换机上,上层交换机的进出口流量也有可能存在瓶颈。网络测试还是挺简单的,直接ping就可以,我们得到以下结果:共17台机器,只有其中一台的延迟存在问题,如下:
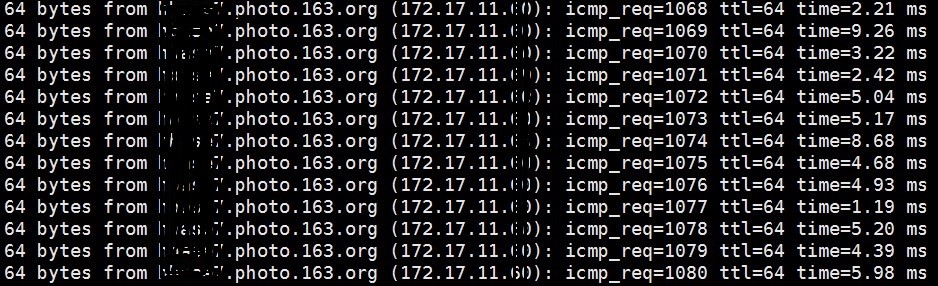
网络延迟测试:Ping结果
同一个局域网内的机器,延迟达到了毫秒级别,这个延迟是比较致命的,因为分布式存储系统HDFS本身对网络有要求,HDFS默认3副本存在不同的机器上,如果其中某台机器的网络存在问题,这样就会影响到该机器上保存副本的写入,拖慢整个HDFS的写入速度。
解决
网络问题,联系机房解决,机房的反馈也验证了我们的想法:由于HBase的机器后面进行了扩展,后面加入的机器有一台跟其他机器不在同一个交换机下,而这台机器正是我们找出的有较大ping延时这台,整个HBase物理结构如下:

HBase物理拓扑结构
跟机房协调,调整机器位置,使所有的HBase机器都位于同一个交换机下,问题迎刃而解。
建议
对于分布式大流量的系统,除了系统本身,物理机的部署和流量规划也相当重要,尽量使集群中所有的机器位于相同的交换机下(有容灾需求的应用除外),集群较大,需要跨交换机部署时,也要充分考虑交换机的出口流量是否够用,网络硬件上的瓶颈诊断起来相对更为困难。
JVM参数调整
解决了网络上面的不稳定因素,HBase的性能又得到进一步的提高,随之也带来了另外的问题。
现象
根据应用反应,HBase会阶段性出现性能下降,导致应用数据写入缓慢,造成应用端的数据堆积,这又是怎么回事?经过一系列改善后HBase的系统较之以前有了大幅度增长,怎么还会出现数据堆积的问题?为什么会阶段性出现?
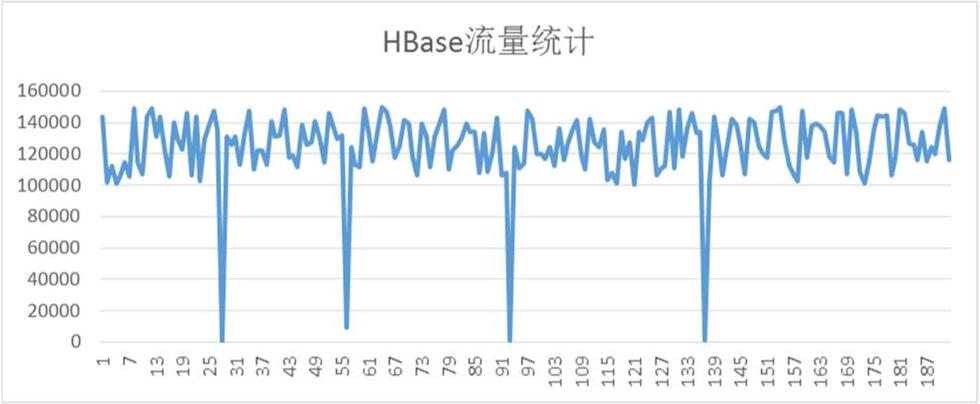
从上图看,HBase平均流量QPS基本能达到12w,但是每过一段时间,流量就会下降到接近零点,同时这段时间,应用会反应数据堆积。
原因
这个问题定位相对还是比较简单,结合HBase的日志,很容易找到问题所在:
org.apache.hadoop.hbase.util.Sleeper - We slept 41662ms instead of 3000ms, this is likely due to a long garbage collecting pause and it's usually bad
通过上述日志,基本上可以判定是HBase的某台RegionServer出现GC问题,导致了服务在很长一段时间内禁止访问。
HBase通过一系列的调整后,整个系统的吞吐量增加了好几倍,然而JVM的堆大小没有进行相应的调整,整个系统的内存需求变大,而虚拟机又来不及回收,最终导致出现Full GC
解决
GC问题导致HBase整个系统的请求下降,通过适当调整JVM参数的方式,解决HBase RegionServer的GC问题。
建议
对于HBase来说,本身不存在单点故障,即使宕掉1,2台RegionServer,也只是使剩下几台的压力有所增加,不会导致整个集群服务能力下降很多。但是,如果其中某台RegionServer出现Full GC问题,那么这台机器上所有的访问都会被挂起,客户端请求一般都是batch发送的,rowkey的随机分布导致部分请求会落到该台RegionServer上,这样该客户端的请求就会被阻塞,导致客户端无法正常写数据到HBase。所以,对于HBase来说,宕机并不可怕,但长时间的Full GC是比较致命的,配置JVM参数的时候,尽量要考虑避免Full GC的出现。
后记