
在分布式环境中,许多服务依赖项中的一些服务依赖不可避免地会失败。Hystrix是一个库,通过添加延迟容忍和容错逻辑,帮助您控制这些分布式服务之间的交互。Hystrix通过隔离服务之间的访问点、防止服务之间的级联故障以及提供回退选项来实现这一点,所有这些都提高了系统的总体弹性。
( 级联故障 )
延迟和容错
防止级联故障。回退和优雅的降级。快速恢复失败。
带断路器的线程和信号量隔离。
实时操作
实时监控和配置更改。当服务和属性变更在集群中传播时,立即生效。
保持警觉,做出决定,影响变化,并在几秒钟内看到结果。
并发性
并行执行。支持并发的请求缓存。通过请求折叠自动批处理。
服务熔断和服务降级是解决服务雪崩的手段之一,所以在了解服务熔断和服务降级前,需要先明白什么是服务雪崩。如下图所示,因评论服务的失败,导致整个服务链条的失败,即一个服务失败,导致整条链路的服务都失败的情形,我们称之为服务雪崩。
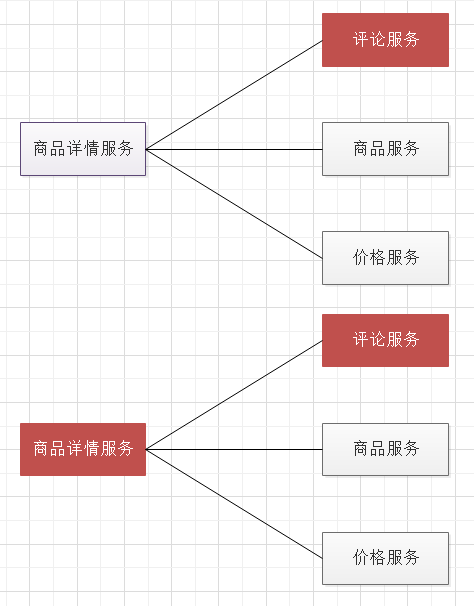
如上图所示,如果当评论服务不可用或响应过慢时,常理来说,应该等到评论服务恢复可用再来调用,可事实上是,后续每个评论服务请求,还是会等待评论服务响应,这可能会消耗商品详情服务的宝贵资源,如线程,导致资源耗尽,从而使商品详情服务无法处理其他请求。而服务熔断就是解决这个问题的。
当下游的服务因为某种原因突然变得不可用或响应过慢,上游服务为了保证自己整体服务的可用性,不再继续调用目标服务,直接返回,快速释放资源。如果目标服务情况好转则恢复调用。需要说明的是熔断其实是一个框架级的处理,而基本上业内用的是断路器模式;

注意,这时商品详情服务还是会因为评论服务请求失败报Hystrix circuit short-circuited and is OPEN异常而不可用,单纯的服务熔断只是避免重复调用不可用的评论服务而已,不要把熔断和熔断降级归为一起,后面实现可以看一些区别。
断路器背后的基本思想非常简单。在断路器对象中包装受保护的函数调用,该对象监视故障。一旦故障达到某一阈值,断路器就会跳闸,所有对断路器的进一步呼叫都会返回错误,而根本不进行受保护的呼叫。通常,如果断路器跳闸,您还需要某种监视器警报。 ---Martin Fowler
那断路器什么时候打开和关闭呢?
以Hystrix的断路器为例,每当20个请求中,有50%失败时,断路器就会打开,此时再调用此服务,将会直接返回失败,不再调远程服务。直到5s钟之后,会跳到半开模式,放一次请求进来,重新检测服务是否恢复正常,判断是否把断路器关闭,或者继续打开。
