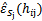K-Fold 交叉验证 (Cross-Validation)的理解与应用
我的网站
1.K-Fold 交叉验证概念在机器学习建模过程中,通行的做法通常是将数据分为训练集和测试集。测试集是与训练独立的数据,完全不参与训练,用于最终模型的评估。在训练过程中,经常会出现过拟合的问题,就是模型可以很好的匹配训练数据,却不能很好在预测训练集外的数据。如果此时就使用测试数据来调整模型参数,就相当于在训练时已知部分测试数据的信息,会影响最终评估结果的准确性。通常的做法是在训练数据再中分出一部分做为验证(Validation)数据,用来评估模型的训练效果。
验证数据取自训练数据,但不参与训练,这样可以相对客观的评估模型对于训练集之外数据的匹配程度。模型在验证数据中的评估常用的是交叉验证,又称循环验证。它将原始数据分成K组(K-Fold),将每个子集数据分别做一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型。这K个模型分别在验证集中评估结果,最后的误差MSE(Mean Squared Error)加和平均就得到交叉验证误差。交叉验证有效利用了有限的数据,并且评估结果能够尽可能接近模型在测试集上的表现,可以做为模型优化的指标使用。
2.举例说明下面举一个具体的例子来说明K-Fold的过程,比如如下的数据
[0.1, 0.2, 0.3, 0.4, 0.5, 0.6]
分为K=3组后
Fold1: [0.5, 0.2]Fold2: [0.1, 0.3]
Fold3: [0.4, 0.6]
交叉验证的时会使用如下三个模型,分别进行训练和测试,每个测试集误差MSE加和平均就得到了交叉验证的总评分
Model1: Trained on Fold1 + Fold2, Tested on Fold3Model2: Trained on Fold2 + Fold3, Tested on Fold1
Model3: Trained on Fold1 + Fold3, Tested on Fold2
3.应用讲解
1、 将全部训练集S分成k个不相交的子集,假设S中的训练样例个数为m,那么每一个子集有m/k个训练样例,相应的子集称作{
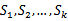
2、 每次从模型集合M中拿出来一个
![clip_image010[3]](https://images.cnblogs.com/cnblogs_com/jerrylead/201103/201103271150037665.png)
{
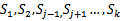
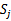
![clip_image010[4]](https://images.cnblogs.com/cnblogs_com/jerrylead/201103/201103271150051088.png)
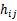
![clip_image028[1]](https://images.cnblogs.com/cnblogs_com/jerrylead/201103/201103271150062908.png)