
要想让 MyBatis 跑起来,还需要进行一些配置。比如配置数据源、配置 SQL 映射文件的位置信息等。本节所使用到的配置如下:
<configuration> <properties resource="jdbc.properties"/> <environments default="development"> <environment> <transactionManager type="JDBC"/> <dataSource type="POOLED"> <property value="${jdbc.driver}"/> <property value="${jdbc.url}"/> <property value="${jdbc.username}"/> <property value="${jdbc.password}"/> </dataSource> </environment> </environments> <mappers> <mapper resource="mapper/ArticleMapper.xml"/> </mappers> </configuration>到此,MyBatis 所需的环境就配置好了。接下来把 MyBatis 跑起来吧,相关测试代码如下:
public class MyBatisTest { private SqlSessionFactory sqlSessionFactory; @Before public void prepare() throws IOException { String resource = "mybatis-config.xml"; InputStream inputStream = Resources.getResourceAsStream(resource); sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream); inputStream.close(); } @Test public void testMyBatis() throws IOException { SqlSession session = sqlSessionFactory.openSession(); try { ArticleDao articleDao = session.getMapper(ArticleDao.class); List<Article> articles = articleDao.findByAuthorAndCreateTime("coolblog.xyz", "2018-06-10"); } finally { session.commit(); session.close(); } } }在上面的测试代码中,prepare 方法用于创建SqlSessionFactory工厂,该工厂的用途是创建SqlSession。通过 SqlSession,可为我们的数据库访问接口ArticleDao接口生成一个代理对象。MyBatis 会将接口方法findByAuthorAndCreateTime和 SQL 映射文件中配置的 SQL 关联起来,这样调用该方法等同于执行相关的 SQL。
上面的测试代码运行结果如下:

如上,大家在学习 MyBatis 框架时,可以配置一下 MyBatis 的日志,这样可把 MyBatis 的调试信息打印出来,方便观察 SQL 的执行过程。在上面的结果中,==>符号所在的行表示向数据库中输入的 SQL 及相关参数。<==符号所在的行则是表示 SQL 的执行结果。上面输入输出不难看懂,这里就不多说了。
关于 MyBatis 的优缺点,这里先不进行总结。后面演示其他的框架时再进行比较说明。
演示完 MyBatis,下面,我们来看看通过原始的 JDBC 直接访问数据库过程是怎样的。
3.2 使用 JDBC 访问数据库 3.2.1 JDBC 访问数据库的过程演示在初学 Java 编程阶段,多数朋友应该都是通过直接写 JDBC 代码访问数据库。我这么说,大家应该没异议吧。这种方式的代码流程一般是加载数据库驱动,创建数据库连接对象,创建 SQL 执行语句对象,执行 SQL 和处理结果集等,过程比较固定。下面我们再手写一遍 JDBC 代码,回忆一下初学 Java 的场景。
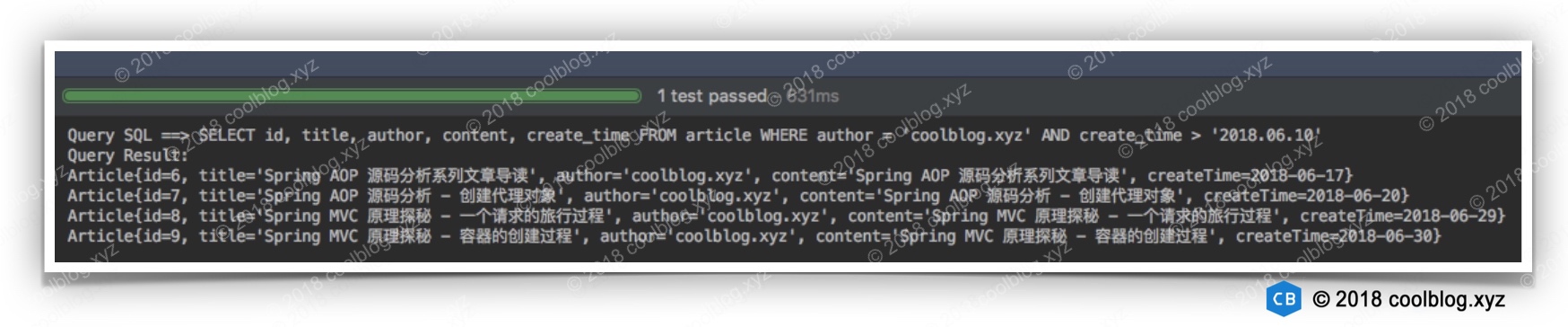
public class JdbcTest { @Test public void testJdbc() { String url = "jdbc:mysql://localhost:3306/myblog?user=root&password=1234&useUnicode=true&characterEncoding=UTF8&useSSL=false"; Connection conn = null; try { Class.forName("com.mysql.cj.jdbc.Driver"); conn = DriverManager.getConnection(url); String author = "coolblog.xyz"; String date = "2018.06.10"; String sql = "SELECT id, title, author, content, create_time FROM article WHERE author = '" + author + "' AND create_time > '" + date + "'"; Statement stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery(sql); List<Article> articles = new ArrayList<>(rs.getRow()); while (rs.next()) { Article article = new Article(); article.setId(rs.getInt("id")); article.setTitle(rs.getString("title")); article.setAuthor(rs.getString("author")); article.setContent(rs.getString("content")); article.setCreateTime(rs.getDate("create_time")); articles.add(article); } System.out.println("Query SQL ==> " + sql); System.out.println("Query Result: "); articles.forEach(System.out::println); } catch (ClassNotFoundException e) { e.printStackTrace(); } catch (SQLException e) { e.printStackTrace(); } finally { try { conn.close(); } catch (SQLException e) { e.printStackTrace(); } } } }代码比较简单,就不多说了。下面来看一下测试结果:
上面代码的步骤比较多,但核心步骤只有两部,分别是执行 SQL 和处理查询结果。从开发人员的角度来说,我们也只关心这两个步骤。如果每次为了执行某个 SQL 都要写很多额外的代码。比如打开驱动,创建数据库连接,就显得很繁琐了。当然我们可以将这些额外的步骤封装起来,这样每次调用封装好的方法即可。这样确实可以解决代码繁琐,冗余的问题。不过,使用 JDBC 并非仅会导致代码繁琐,冗余的问题。在上面的代码中,我们通过字符串对 SQL 进行拼接。这样做会导致两个问题,第一是拼接 SQL 可能会导致 SQL 出错,比如少了个逗号或者多了个单引号等。第二是将 SQL 写在代码中,如果要改动 SQL,就需要到代码中进行更改。这样做是不合适的,因为改动 Java 代码就需要重新编译 Java 文件,然后再打包发布。同时,将 SQL 和 Java 代码混在一起,会降低代码的可读性,不利于维护。关于拼接 SQL,是有相应的处理方法。比如可以使用 PreparedStatement,同时还可解决 SQL 注入的问题。