
但去除一些获取节点属性的代码, 去除一些反射的代码。 其流程可以用下图表示
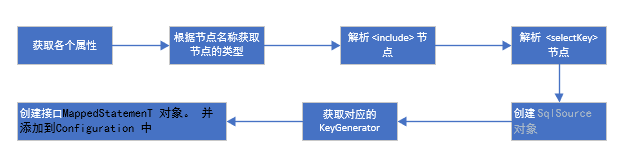
在其他的内容解析之前, 会先解析 <incliude>节点, 用对应 id 的重用 SQL 语句将该节点替换掉。
先看看约束的定义
<!ELEMENT include (property+)?> <!ATTLIST include refid CDATA #REQUIRED >可以看出, <incliude> 节点中可以包含有 property 一个或多个, 必须包含有 refid。 refid 是对应 <sql> 节点的 id。
2.1 解析流程解析时, 通过 XMLIncludeTransformer.applyIncludes 方法进行解析。
/** * 从 parseStatementNode 方法进入时, Node 还是 (select|insert|update|delete) 节点 */ public void applyIncludes(Node source) { Properties variablesContext = new Properties(); // 获取的是 mybatis-config.xml 所定义的属性 Properties configurationVariables = configuration.getVariables(); if (configurationVariables != null) { variablesContext.putAll(configurationVariables); } // 处理 <include> 子节点 applyIncludes(source, variablesContext, false); }获取 Coniguration.variables 中的所有属性, 这些属性后续在将 ${XXX} 替换成真实的参数时会用到。 然后递归解析所有的 include 节点。 具体的实现过程如下:
/** * Recursively apply includes through all SQL fragments. * 递归的包含所有的 SQL 节点 * * @param source Include node in DOM tree * @param variablesContext Current context for static variables with values */ private void applyIncludes(Node source, final Properties variablesContext, boolean included) { // 下面是处理 include 子节点 if (source.getNodeName().equals("include")) { // 查找 refid 属性指向 <sql> 节点 Node toInclude = findSqlFragment(getStringAttribute(source, "refid"), variablesContext); // 解析 <include> 节点下的 <property> 节点, 将得到的键值对添加到 variablesContext 中 // 并形成 Properties 对象返回, 用于替换占位符 Properties toIncludeContext = getVariablesContext(source, variablesContext); // 递归处理 <include> 节点, 在 <sql> 节点中可能会 <include> 其他 SQL 片段 applyIncludes(toInclude, toIncludeContext, true); if (toInclude.getOwnerDocument() != source.getOwnerDocument()) { toInclude = source.getOwnerDocument().importNode(toInclude, true); } // 将 <include> 节点替换成 <sql> source.getParentNode().replaceChild(toInclude, source); while (toInclude.hasChildNodes()) { toInclude.getParentNode().insertBefore(toInclude.getFirstChild(), toInclude); } toInclude.getParentNode().removeChild(toInclude); } else if (source.getNodeType() == Node.ELEMENT_NODE) { if (included && !variablesContext.isEmpty()) { // replace variables in attribute values // 获取所有的属性值, 并使用 variablesContext 进行占位符的解析 NamedNodeMap attributes = source.getAttributes(); for (int i = 0; i < attributes.getLength(); i++) { Node attr = attributes.item(i); attr.setNodeValue(PropertyParser.parse(attr.getNodeValue(), variablesContext)); } } // 获取所有的子类, 并递归解析 NodeList children = source.getChildNodes(); for (int i = 0; i < children.getLength(); i++) { applyIncludes(children.item(i), variablesContext, included); } } else if (included && source.getNodeType() == Node.TEXT_NODE && !variablesContext.isEmpty()) { // replace variables in text node // 使用 variablesContext 进行占位符的解析 source.setNodeValue(PropertyParser.parse(source.getNodeValue(), variablesContext)); } }它分三种节点进行解析
include
Node.ELEMENT_NODE
Node.TEXT_NODE
2.2 <include> 节点的解析这个是节点为 <include> 时才进行解析的, 其解析的流程大体如下
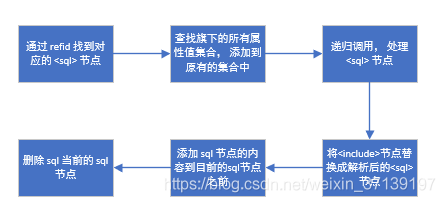
什么时候回出现这种情况呢? 节点是非 <include> 的 Node.ELEMENT_NODE 类型的节点时, 如 sql 节点, (select | insert | update | delete) 节点的时候。 这些节点的特点就是都有可能含有 <include> 节点。
这个的流程很简单, 就是递归调用解析所有的 <include> 子节点。
// 获取所有的子类, 并递归解析 NodeList children = source.getChildNodes(); for (int i = 0; i < children.getLength(); i++) { applyIncludes(children.item(i), variablesContext, included); } 2.4 Node.TEXT_NODENode.TEXT_NODE 就是文本节点, 当时该类型的节点时, 就会使用 PropertyParser.parse 方法来进行解析。 其大体就是将 ${xxx} 替换成相应的值。
由于有 included 条件的现在, 其只有是在 include 所包含的子节点时才会如此。
举例