
现在,让我们开始使用带有默认参数的应用程序。只需点击开始按钮,学习就开始了。完成后,您将能够单击Show Solution按钮,学习路径将从头到尾播放。
点击Start开始学习阶段,一直到黑色物体达到目标:
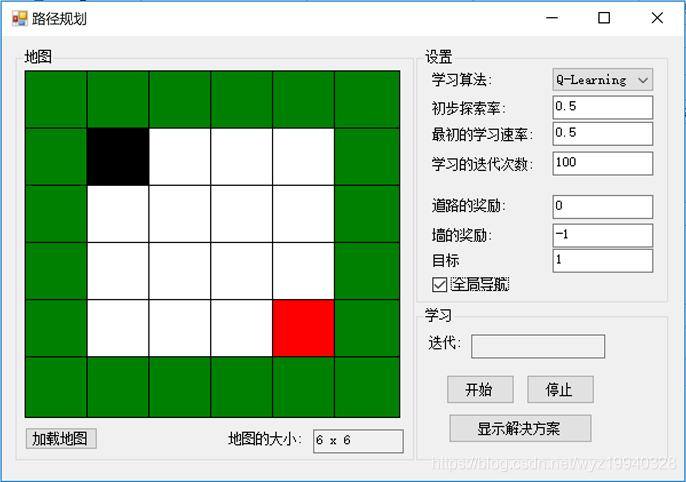
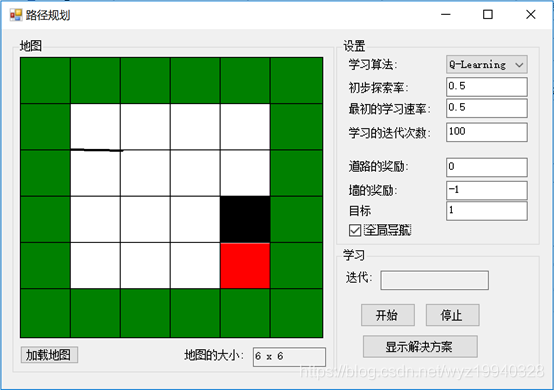
对于每个迭代,将评估不同的对象位置,以及它们的操作和奖励。一旦学习完成,我们可以单击Show Solution按钮来重播最终的解决方案。完成后,黑色对象将位于红色对象之上:
现在让我们看看应用程序中的代码。有两种我们之前强调过的学习方法。
Q-learning是这样的:
/// <summary> /// Q-Learning 线程 /// </summary> private void QLearningThread() { //迭代次数 int iteration = 0; TabuSearchExploration tabuPolicy = (TabuSearchExploration)qLearning.ExplorationPolicy; EpsilonGreedyExploration explorationPolicy = (EpsilonGreedyExploration)tabuPolicy.BasePolicy; while ((!needToStop)&&(iteration<learningIterations)) { explorationPolicy.Epsilon = explorationRate - ((double)iteration / learningIterations) * explorationRate; qLearning.LearningRate = learningRate - ((double)iteration / learningIterations) * learningRate; tabuPolicy.ResetTabuList(); var agentCurrentX = agentStartX; var agentCurrentY = agentStartY; int steps = 0; while ((!needToStop)&& ((agentCurrentX != agentStopX) || (agentCurrentY != agentStopY))) { steps++; int currentState= GetStateNumber(agentCurrentX, agentCurrentY); int action = qLearning.GetAction(currentState); double reward = UpdateAgentPosition(ref agentCurrentX, ref agentCurrentY, action); int nextState = GetStateNumber(agentCurrentX, agentCurrentY); // 更新对象的qLearning以设置禁忌行为 qLearning.UpdateState(currentState, action, reward, nextState); tabuPolicy.SetTabuAction((action + 2) % 4, 1); } System.Diagnostics.Debug.WriteLine(steps); iteration++; SetText(iterationBox, iteration.ToString()); } EnableControls(true); }