
强化学习概况
正如在前面所提到的,强化学习是指一种计算机以“试错”的方式进行学习,通过与环境进行交互获得的奖赏指导行为,目标是使程序获得最大的奖赏,强化学习不同于连督学习,区别主要表现在强化信号上,强化学习中由环境提供的强化信号是对产生动作的好坏作一种评价(通常为标量信号),而不是告诉强化学习系统如何去产生正确的动作。唯一的目的是最大化效率和/或性能。算法对正确的决策给予奖励,对错误的决策给予惩罚,如下图所示:
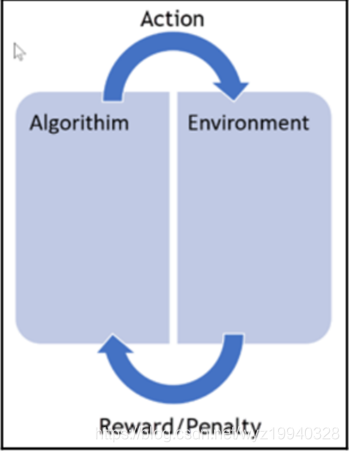
持续的训练是为了不断提高效率。这里的重点是性能,这意味着我们需要,在看不见的数据和算法已经学过的东西,之间找到一种平衡。该算法将一个操作应用到它的环境中,根据它所做的行为接受奖励或惩罚,不断的重复这个过程,等等。
接下来让我们看一个程序,概念是相似的,尽管它的规模和复杂性很低。想象一下,是什么让自动驾驶的车辆从一个地点移动到了另一个点。
让我们看看我们的应用程序:
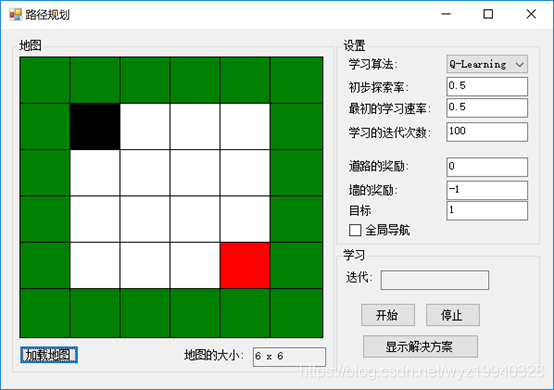
在这里,可以看到我们有一个非常基本的地图,一个没有障碍,但有外部限制的墙。黑色块(start)是我们的对象,红色块(stop)是我们的目标。在这个应用程序中,我们的目标是让我们的对象在墙壁以内到达目标位置。如果我们的下一步把我们的对象放在一个白色的方块上,我们的算法将得到奖励。如果我们的下一步行动超出墙壁的围地范围,我们将受到惩罚。在这个例子中,它的路径上绝对没有障碍,所以我们的对象应该能够到达它的目的地。问题是:它能多快学会?
下面是另一个比较复杂的地图示例:
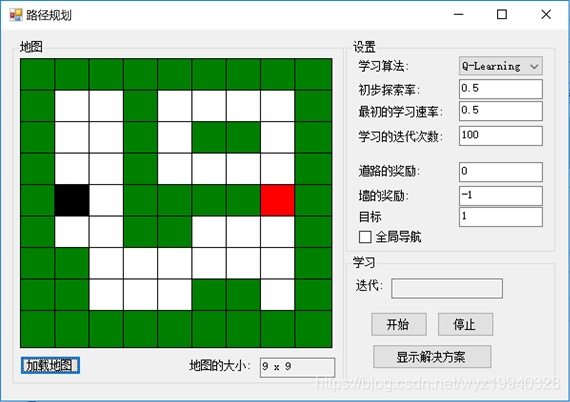
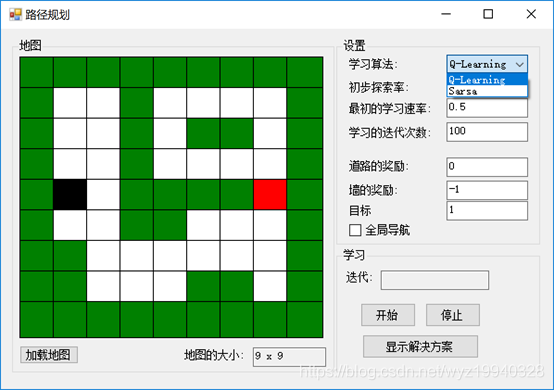
在应用程序的右边是我们的设置,如下面的屏幕截图所示。我们首先看到的是学习算法。在这个应用中,我们将处理两种不同的学习算法,Q-learning和state-action-reward-state-action (SARSA)。让我们简要讨论一下这两种算法。
Q-learning可以在没有完全定义的环境模型的情况下,识别给定状态下的最优行为(在每个状态中值最高的行为)。它还擅长处理随机转换和奖励的问题,而不需要调整或适应。
以下是Q-learning的数学表达式:
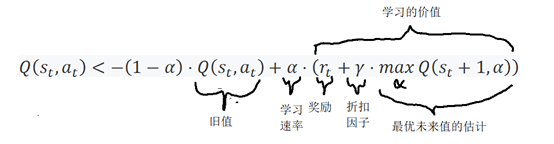
如果我们提供一个非常高级的抽象示例,可能更容易理解。
程序从状态1开始。然后它执行动作1并获得奖励1。接下来,它四处寻找状态2中某个行为的最大可能奖励是多少;然后使用它来更新动作1的值等等。
SARSA
SARSA的工作原理是这样的:
1. 程序从状态1开始。
2. 然后它执行动作1并获得奖励1。
3. 接下来,它进入状态2,执行动作2,并获得奖励2。
4. 然后,程序返回并更新动作1的值。
这Q-learning算法的不同之处在于找到未来奖励的方式。
Q-learning使用状态2中奖励最高的动作的值,而SARSA使用实际动作的值。
这是SARSA的数学表达式:
运行我们的应用程序