
先说个小事情,今天试了下做动图,就一张动图都花了我 1 个小时,还做得很难看。。
本文主要内容如下:
上一篇讲到如何做性能调优的方法,比如给表加索引、动静分离、减少不必要的日志打印。但有一个很强大的优化方式没有提到,那就是加缓存,比如查询小程序的广告位配置,因为没什么人会去频繁的改,将广告位配置丢到缓存里面再适合不过了。那我们就给开源 Spring Cloud 实战项目 PassJava 加下缓存来提升下性能。
我把后端、前端、小程序都上传到同一个仓库里面了,大家可以通过 github 或 码云访问。地址如下:
Github: https://github.com/Jackson0714/PassJava-Platform
码云:https://gitee.com/jayh2018/PassJava-Platform
配套教程:
在实战之前,我们先来看下使用缓存的原理和问题。
一、缓存 1.1 为什么要用缓存20 年前常见的系统就是单机的,比如 ERP 系统,对性能要求不高,使用缓存的并不常见,但现如今,已经步入到互联网时代,高并发、高可用、高性能总是被提起,而缓存在这“三高”中立下汗马功劳。
我们通过会将部分数据放入缓存中,来提高访问速度,然后数据库承担存储的工作。
那么哪些数据适合放入缓存中呢?
即时性。例如查询最新的物流状态信息。
数据一致性要求不高。例如门店信息,修改后,数据库中已经改了,5 分钟后缓存中才是最新的,但不影响功能使用。
访问量大且更新频率不高。比如首页的广告信息,访问量,但是不会经常变化。
当我们想要查询数据时,使用缓存的流程如下:
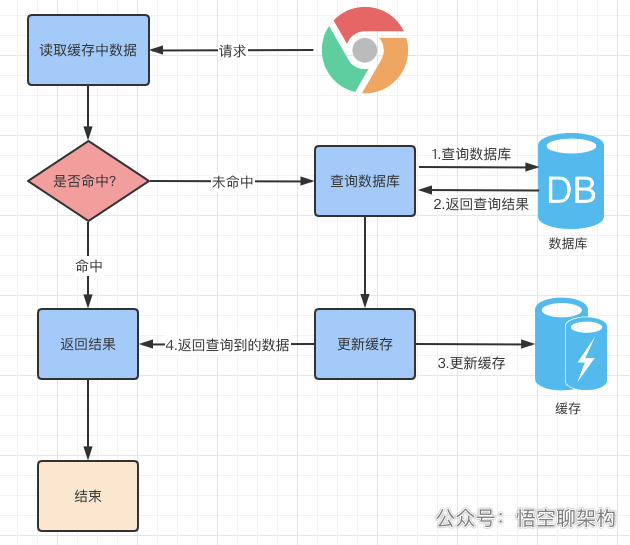
最简单的使用缓存的方式就是用本地缓存。
比如现在有一个需求,前端小程序需要查询题目的类型,而题目类型放在小程序的首页在,访问量是非常高的,但是又不是经常变化的数据,所以可以将题目类型数据放到缓存中。

最简单的使用缓存的方式是使用本地缓存,也就是在内存中缓存数据,可以用 HashMap、数组等数据结构来缓存数据。
1.2.1 不使用缓存我们先来看下不使用缓存的情况:前端的请求先经过网关,然后请求到题目微服务,然后查询数据库,返回查询结果。
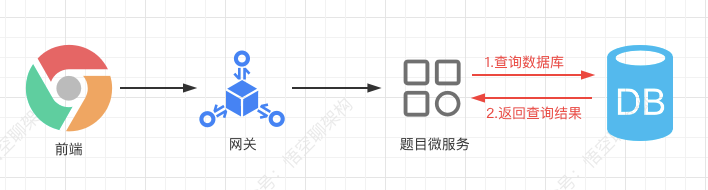
再来看下核心代码是怎么样的。
先自定义一个 Rest API 用来查询题目类型列表,数据是从数据库查询出来后直接返回给前端。
@RequestMapping("/list") public R list(){ // 从数据库中查询数据 typeEntityList = ITypeService.list(); return R.ok().put("typeEntityList", typeEntityList); } 1.2.2 使用缓存来看下使用缓存的情况:前端先经过网关,然后到题目微服务,先判断缓存中有没有数据,如果没有,则查询数据库再更新缓存,最后返回查询到的结果。
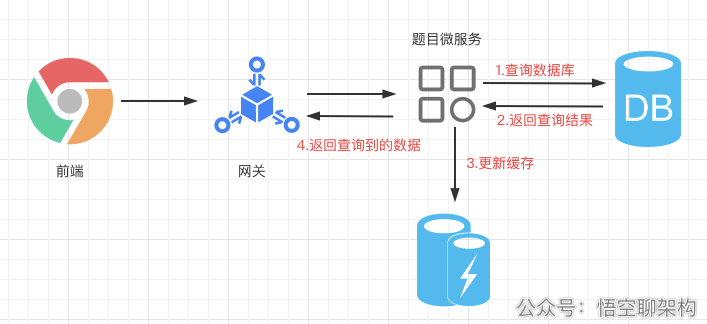
那我们现在创建一个 HashMap 来缓存题目的类型列表:
private Map<String, Object> cache = new HashMap<>();先获取缓存的类型列表
List<TypeEntity> typeEntityListCache = (List<TypeEntity>) cache.get("typeEntityList");如果缓存中没有,则先从数据库中获取。当然,第一次查询缓存时,肯定是没有这个数据的。
// 如果缓存中没有数据 if (typeEntityListCache == null) { System.out.println("The cache is empty"); // 从数据库中查询数据 List<TypeEntity> typeEntityList = ITypeService.list(); // 将数据放入缓存中 typeEntityListCache = typeEntityList; cache.put("typeEntityList", typeEntityList); } return R.ok().put("typeEntityList", typeEntityListCache);我们用 Postman 工具来看下查询结果:
请求URL:https://github.com/Jackson0714/PassJava-Platform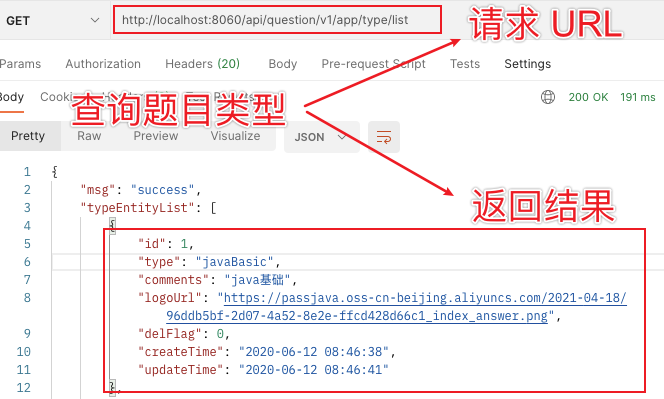
返回了题目类型列表,共 14 条数据。
以后再次查询时,因为缓存中已经有该数据了,所以直接走缓存,不会再从数据库中查询数据了。
从上面的例子中我们可以知道本地缓存有哪些优点呢?
减少和数据库的交互,降低因磁盘 I/O 引起的性能问题。
避免数据库的死锁问题。
加速相应速度。
当然,本地缓存也存在一些问题:
占用本地内存资源。
机器宕机重启后,缓存丢失。
可能会存在数据库数据和缓存数据不一致的问题。
同一台机器中的多个微服务缓存的数据不一致。
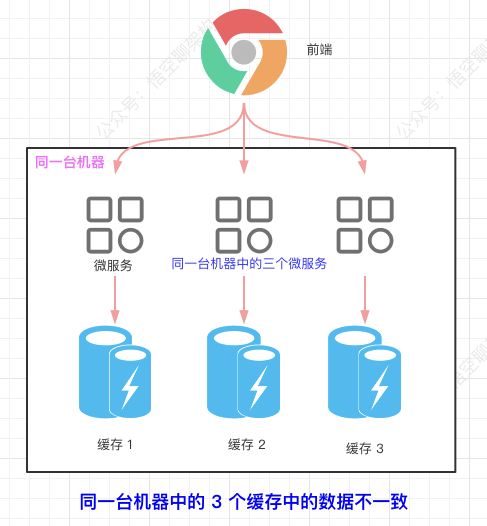
集群环境下存在缓存的数据不一致的问题。

基于本地缓存的问题,我们引入了分布式缓存 Redis 来解决。
二、缓存 Redis 2.1 Docker 安装 Redis首先需要安装 Redis,我是通过 Docker 来安装 Redis。另外我在 ubuntu 和 Mac M1 上都装过 docker 版的 Redis,大家可以参照这两篇来安装。
《Ubuntu 上到 Docker 安装redis》
《M1 运行 Docker》
2.2 引入 Redis 组件我用的是 passjava-question 微服务,所以是在 passjava-question 模块下的配置文件 pom.xml 中引入 redis 组件。