首先,创建一个Kubernetes volume,预定义大小为3Gi。其次,将image变量指定为我们将要使用的alpine/git Docker镜像。之后是在Docker容器中执行的命令列表。这些命令实质上是设置SSH密钥的,以便于流水线可以从私有仓库git clone,或者使用git://URL来代替 https://。
该函数的核心是下面一行,返回一个dsl.ContainerOp。
command和arguments指定了执行镜像之后需要执行的命令。
最后一个变量十分有趣,是pvolumes,它是Pipeline Volumes简称。它创建一个Kubernetes volume并允许流水线组件来共享单个存储。该volume被挂载在/workspace上。那么这个组件要做的就是把仓库git clone到/workspace中。
使用Secrets再次查看命令和复制SSH密钥的位置。
流水线volume在哪里创建呢?当我们将所有组件都整合到一个流水线中时,就会看到创建好的volume。我们在/etc/ssh-key/上安装secrets:
op.add_volume_mount(V1VolumeMount(mount_path='/etc/ssh-key',, read_only=True))请记得我们将secret命名为ssh-key-secret:
op.add_volume(V1Volume(name='ssh-key-volume', secret=V1SecretVolumeSource(secret_name='ssh-key-secret')))通过使用相同的volume名称ssh-key-volume,我们可以把一切绑定在一起。
Step2:预处理 def preprocess_op(image: str, pvolume: PipelineVolume, data_dir: str): return dsl.ContainerOp(, image=image, command=[CONDA_PYTHON_CMD, f"{PROJECT_ROOT}/preprocessing.py"], arguments=["--data_dir", data_dir], container_kwargs={'image_pull_policy': 'IfNotPresent'}, pvolumes={"/workspace": pvolume} )正如你所看到的, 预处理步骤看起来十分相似。
image指向我们在Step0中创建的Docker镜像。
这里的command使用指定的conda python简单地执行了preprocessing.py脚本。变量data_dir被用于执行preprocessing.py脚本。
在这一步骤中pvolume将在/workspace里有仓库,这意味着我们所有的脚本在这一阶段都是可用的。并且在这一步中预处理数据会存储在/workspace下的data_dir中。
Step3:训练和评估 def train_and_eval_op(image: str, pvolume: PipelineVolume, data_dir: str, ): return dsl.ContainerOp(, image=image, command=[CONDA_PYTHON_CMD, f"{PROJECT_ROOT}/train.py"], arguments=["--data_dir", data_dir], file_outputs={'output': f'{PROJECT_ROOT}/output.txt'}, container_kwargs={'image_pull_policy': 'IfNotPresent'}, pvolumes={"/workspace": pvolume} )最后,是时候进行训练和评估这一步骤。这一步唯一的区别在于file_outputs变量。如果我们再次查看train.py,则有以下代码段:
with open(os.path.join(PROJECT_ROOT, 'output.txt'), 'w') as f: f.write(model_path) print(f'Model written to: {model_path}')我们正在将模型路径写入名为output.txt的文本文件中。通常,可以将其发送到下一个流水线组件,在这种情况下,该参数将包含模型的路径。
将一切放在一起要指定流水线,你需要使用dsl.pipeline来注释流水线功能:
@dsl.pipeline(, description='Fashion MNIST Training Pipeline to be executed on KubeFlow.' ) def training_pipeline(image: str = 'benjamintanweihao/kubeflow-mnist', repo_url: str = 'https://github.com/benjamintanweihao/kubeflow-mnist.git', data_dir: str = '/workspace'): git_clone = git_clone_darkrai_op(repo_url=repo_url) preprocess_data = preprocess_op(image=image, pvolume=git_clone.pvolume, data_dir=data_dir) _training_and_eval = train_and_eval_op(image=image, pvolume=preprocess_data.pvolume, data_dir=data_dir) if __name__ == '__main__': import kfp.compiler as compiler compiler.Compiler().compile(training_pipeline, __file__ + '.tar.gz')还记得流水线组件的输出是另一个组件的输入吗?在这里,git clone、container_op的pvolume将传递到preprocess_cp。
最后一部分将pipeline.py转换为可执行脚本。最后一步是编译流水线:
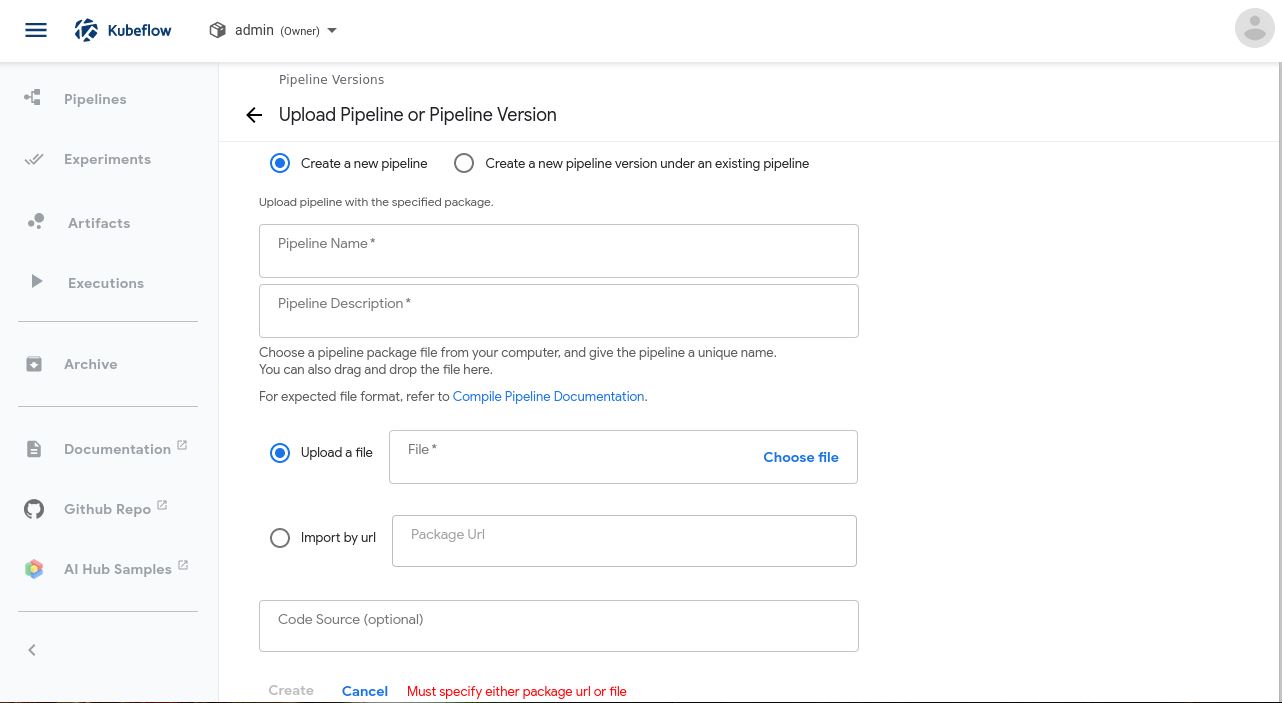
% dsl-compile --py pipeline.py --output pipeline.tar.gz 上传并执行流水线现在要进行最有趣的部分啦!第一步,上传流水线。点击Upload a pipeline:
接下来,填写Pipeline Name和Pipeline Description,然后选择Choose file并且指向pipeline.tar.gz以上传流水线。