
下一页将会展示完整的流水线。我们所看到的是一个流水线的有向无环图,在本例中这意味着依赖项会通往一个方向并且它不包含循环。点击蓝色按钮Create run 以开始训练。
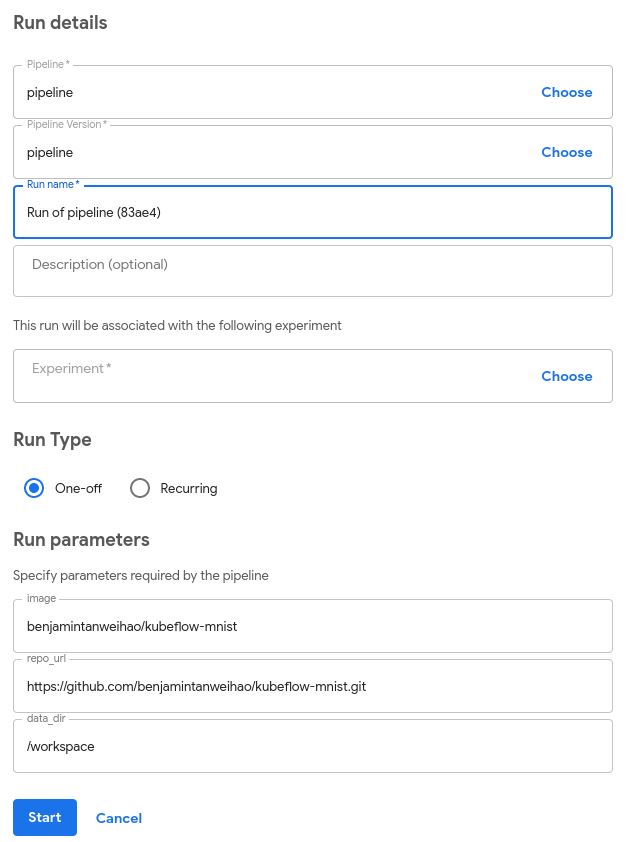
大部分字段已经已经填写完毕。请注意,Run parameters与使用@ dsl.pipeline注释的training_pipeline函数中指定的参数相同:
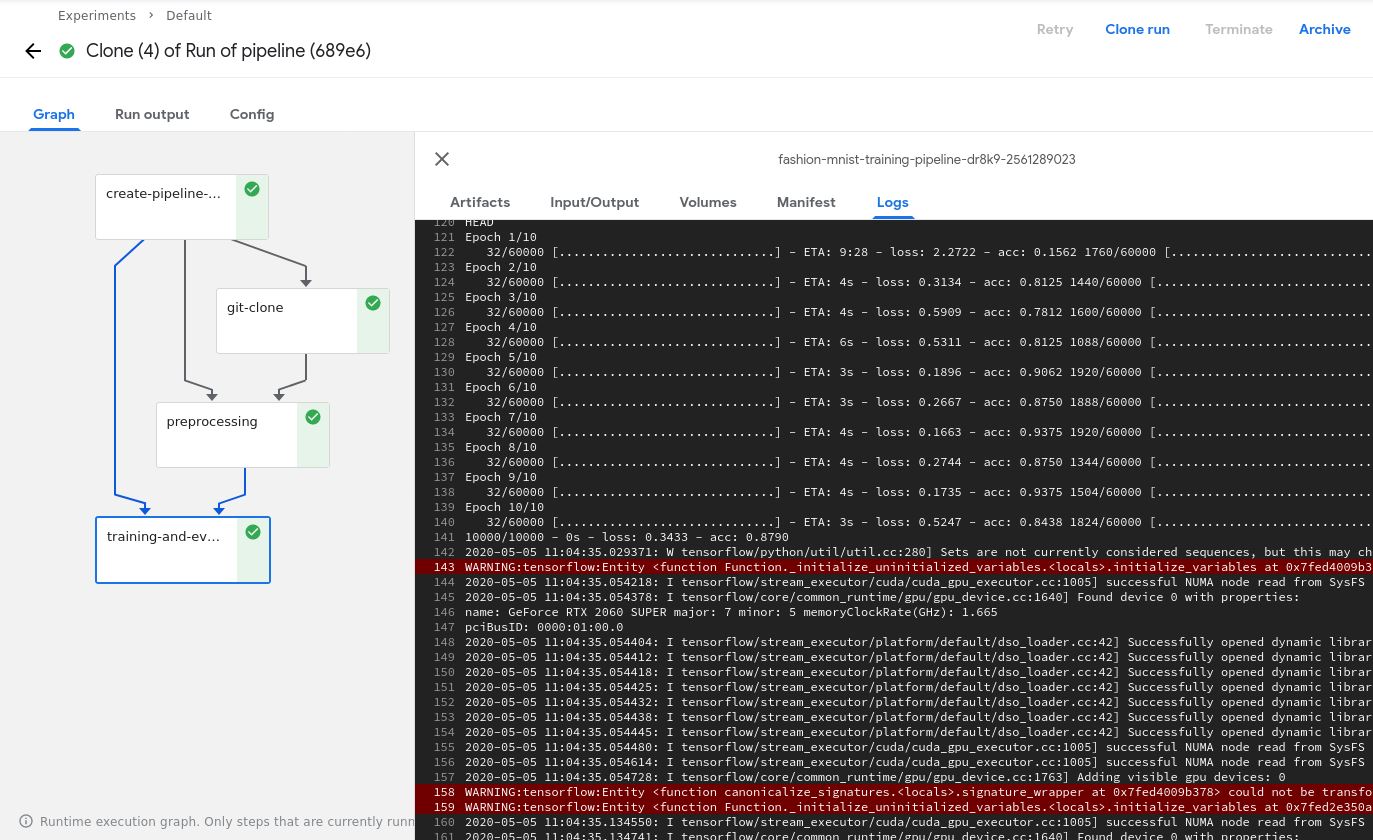
最后,当你点击蓝色的Start按钮时,整个流水线就开始运转了!你点击每个组件并查看日志就能够知道发生了什么。当整个流水线执行完毕时,在所有组件的右方会有一个绿色的确认标志,如下所示:
如果你从上一篇文章开始就一直在关注,那么你应该已经安装了Kubeflow,并且应该能体会到大规模管理机器学习项目的复杂性。
在这篇文章中,我们先介绍了为Kubeflow准备一个机器学习项目的过程,然后是构建一个Kubeflow流水线,最后是使用Kubeflow接口上传并执行流水线。这种方法的奇妙之处在于,你的机器学习项目可以是简单的,也可以是复杂的,只要你愿意,你就可以使用相同的技术。
因为Kubeflow使用Docker容器作为组件,你可以自由地加入任何你喜欢的工具。而且由于Kubeflow运行在Kubernetes上,你可以让Kubernetes处理机器学习工作负载的调度。
我们还了解了一个我喜欢的Rancher功能,它十分方便,可以轻松添加secrets。立刻,你就可以轻松地组织secrets(如SSH密钥),并选择将其分配到哪个命名空间,而无需为Base64编码而烦恼。就像Rancher的应用商店一样,这些便利性使Kubernetes的工作更加愉快,更不容易出错。
当然,Rancher提供的服务远不止这些,我鼓励你自己去做一些探索。我相信你会偶然发现一些让你大吃一惊的功能。Rancher作为一个开源的企业级Kubernetes管理平台,Run Kubernetes Everywhere一直是我们的愿景和宗旨。开源和无厂商锁定的特性,可以让用户轻松地在不同的基础设施部署和使用Rancher。此外,Rancher极简的操作体验也可以让用户在不同的场景中利用Rancher提升效率,帮助开发人员专注于创新,而无需在繁琐的小事中浪费精力。