
表的数量过多,直接影响数据字典大小,进而影响数据库整体效率。从MySQL来看,还需考虑文件句柄等问题。这一指标没有一定之规,需根据情况酌情考虑。这里更多是数据架构层面考虑,避免单库数据表过多。曾经历过单库10万张表,性能低下;优化后整合成2万张的优化案例。如选择MySQL,建议单库不超过5000张表;库*表的总数不超过20000。
2)表(大表)控制单表的规模,是设计的要点之一,直接影响到访问性能。表过大,应考虑采用上面的原则进行拆分。表大小没有通用原则,这里可通过参数进行配置。可按照物理大小或记录数两个维度设置。这里的关键点在于表的访问方式,如均为简单的kv型访问,规模大些还好;如访问比较复杂,则建议阈值设置更低些。如选择MySQL,大表复杂查询或多表关联等均不是其擅长场景,可考虑使用ES、solr+hbase等方式异步处理复杂查询。
3)表(分区表)从9i、10g以来,Oracle的分区功能日趋完善、功能增强。可以说已成为Oracle应对海量数据的利器。但对于MySQL来说,仍然不太建议使用分区功能。一方面,随着硬件能力的增强,单表可承载力变大;另一方面,MySQL使用分区还需面对“DDL放大”、“锁变化”等问题。如果团队可以很好地驾驭数据库中间层,还是建议使用复杂度更低的分表技术。这也许会稍许增加研发量,但对运维来说,好处多多。
4)字段(大对象)在任何数据库中,都不建议使用大对象。如果你用了,趁着改造工作,赶紧去掉吧。大对象功能对数据库来说,就是鸡肋。数据库自身的ACID能力,应着力保存更为重要的数据。
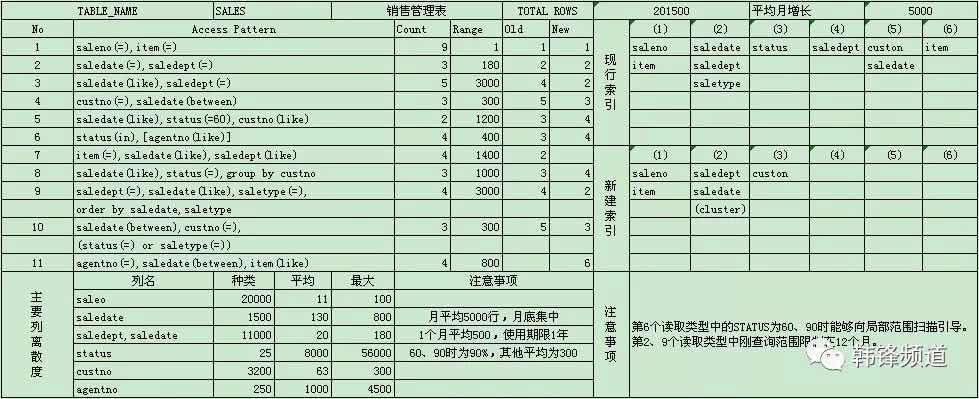
索引过多会影响DML效率、占用大量空间。可通过“索引/表”,大致反应出索引数量的合理程度。这里没有建议的数值,可根据情况酌情考虑。对于任何数据库来说,都有类似的问题,就是如何“构建战略性索引策略”。这里可参考下表(选自李华植-《海量数据库解决方案》一书),梳理索引需求。科学地创建、维护索引。
6)索引(其他)Oracle除了通常的B+树索引外,还支持其他类型的索引。如选择其他数据库,那么这些索引都需要改造,通过其他方式实现。
7)视图视图,作为SQL语句的逻辑封装,在某些场景下(如安全)很有意义。不过它对于优化器有较高要求,Oracle在这方面做了很多工作(可参看作者写的《SQL优化最佳实践》一书)。而对于MySQL,则不建议使用,考虑改造。
8)触发器/存储过程/函数对于数据库来说,承载了计算、存储两类能力。作为整个基础架构部分最难扩展的组件,尽量发挥数据库的核心能力很重要。相较于存储能力而言,计算能力是可通过应用层解决,而应用层又是往往容易扩展的。此外,考虑到未来的可维护性、可迁移性等因素,这部分考虑在应用端解决吧。

Oracle中的序列,可提供递增的、非连续保障序号服务。在MySQL中有类似的实现,是通过自增属性来完成。这部分应该可以做迁移,但如果并发量非常大;亦可考虑使用发号器的解决方案。
10)同义词同义词是数据耦合的表现,无论在什么数据库,都应该摒弃掉。应考虑在业务端进行拆分,不再依赖于这种特性。
3.4 访问特征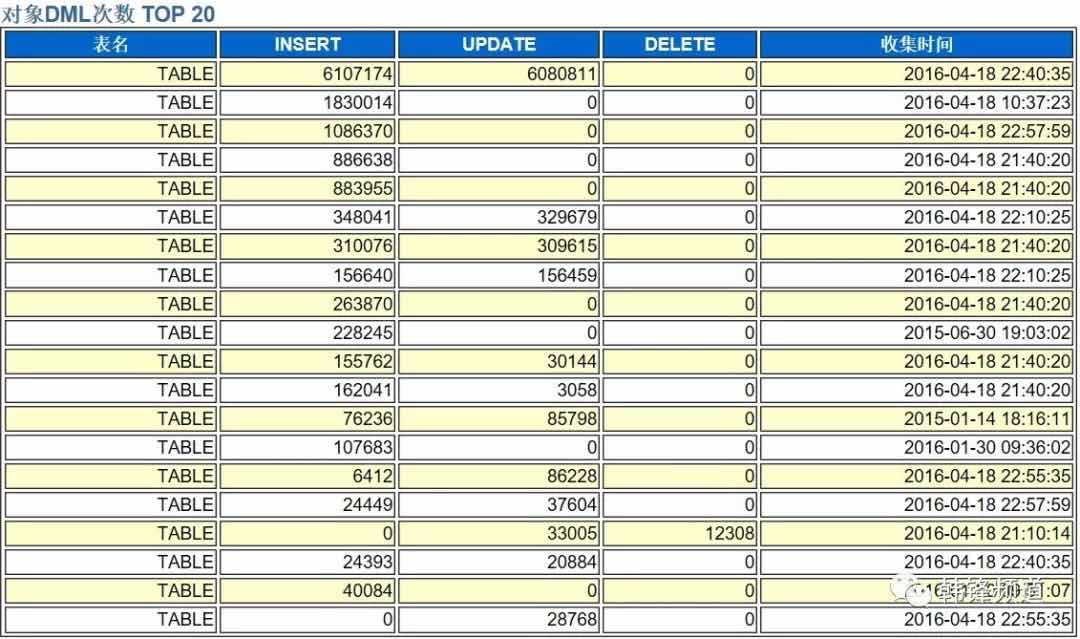
这里收集了,在过去的24小时内数据库中DML次数最多的Top20。这直接地反应出当前系统的操作的“热点”对象。这些对象都需要在选型之后、迁移之前重点评估其性能表现。能考虑分拆、缓存等手段,均可减低这些对象的热点压力。不仅局限于这些对象,更建议的是建立“业务压力模型”。通过对业务充分的了解和评估后,将业务逻辑抽象出来,转化为数据压力模型。此处的难点在于对业务逻辑的抽象能力及对模块业务量的比例评估。
形成类似下面的伪代码:

可依据上述伪代码,编制压力测试代码。通过一些工具调用测试代码,产生模拟测试的压力。这对于系统改造、升级、扩容评估、新硬件选型等均有意义。在具体去O工作中,新技术方案是否满足需要,可通过此方法进行评估验证。更多用业务的语言,来对比去O前后的承载力变化。这也是决策技术方案是否可行的考虑因素之一。当然上述信息,只包括了DML,对查询部分是不包含的,可以从Oracle AWR中获得这些数据。更为完整的,可以考虑结合应用做全链路的压测。
3.5 资源消耗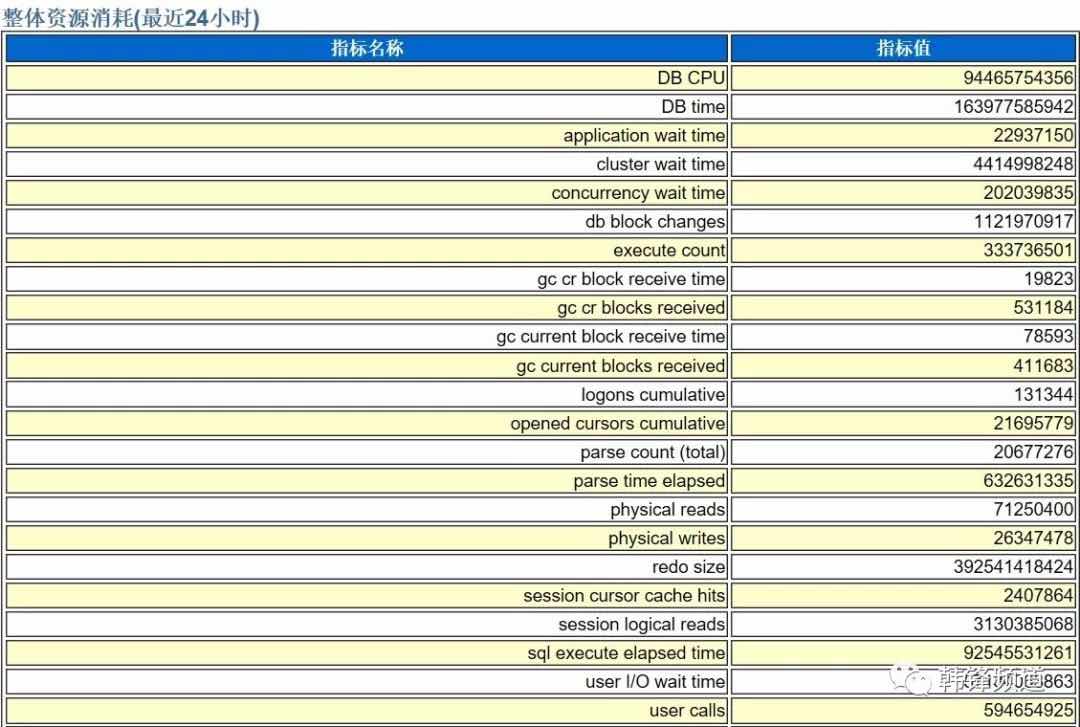
这里列出了最近24小时的资源使用情况。这些数据主要有两个目的:
1)评估整体负载