一、MapReduce概述
Hadoop MapReduce 是一个分布式计算框架,用于编写批处理应用程序。编写好的程序可以提交到 Hadoop 集群上用于并行处理大规模的数据集。
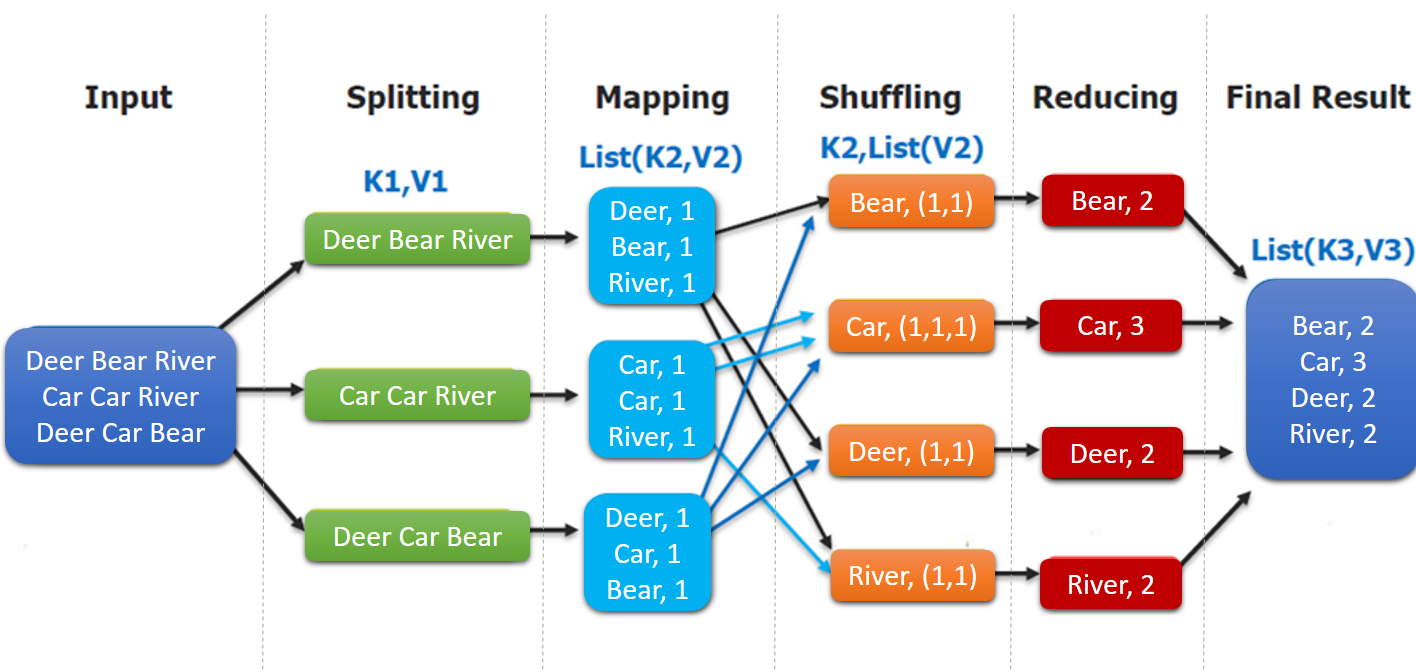
MapReduce 作业通过将输入的数据集拆分为独立的块,这些块由 map 以并行的方式处理,框架对 map 的输出进行排序,然后输入到 reduce 中。MapReduce 框架专门用于 <key,value> 键值对处理,它将作业的输入视为一组 <key,value> 对,并生成一组 <key,value> 对作为输出。输出和输出的 key 和 value 都必须实现Writable 接口。
(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output) 二、MapReduce编程模型简述这里以词频统计为例进行说明,MapReduce 处理的流程如下: