
ELMO根据上下文动态调整后的embedding不仅能够找出对应的相同语义的句子,而且还可以保证找出的句子中的同义词对应的词性也是相同的。不过,ELMO使用LSTM提取特征的能力不如后来的Transformer,其双向语言模型采取的是用简单的拼接来融合特征,一体化特征融合表现欠佳。
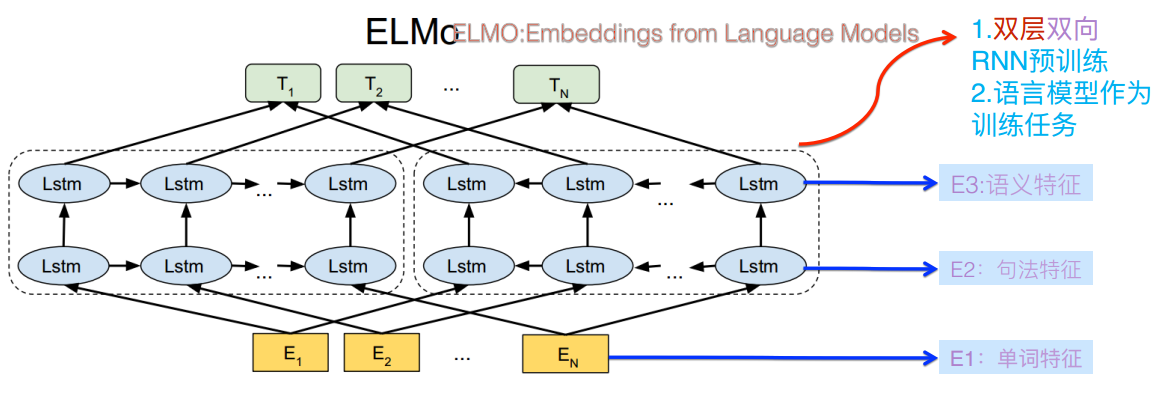
图4. ELMO模型示意图
BERT[5]作为动态词嵌入表示学习的集大成者,是一种双向融合特征的模型。
BERT提出两个任务:MLM(Masked Language Model)和NSP(Next Sentence Predict)。前者是词级别的,其采取的方法是,随机挡住15%的单词,让模型去预测这个单词,能够训练出深度的双向词嵌入向量表示;后者是句子级别的,也是一个二分类任务,其采取的方法是,将两个句子的序列串连作为模型的输入,预测后一句是否是前一句文本的下文,这一方法能够学习句子之间的关系,捕捉句子级别的表示。因此BERT得到的词嵌入表示融入了更多的语法、词法以及语义信息,而且动态地改变词嵌入也能够让单词在不同的语境下具有不同的词嵌入。
不过,BERT 对数据规模要求较高,如果没有足够大的语料,则很难达到预期的效果;其计算量很大,所需成本较高。
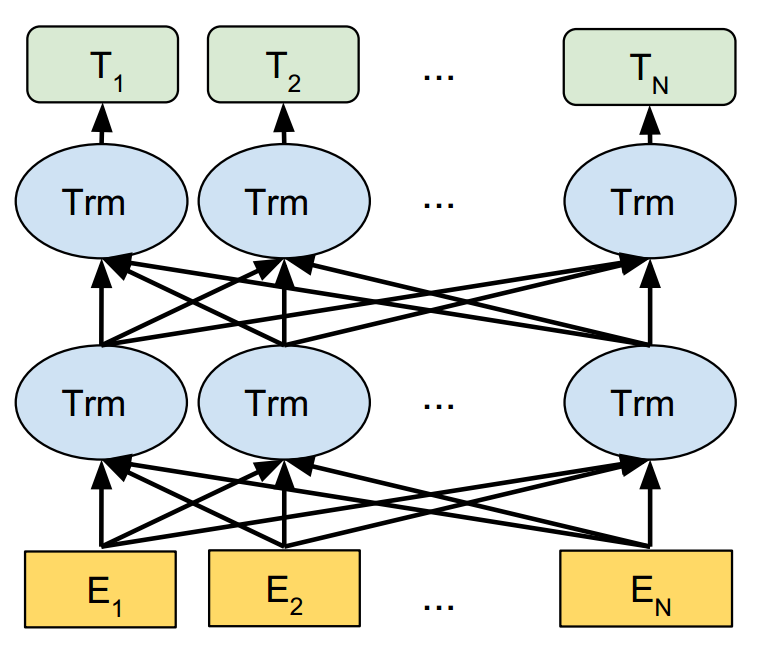
图5. BERT模型结构示意图
目前已经存在的主要词向量模型都是基于西方语言,这些西方语言的内部组成都是拉丁字母,然而,由于中文书写和西方语言完全不同,中文词语存在同音字、错别字等场景,而且中文字符内部的偏旁部首以及发音也包含了很强的语义信息,因此,如何有效利用中文字符内部的语义信息来训练词向量,成为近些年研究的热点[6,7,8]。
这里的典型代表是2018年蚂蚁金服提出的基于中文笔画的cw2vec模型[6]。文中将中文笔画划分为5类,类似于fasttext[9]的思想,每个词语使用n-gram 窗口滑动的方法将其表示为多个笔画序列。每个 gram 和词语都被表示成向量,用来训练和计算他们之间的相似度。为了简化计算文中也采用了负采样的方法,实验也取得了良好的效果。
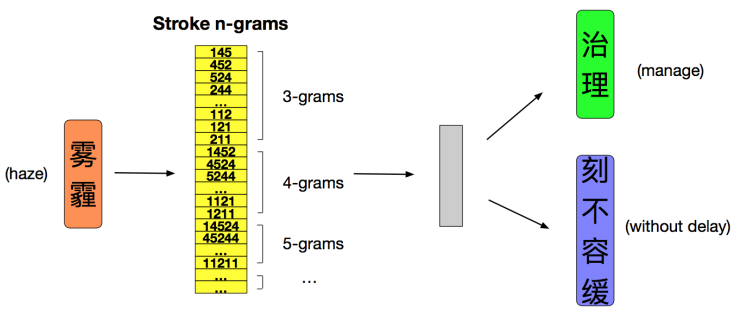
图6. cw2vec模型示意图
三、存在的问题及解决方案从以上相关工作可以看出,当前主要的词嵌入表征学习方法主要集中在从文本语料的上下文语义角度学习词嵌入,对于其他角度如中文词形学角度的研究较少。采用这些方法训练学习得到的词向量,即使在中文编辑距离较近、发音相同的词语,在词嵌入空间的距离也相差甚远。
例如,以腾讯AILab发布的百万词向量为例,该版词向量模型可以较好地捕捉中文词语间的语义相似度,但对于子词和同音字的相似度量场景,效果欠佳,如下图所示。
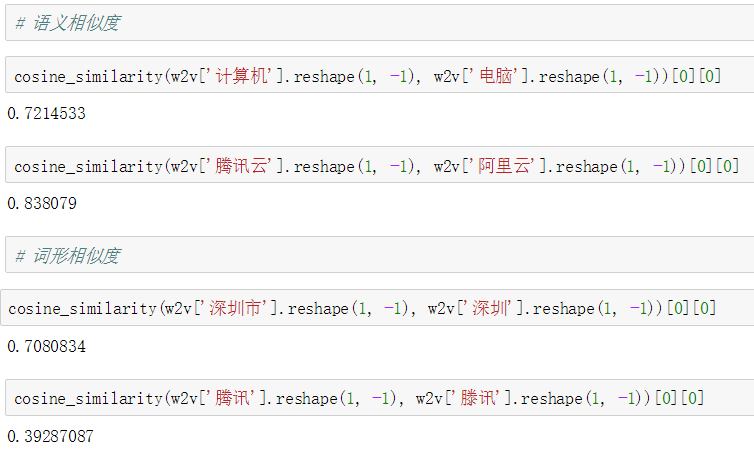
图7. 词向量相似度计算示例
在无需过多考虑语义相似度的前提下,本文提出从图计算的角度训练学习文本的向量表征,解决中文词形学相似匹配的问题。算法基本原理如下。
将常用汉字及业务场景下的词库构建无向带权图:每个词语和汉字作为图中一个节点,同时加入子词和拼音节点,依次在图中的“词语-子词-单字-拼音”节点间建立连边(如图8所示),根据字词之间在拼音和构成上的编辑距离(此处可根据业务需求灵活设置,亦可直接单独训练权重模型)为节点之间的连边赋予权重。
特别地,本文重点在同音字、平舌音、翘舌音以及子词序列等类型的节点间建立了连边,以保证同音字、易混字在图中可达,同时子词(subword)的引入在一定程度上保留了文本的语序特征。而后采用node2vec或metapath2vec等skip-gram类模型学习得到各节点的向量表示,以此作为字符的分布式表征。
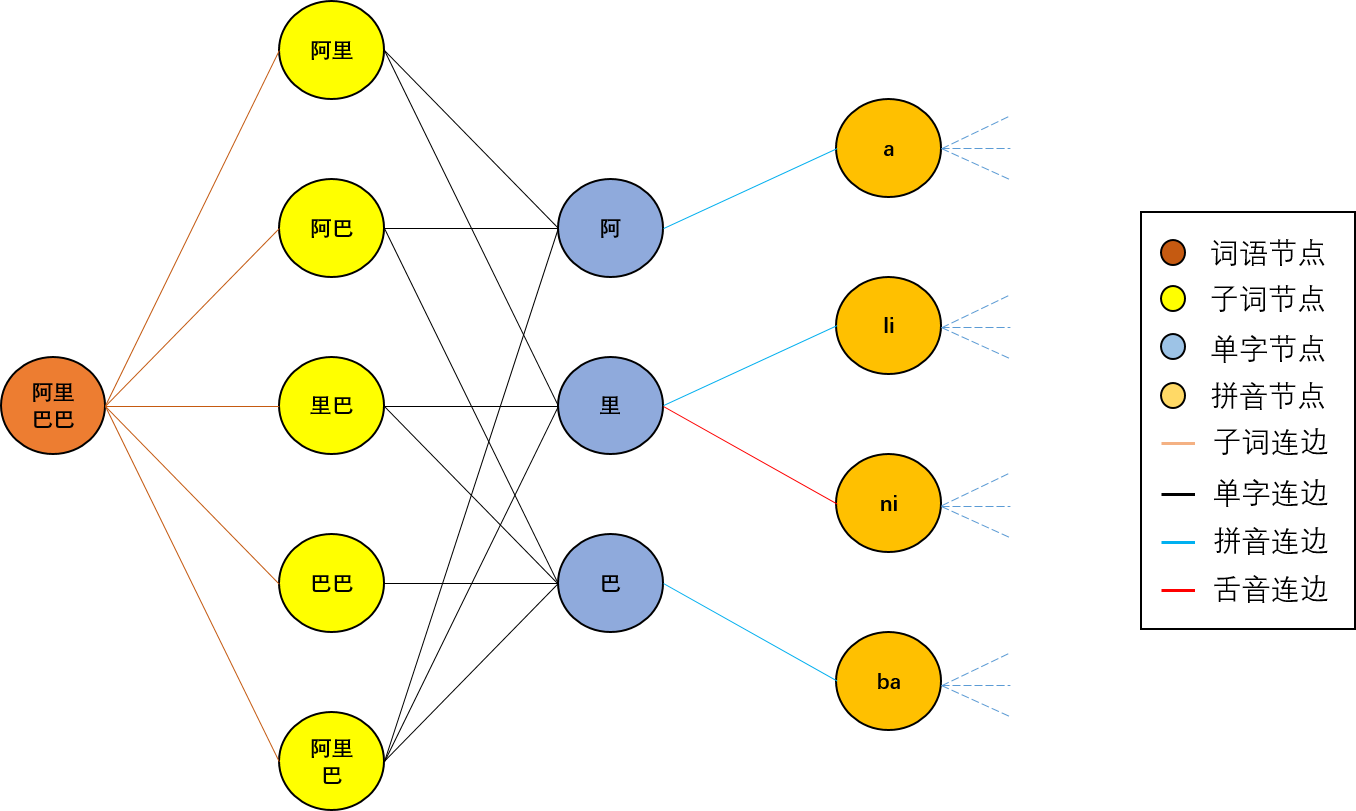
图8. 构图示例
在游走方式的选择上,对于当前业内主要的学习方法,如deepwalk[10]、node2vec[11]、Line[12]、metapath2vec[13]等算法,考虑到这里构造的图是带权图,故而不宜采用deepwalk,而图中的节点关联需要考虑二度以上联系,故不宜采用Line,所以本文重点对比node2vec和metapath2vec算法在嵌入效果上的差异。