
在自然语言处理领域,文本表示学习技术可以帮助我们将现实世界转化为计算机可以处理的数据,以求更精准地建立学习模型。而在中文搜索场景下,同音词、易混词、错别字等文本的召回和相似度匹配一直存在着棘手的问题,本文将尝试从图计算的角度来进行中文词向量的训练,并取得了积极的效果,希望与大家一同分享交流。文章作者:翟彬旭,腾讯云大数据高级研发工程师。
一、技术背景在中文搜索场景下,同音词、易混词、错别字等文本的召回和相似匹配是一个常见且棘手的问题。NLP(自然语言处理)社区对文本的匹配和召回已经经历从早期的基于分词和倒排索引的全文检索过渡到如今流行的文本向量检索。
向量检索通过训练和学习文本的分布式表征得到文本向量,可以解决倒排索引无法解决的语义相似度匹配问题,而且针对高维向量的大规模快速检索在业界已经有相当成熟的解决方案,如Faiss、Nmslib等。
但目前业内常用的表示学习方法很少考虑中文场景下由于输入法输入错误、发音问题等导致的文本相似匹配问题。
例如,在笔者所在的腾讯云企业画像产品研发过程中,就经常遇到类似的需求。当用户在我们的产品中搜索“腾迅科技集团股份有限责任公司”时,此时用户希望搜索的企业工商注册名称应该是“腾讯科技(深圳)有限公司”,但由于输入法错误(将“腾讯”错输为“腾迅”)、认知错误(将“有限责任公司”误认为“集团股份有限责任公司”)等原因,导致用户输入无法匹配到想要的搜索结果,甚至出现OOV的情况(“腾迅”可能不在词表中)。
如何在无需过多考虑语义相似度的前提下解决中文词形学表示学习的问题是本文讨论的重点话题。
二、词嵌入训练的演进在统计学习模型中,使用词嵌入(Word Embedding)完成自然语言处理任务,是NLP领域里的一项关键技术。常见的词嵌入(又称为文本表征)训练方法及主要特点如下图所示。
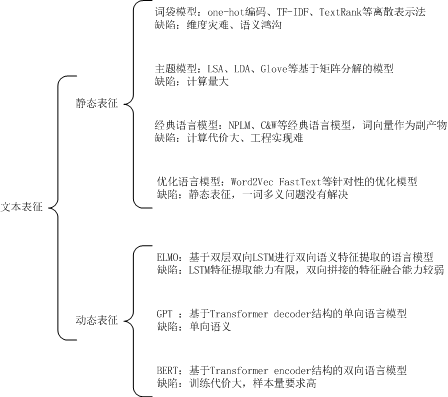
早期的词嵌入研究主要包括One-hot编码、TF-IDF等词袋模型。词袋模型(Bag of Words, BOW)是指忽略文档的语法和语序等要素,将文档仅仅看成是若干无序单词的集合,并且每个词都是独立的。
这些方法都属于离散表示法,当词汇表庞大时,会占用很大的存储空间,词汇表的大小决定了向量的维度大小,存在维数灾难问题。此外,这类方法无法通过任何计算得到词语之间的相似度,因此词向量之间不存在关联关系。
鉴于词袋表示法存在维度灾难、语义鸿沟的问题,Yoshua Bengio等人在[1]中证明使用神经网络训练的语言模型可以生成更好的词向量,并且提出了很多优化训练的方法。
如下图所示,整个网络分为两部分,第一部分是利用词特征矩阵C获得词的分布式表示(即词嵌入)。第二部分是将表示context的n个词的词嵌入拼接起来,通过一个隐藏层和一个输出层,最后通过softmax输出当前的p(wt|context)(当前上下文语义的概率分布,最大化要预测的那个词的概率,就可以训练此模型)。
这一模型框架不但训练了一个用神经网络表示的语言模型,而且作为语言模型的副产物还获得了词语的词嵌入(存在矩阵C中)。
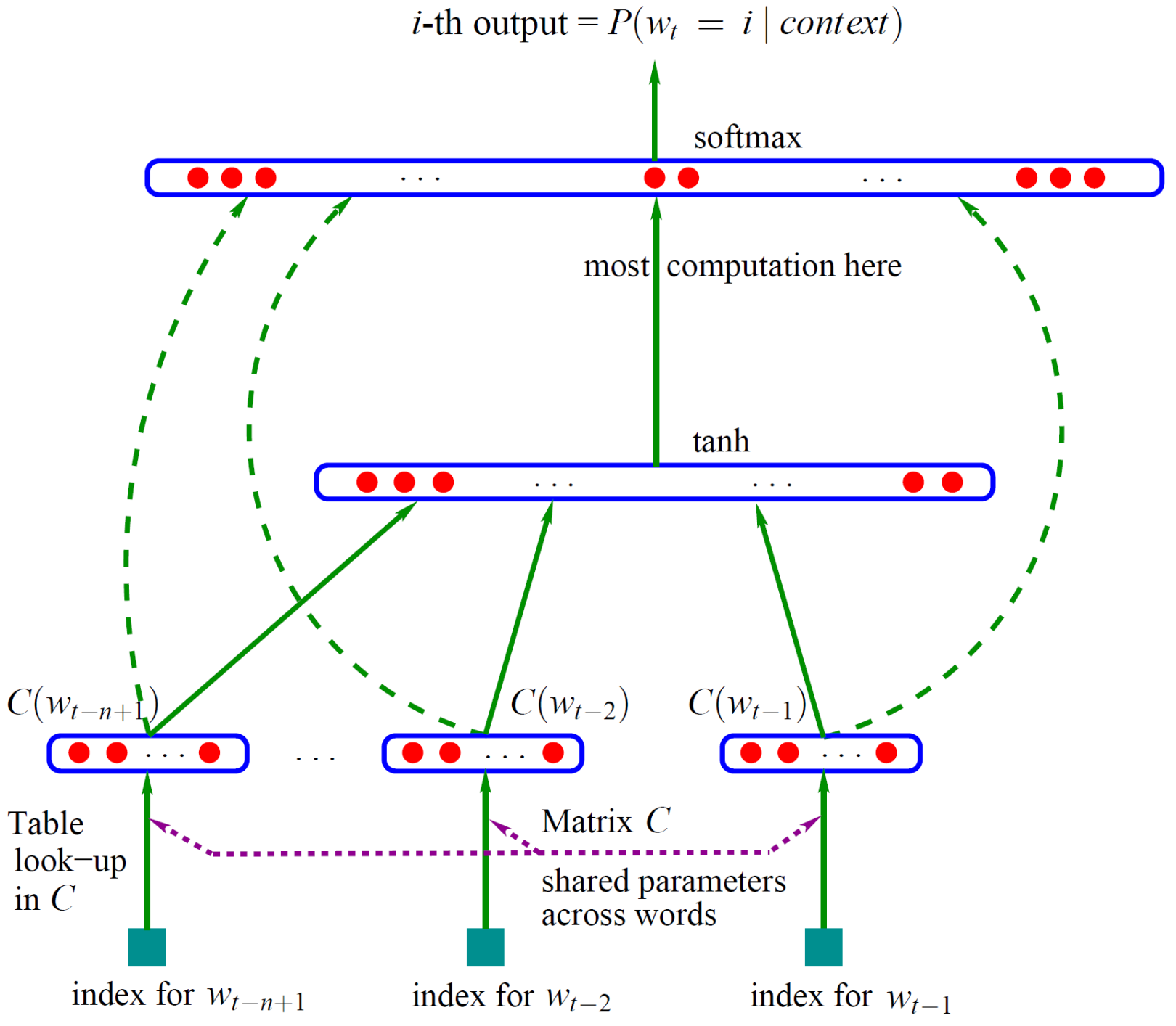
图2. 经典的自然语言模型(Bengio et al., 2003)
经典语言模型的训练存在计算量大的问题(主要集中在隐含层到输出层的全连接层以及输出层的softmax计算上),具体实现较为困难,针对这些问题,Mikolov等人[2,3]在语言模型的基础上进行了简化并给出了Cbow和skip-gram两种架构的word2vec模型,同时在具体学习过程中可以采用两种降低复杂度的近似方法——Hierarchical Softmax和Negative Sampling。
如下图所示,这种架构大大简化了计算量。不过,word2vec训练出来的词向量与单词是一对一的静态映射关系,一词多义问题没有解决。
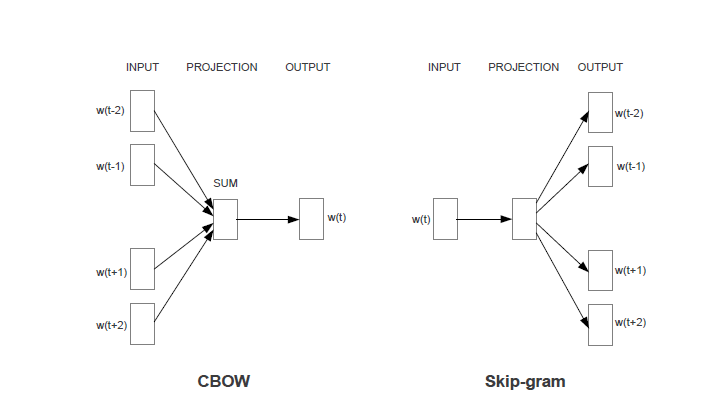
图3. word2vector模型结构
为了解决一词多义问题,ELMO模型[4]被提出来,它通过语言模型进行学习,得到一个词嵌入表示,在实际使用词嵌入时,根据上下文单词的语义再去调整单词的词嵌入表示,从而使得单词在不同的上下文语境得到不同的词嵌入表示。
网络结构采用双向LSTM网络。其中前向双层LSTM和逆向LSTM分别代表正方向和反方向编码器,输入分别是单词的上文和下文。一个句子输入到训练好的网络中,最终将得到每个单词三个不同的嵌入表示:双向LSTM中的两层词嵌入表示以及单词的词嵌入表示。其中双向LSTM中的两层词嵌入表示分别编码了单词的句法信息和语义信息。在做实际任务时,网络中单词对应的词嵌入表示将被提取出来作为新特征补充到实际任务中去。