
取得的结果,将保存期sql_id、plan_hash_value、object_name信息返回。这三个信息将分别用于后续提取SQL语句信息、执行计划信息、关联对象信息使用。
取得的全部结果集,将按照先前设定的扣分原则,统计扣分。
提取到的三部分信息+扣分信息,将作为结果返回,并在前端展示。
规则实现(执行计划)
这部分是MySQL中实现层次结果存储的一个实例。
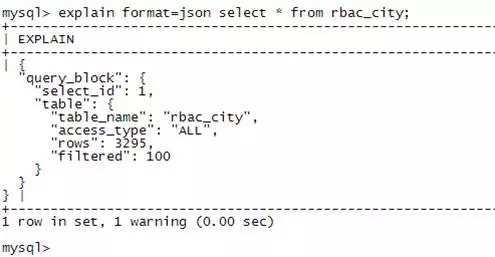
第一个图展示的是原始的执行计划。
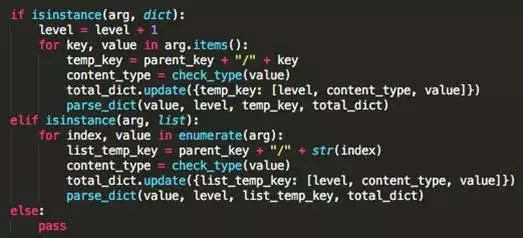
第二个图是代码实现的摘要。

第三个图是真正保存在库中的样子。核心部分就是对item_level的生成。
规则定义(文本级)
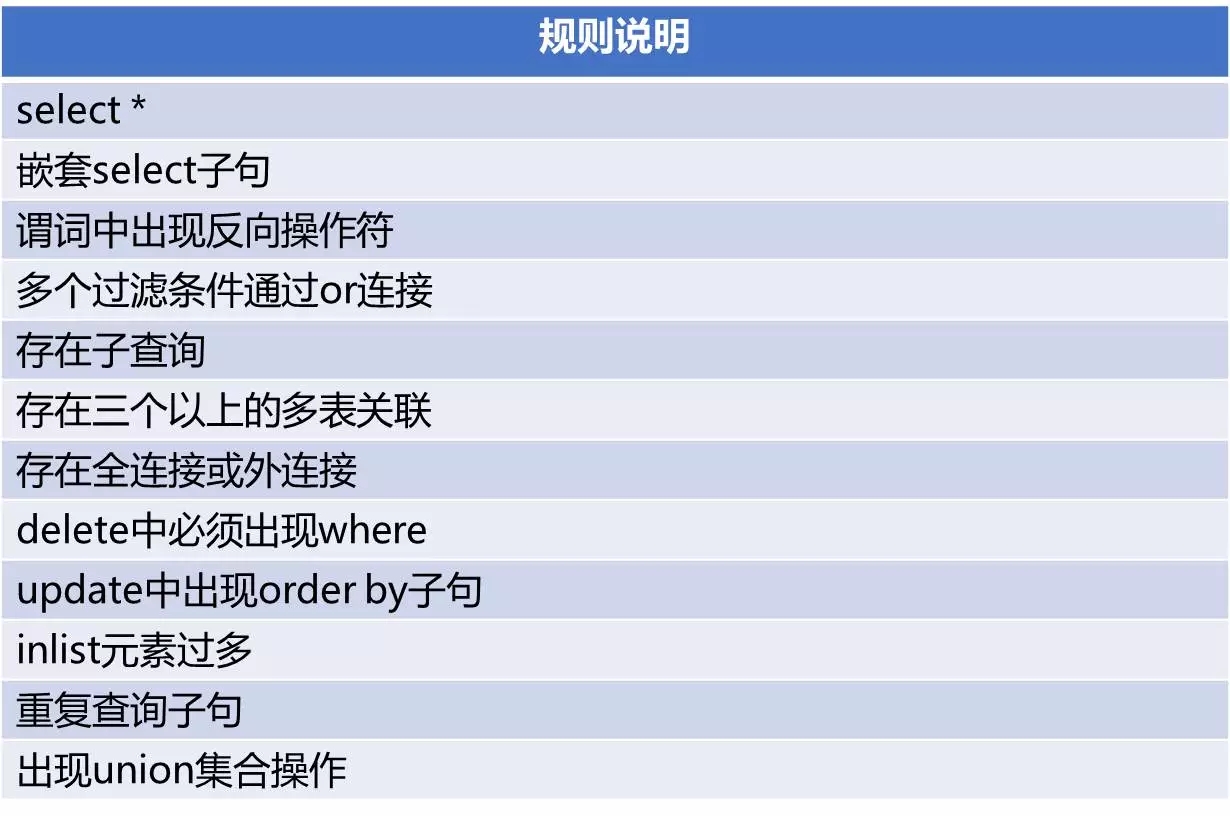
第三类规则是文本类的规则,这是一类与数据库种类无关、描述SQL语句文本特征的规则。在实现上是采用文本正则匹配或程序方式进行处理的。它的主要目的是规范开发人员的SQL写法,避免复杂的、性能较差的、不规范的SQL写法。
规则实现(文本级)

这部分描述的是文本规则的实现方式。第一个示例bad_join,是一种简单规则,通过正则文本匹配实现。第二个示例sub_query,是通过程序判断括号嵌套来完成对子查询(或多级子查询)的判断。
规则定义(执行特征级)

最后一类规则是执行特征类的。这部分是与数据库紧密关联的,将符合一定执行特征的语句筛选出来。这些语句不一定是低效的,可能只是未来考虑优化的重点,或者说优化效益最高的一些语句。这里面主要都是一些对资源的消耗情况等。
8、系统管理规则管理
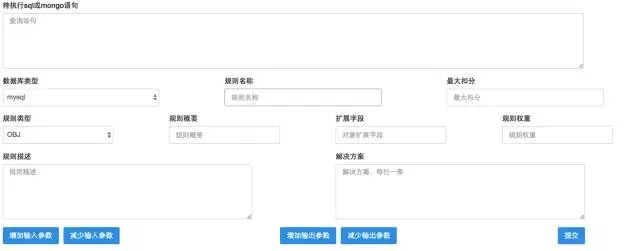
后面通过一些界面展示,介绍下平台的功能。
第一部分系统管理模块中规则管理的部分。在这部分,可完成新增自有规则。其核心是规则实现部分,通过SQL语句、Mongo查询语句、自定义Python文件的形式定义规则实现体。自定义规则的依据是现有抓取的数据源,定义者需要熟悉现有数据结构及含义。目前尚不支持自定义抓取数据源。
对定义好的规则,可在此处完成规则修改。主要是对规则状态、阀值、扣分项等进行配置。
任务管理
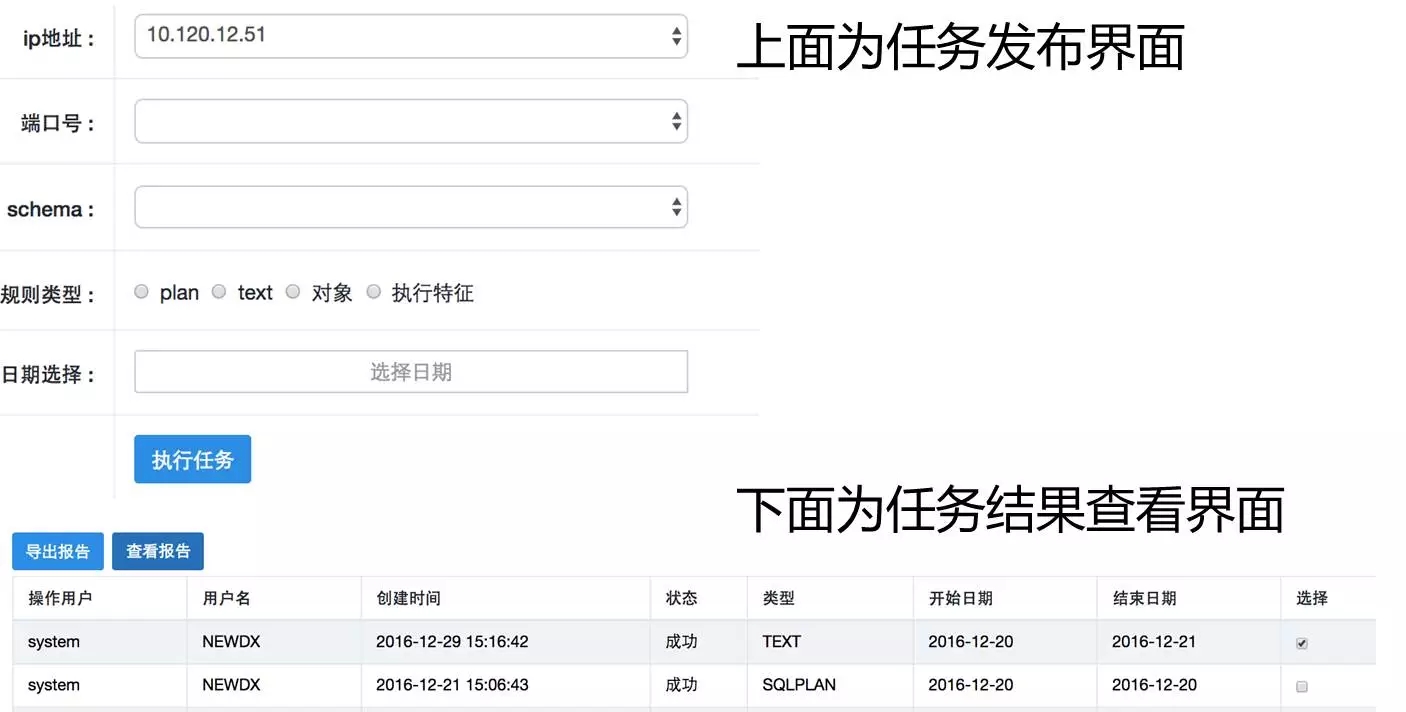
在配置好规则后,可在此处完成任务发布的工作。
上面是规则任务发布的界面,在选择数据源(ip、port、schema)后,选择审核类型及审核日期。目前审核数据源的定时策略还是以天为单位,因此日期不能选择当天。
当任务发布后,可在任务结果查看界面观察执行情况。根据审核类型、数据源对象多少、语句多少等,审核的时长不定,一般是在5分钟以内。当审核作业状态为“成功”时,代表审核作业完成,可以查看或导出审核结果了。
9、结果展示对象审核结果概览
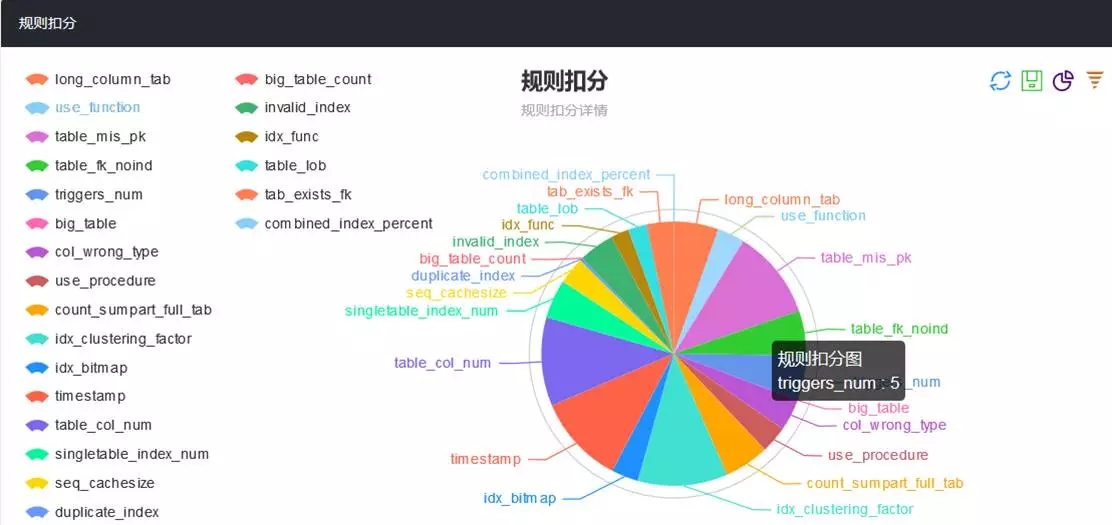
上图是一个对象审核报告的示例。在报告的开头部分,是一个概览页面。它集中展示审核报告中各类规则及扣分情况;并通过一个饼图展示其占比情况。这便于我们集中精力先处理核心问题。
在最上面,还可以观察到有一个规则总分的显示。这是我们将规则扣分按照百分制,折算后得到的一个分数。分值越高,代表违反的情况越少,审核对象的质量越高。引入“规则总分”这一项,在设计之初是有些争议的,担心有了这个指标会比较打击开发人员的积极性,不利于平台的推广使用。这里有几点,说明一下。
引入规则总分,是为了数据化数据库设计、开发、运行质量。以往在很多优化中,很难去量化优化前后的效果。这里提供了一种手段去做前后对比。可能这个方式不是太科学的,但是毕竟提供一种可量化的手段。
各业务系统差异较大,没有必要做横向对比。A系统60分,B系统50分,不代表A的质量就比B的质量高。
单一系统可多做纵向对比,即对比改造优化前后的规则总分。可在一定程度上反映出系统质量的变化。