
Themis开源地址:https://github.com/CreditEaseDBA
一、面临的挑战 1、运维规模及种类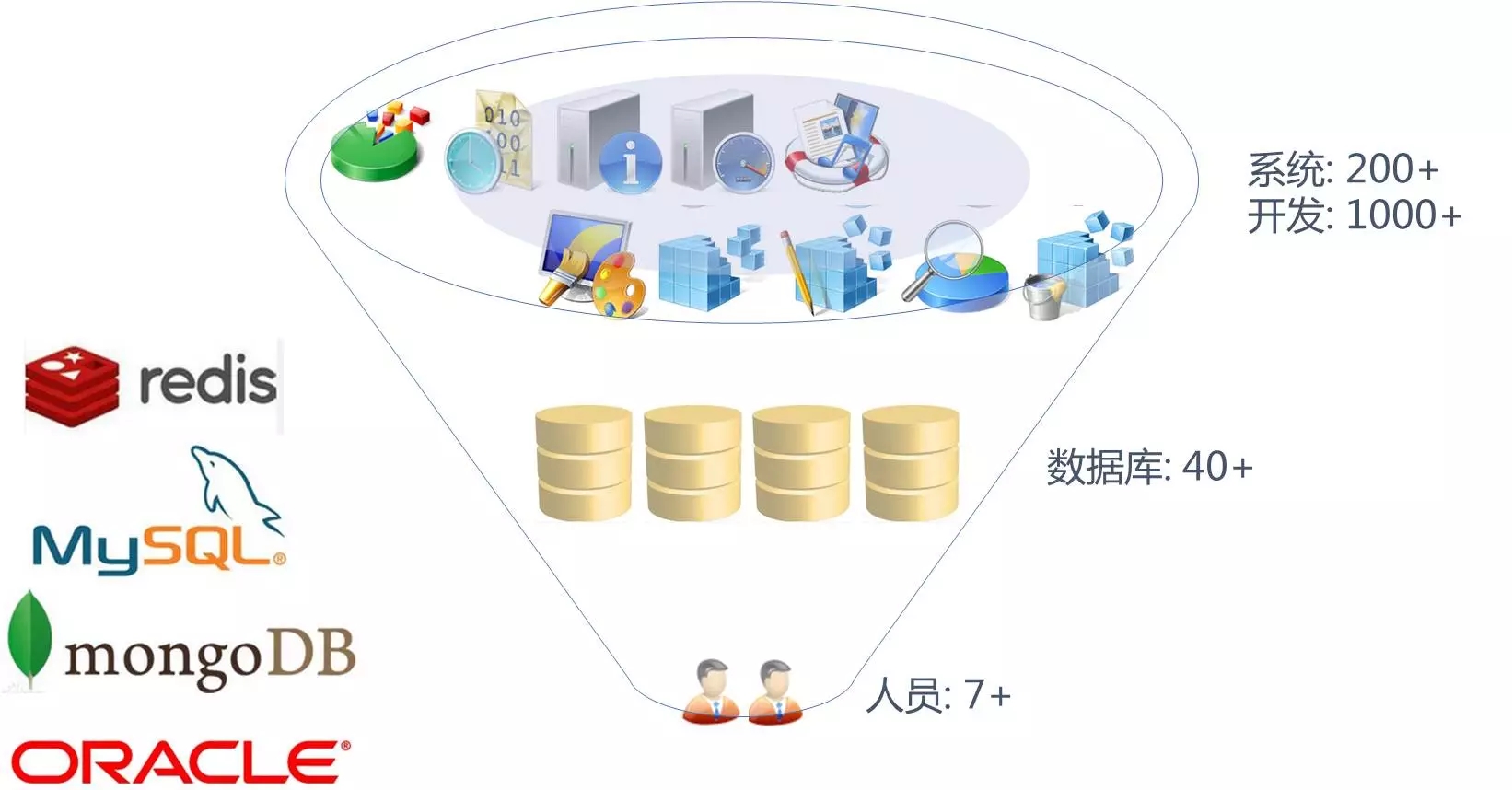
我相信,这也是很多公司、很多DBA正在面临或未来都会面临的一些问题。正是存在问题,促使我们考虑引入数据库审核平台。
首先是运维规模与人力资源之间的矛盾。从我们的情况来看,运维了包括Oracle、MySQL、MongoDB、Redis四类数据库,数据库规模几十套,支持公司千余名开发人员及上百套业务系统。也许有的朋友会问,从运维规模上看,并不是很大。
的确,与很多互联网公司相比,数据库数十套的估摸并不是太大;但与互联网类公司不同,类似宜信这类金融类公司对数据库的依赖性更大,大量的应用是重数据库类的,且其使用复杂程度也远比互联网类的复杂。DBA除了日常运维(这部分我们也在通过自研平台提升运维效率)外,还需要有大量精力应对数据库设计、开发、优化类的工作。当面对大量的开发团队需要服务时,这个矛盾就更加凸显出来。
2、案例结构设计
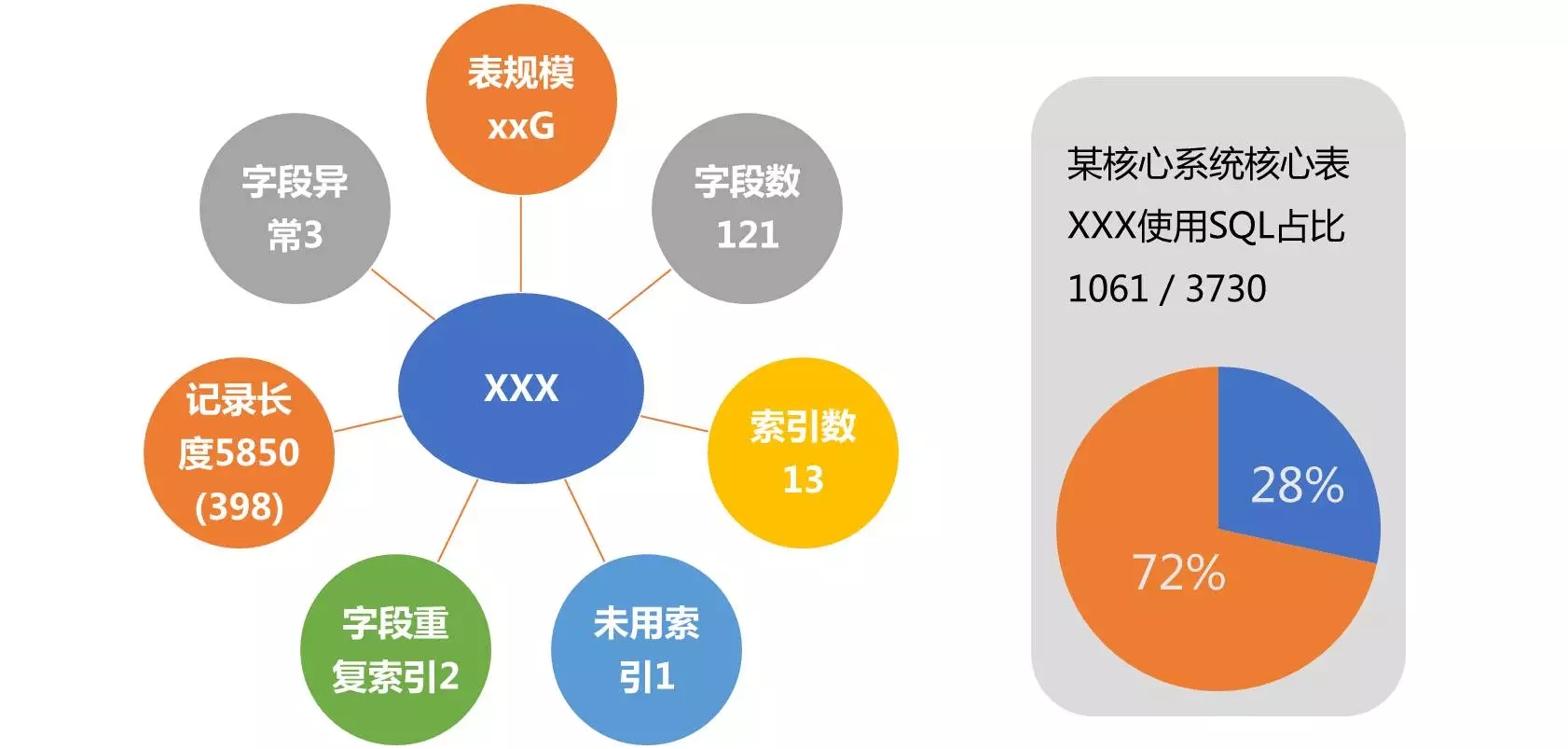
第二个挑战,是数据库设计、开发质量参差不齐的问题。 上图就展示了一个结构设计问题。某核心系统的核心表,在这个系统运行的SQL中,28%都是跟这个对象有关的。当我们分析其结构时,发现了很多的问题:
表的规模很大,从设计之初就没有考虑到拆分逻辑(例如分库、分表、分区设计),也没有必要的数据库清理、归档策略。
表存在100多个字段,字段数很多且不同字段使用特征也不一致,没有考虑到必要拆表设计。
表有13个索引,数目过多。表的索引过度,势必会影响其DML效率。
还存在一个索引,在持续监控中发现,其从未被使用过。显然这是一个“多余”的索引。
还有两个字段存在重复索引的现象,这也说明在建立索引之初是比较随意的。
单个记录定义长度为5800多个字节,但实际其平均保存长度只有不到400字节,最大长度也不长。
分析其字段内容,还发现有3个字段类型定义异常。即没有使用应有的类型保存数据,例如使用数字类型保存日期。
综上所述,这个表设计的问题还有很多,而且这个表非常重要,大量语句访问和其相关。
SQL语句
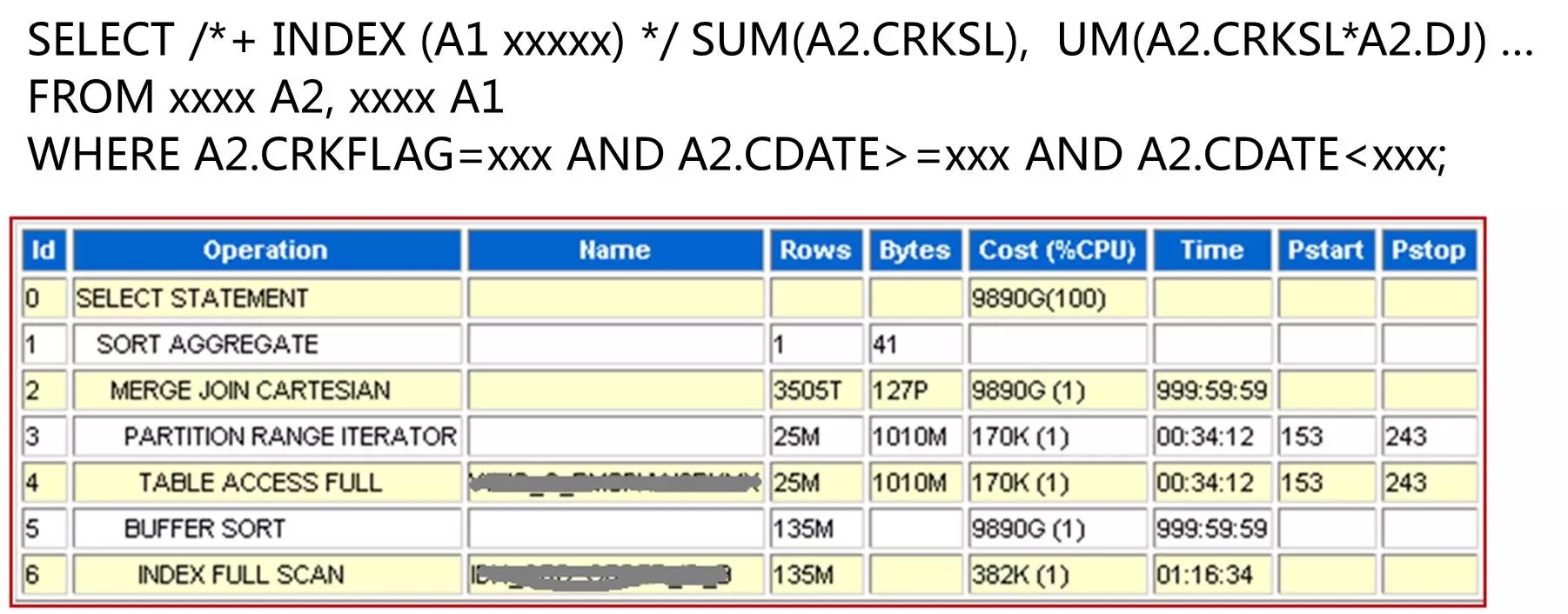
上图展示的是一个语句运行效率的问题。从字面可见,两个表做关联查询,但在指定条件时没有指定关联条件。在下面的执行计划中可见,数据库采用了笛卡尔积的方式运行。从后面的成本、估算时间等可见,这是一个多么“巨大”的SQL。其在线上运行的影响,可想而知。
也许有人会说,这是一个人为失误,一般不会发生。但我要说的是,第一,人为失误无法避免,谁也不能保证写出SQL的运行质量;第二,开发人员对数据库的理解不同,很难保证写出的SQL都是高效的;第三,开发人员面临大量业务需求,经常处理赶工状态,很难有更多的精力放在优化上面。这因为有这些问题,线上语句执行质量就成了DBA经常面临的挑战之一。
3、重心转移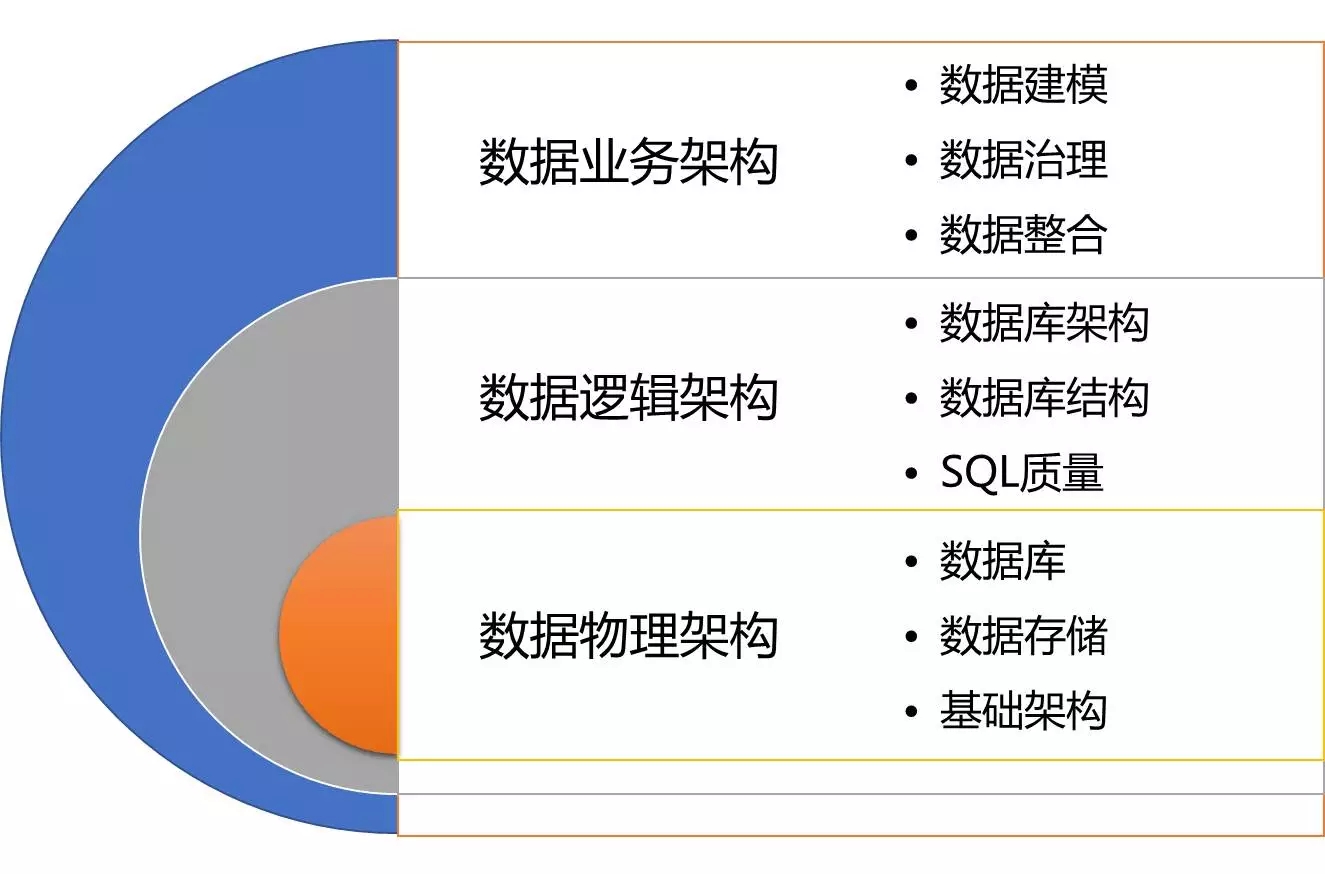
这是一张很经典的图,它描述了和数据库相关工作的职能划分。作为DBA,除了面临以上挑战外,从数据库工作发展阶段及自身发展需求来看,也面临一个重心的转移:原有传统DBA的运维职能逐步被弱化,大量的工具、平台的涌现及数据库自我运维能力的提升,简化DBA的工作;紧随而来的数据库架构、结构设计、SQL质量优化逐步成为重点;再往上层的数据治理、建模等工作也越来越受到一些公司的重视。由此可见,DBA未来工作的中心也逐步上移。对中间数据逻辑结构部分,也需要一些工具、平台更好地支撑DBA的工作。
除上述情况外,我司还存在几种的不平衡。

从DBA日常工作来看,传统运维工作还是占了较大的比重,而架构优化类则相对较少。通过引入这一平台,可以帮助DBA更方便地开展架构、优化类工作。
公司使用了较多的商业产品,而开源则使用较少。从公司长远战略来看,开源产品的使用会越来越多。从功能角度来看,商业产品相较于开源产品是有优势的。基于开源产品的软件开发,对开发者自身技术技能要求更高。希望通过引入这一产品,可以更容易完成这一转型过程。