pickle与序列化和反序列化
官方文档
模块 pickle 实现了对一个 Python 对象结构的二进制序列化和反序列化。 "pickling" 是将 Python 对象及其所拥有的层次结构转化为一个字节流的过程,而 "unpickling" 是相反的操作,会将(来自一个 binary file 或者 bytes-like object 的)字节流转化回一个对象层次结构。 pickling(和 unpickling)也被称为“序列化”, “编组” 或者 “平面化”。而为了避免混乱,此处采用术语 “封存 (pickling)” 和 “解封 (unpickling)”。
pickle.dumps(object):用于序列化一个对象
pickle.loads(picklestring):用于反序列化数据,实现一个对象的构建
测试代码:
#python3.7 import pickle class test_1(): def __init__(self): self.name = 'LH' self.age = 20 class test_2(): name = 'LH' age = 20 test1 = test_1() a_1 = pickle.dumps(test1) test2 = test_2() a_2 = pickle.dumps(test2) print("test_1序列化结果:") print(a_1) print("test_2序列化结果:") print(a_2) b_1 = pickle.loads(a_1) b_2 = pickle.loads(a_2) print("test_1反序列化结果:") print(b_1.name) print(b_1.age) print("test_2反序列化结果:") print(b_2.name) print(b_2.age)运行结果:
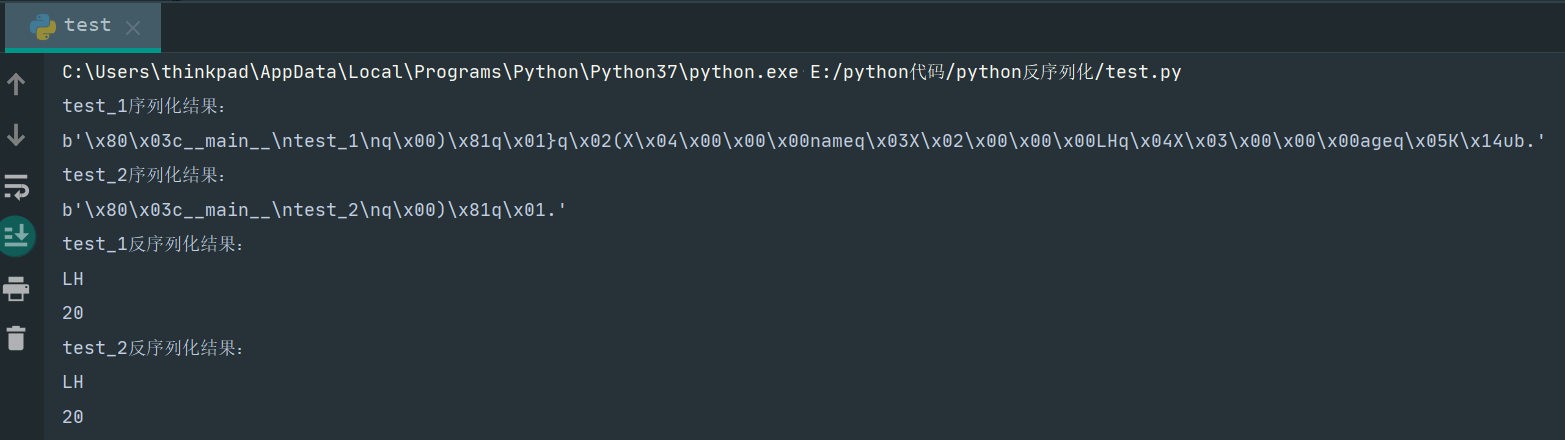
可以看到序列化结果长短不同,这是因为待处理的类里面有无__init__造成的,test_2类没有使用__init__所以序列化结果并没有涉及到name和age。但是反序列化之后仍然可以得到对应的属性值。
另外:如果在反序列化生成一个对象以前删除了这个对象对应的类,那么我们在反序列化的过程中因为对象在当前的运行环境中没有找到这个类就会报错,从而反序列化失败。
__reduce__()类似于PHP中的__wakeup__魔法函数。如果当__reduce__返回值为一个元组(2到5个参数),第一个参数是可调用(callable)的对象,第二个是该对象所需的参数元组。在这种情况下,反序列化时会自动执行__reduce__里面的操作。
测试代码:
#python3.7 import os import pickle class A(): def __reduce__(self): cmd = "whoami" return (os.system,(cmd,)) a=A() str=pickle.dumps(a) pickle.loads(str)运行结果:
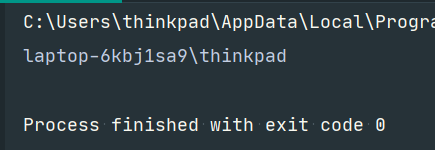
现在把关注点放在序列化数据,以及如何根据序列化数据实现反序列化。
指定protocolpickle.dumps(object)在生成序列化数据时可以指定protocol参数,其取值包括:

当protocol=0时,序列化之后的数据流是可读的(ASCII码)
当protocol=3时,为python3的默认protocol值,序列化之后的数据流是hex码
更改代码:
#python3.7 import os import pickle class A(): def __reduce__(self): cmd = "whoami" return (os.system,(cmd,)) a=A() str=pickle.dumps(a,protocol=0) print(str) print(str.decode()) #将byte类型转化为string类型运行结果:
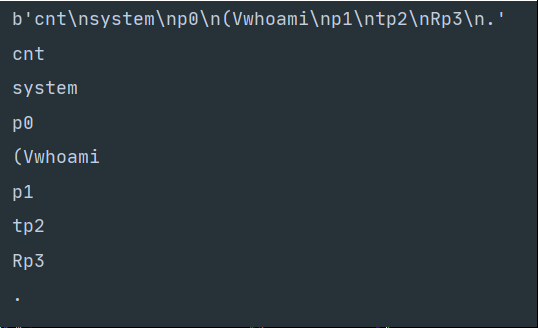
不了解pickle的相关指令的话,以上序列化结果根本看不懂:
pickle相关的指令码与作用:
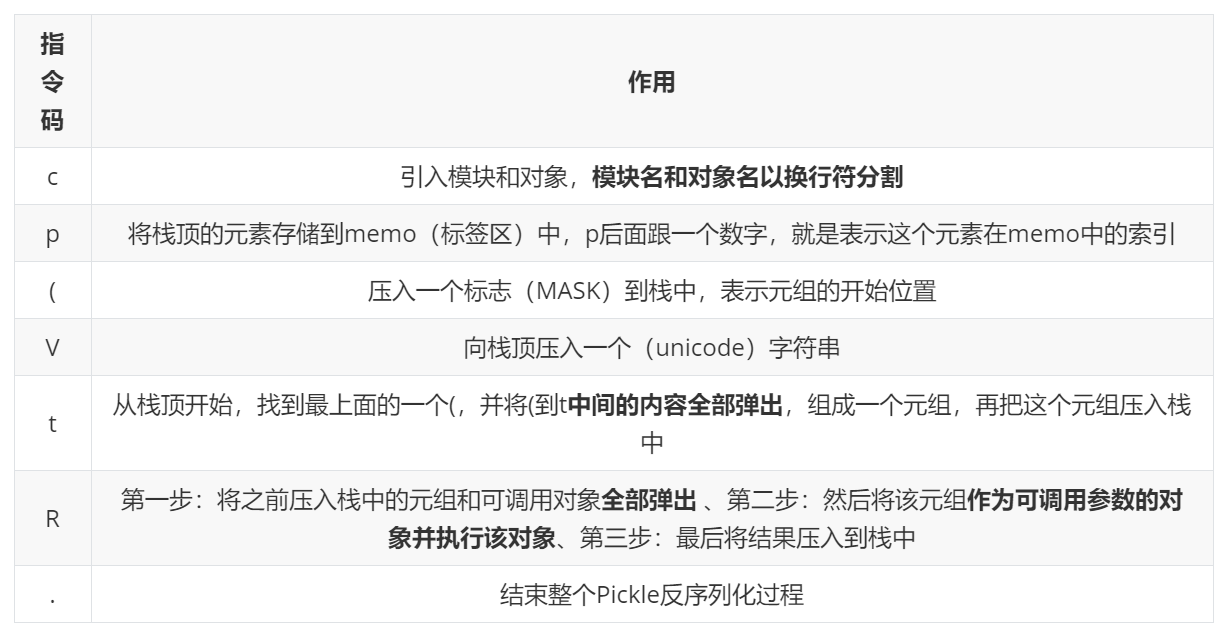
这里注意到R操作码,执行了可调用对象,可知它其实就是__reduce__()的底层实现。
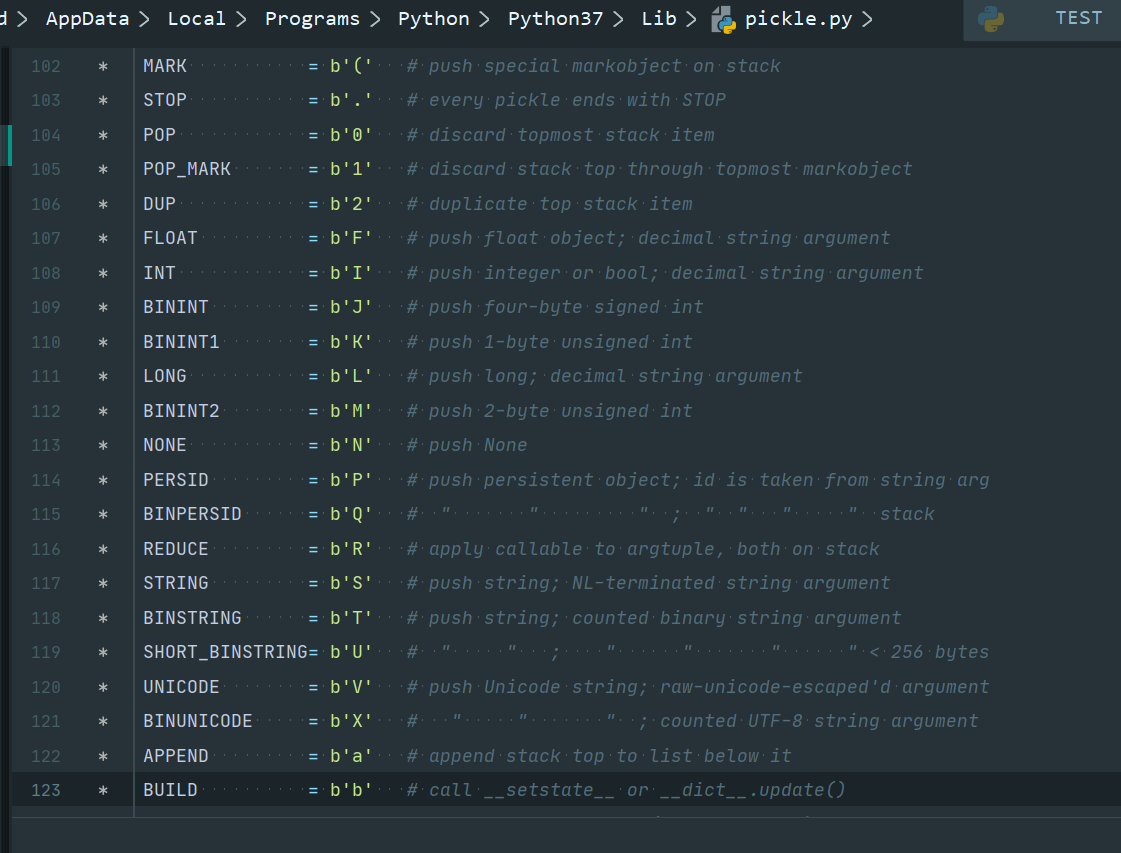
其他指令可以在python的lib文件下的pickle.py查看:
对运行结果分解:
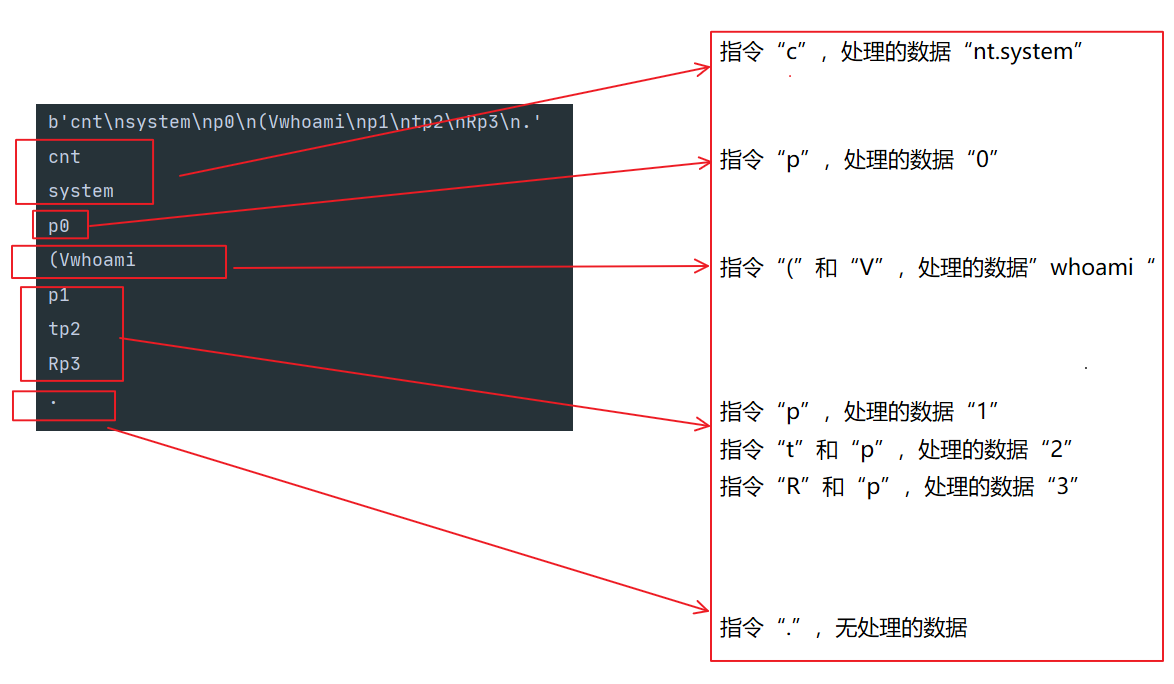
涉及到指令码,可以把pickle理解成一门栈语言:
pickle解析依靠Pickle Virtual Machine (PVM)进行。
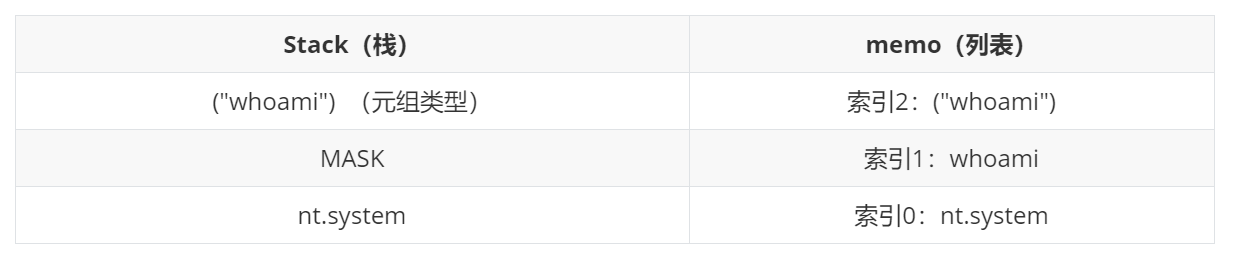
PVM涉及到三个部分:1. 解析引擎 2. 栈 3. 内存:
解析引擎:从流中读取指令码和参数,并对其进行解释处理。重复这个动作,直到遇到 . 停止。最终留在栈顶的值将被作为反序列化对象返回
栈:由Python的list实现,被用来临时存储数据、参数以及对象
memo列表:由Python的dict实现,为PVM的生命周期提供存储数据的作用,以便后来的使用
结合上面的指令码与作用,可以分析出具体的过程。
具体过程首先是:
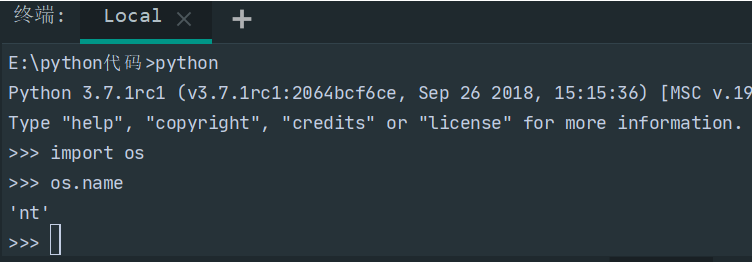
cnt system也即引入nt.system,这里的nt是模块os的名称name,os.name在不同环境对应的值不同:
Windows下为nt:
Linux下为posix:
posix是 Portable Operating System Interface of UNIX(可移植操作系统接口)的缩写。Linux 和 Mac OS 均会返回该值。

然后再执行p0,将栈顶内容写入到列表中,由于是列表第一个数据因此索引为0:

接下去执行(Vwhoami,(是将一个标志位MASK压入栈中,Vwhoami就是将字符串“whoami”压入栈中:
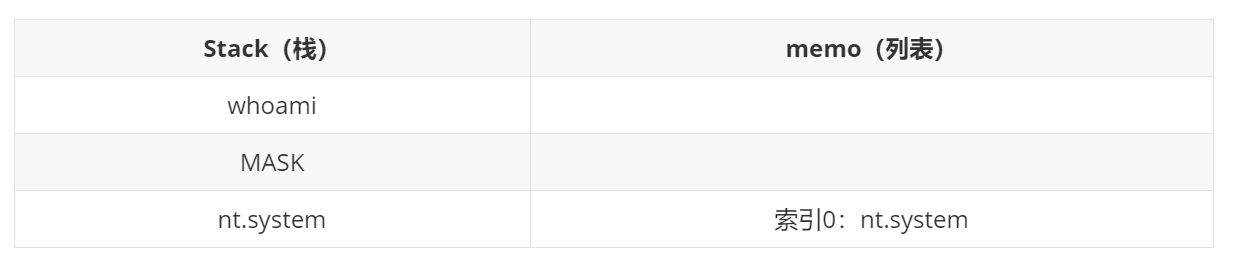
接下去执行p1,将栈顶数据"whoami"写入列表,索引为1:

再执行tp2,首先栈弹出从栈顶到MASK标志位的数据,将其转化为元组类型,然后再压入栈。最后p2将栈顶数据(也即元组)写入列表,索引为2: