
摘要:近几年,Rust语言以极快的增长速度获得了大量关注。其特点是在保证高安全性的同时,获得不输C/C++的性能。在Rust被很多项目使用以后,其实际安全性表现到底如何呢?
近几年,Rust语言以极快的增长速度获得了大量关注。其特点是在保证高安全性的同时,获得不输C/C++的性能,让系统编程领域难得的出现了充满希望的新选择。在Rust被很多项目使用以后,其实际安全性表现到底如何呢?今年6月份,来自3所大学的5位学者在ACM SIGPLAN国际会议(PLDI'20)上发表了一篇研究成果,针对近几年使用Rust语言的开源项目中的安全缺陷进行了全面的调查。
这项研究调查了5个使用Rust语言开发的软件系统,5个被广泛使用的Rust库,以及两个漏洞数据库。调查总共涉及了850处unsafe代码使用、70个内存安全缺陷、100个线程安全缺陷。
在调查中,研究员不光查看了所有漏洞数据库中报告的缺陷和软件公开报告的缺陷,还查看了所有开源软件代码仓库中的提交记录。通过人工的分析,他们界定出提交所修复的BUG类型,并将其归类到相应的内存安全/线程安全问题中。所有被调查过的问题都被整理到了公开的Git仓库中:https://github.com/system-pclub/rust-study
内存安全问题的分析这项研究调查了70个内存安全问题。针对于每个问题,研究者仔细的分析了问题出现的根因(cause)和问题导致的效果(effect)。问题根因是通过修改问题时提交的patch代码来界定的——即编码的错误发生在哪儿;问题的效果是指代码运行造成可观察的错误的位置,比如出现缓冲区溢出的代码位置。由于从根因到效果有个传递过程,这两者有时候是相隔很远的。根据根因和效果所在的代码区域不同,研究者将错误分为了4类:safe -> safe、safe -> unsafe、unsafe -> safe、unsafe -> unsafe。比如:如果编码错误出现在safe代码中,但造成的效果体现在unsafe代码中,那么就归类为safe -> unsafe。
另一方面,按照传统的内存问题分类,问题又可以分为空间内存安全(Wrong Access)和时间内存安全(Lifetime Violation)两大类,进一步可细分为缓冲区溢出(Buffer overflow)、解引用空指针(Null pointer dereferencing)、访问未初始化内存(Reading uninitialized memory)、错误释放(Invalid free)、释放后使用(Use after free)、重复释放(Double free)等几个小类。根据这两种分类维度,问题的统计数据如下:
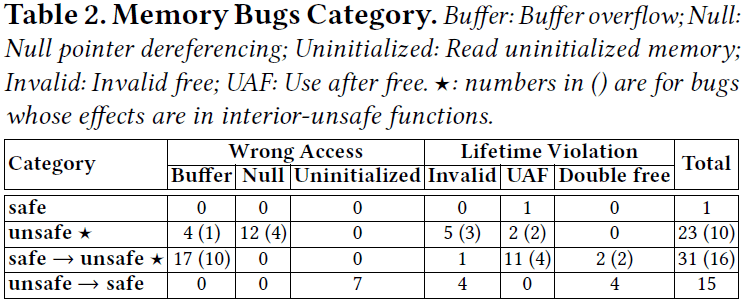
从统计结果中可以看出,完全不涉及unsafe代码的内存安全问题只有一个。进一步调查发现这个问题出现在Rust早期的v0.3版本中,之后的稳定版本编译器已经能拦截这个问题。因此可以说:Rust语言的safe代码机制能非常有效的避免内存安全问题,所有稳定版本中发现的内存安全问题都和unsafe代码有关。
然而,这并不意味着我们只要检查所有unsafe代码段就能有效发现问题。因为有时候问题根因会出现在safe代码中,只是效果产生在unsafe代码段。论文中举了一个例子:(hi3ms没有Rust代码编辑功能,只能拿其他语言凑合下了)
Css 代码
pub fn sign(data: Option<&[u8]>) { let p = match data { Some(data) => BioSlice::new(data).as_ptr(), None => ptr::null_mut(), }; unsafe { let cms = cvt_p(CMS_sign(p)); } }