λ是我们要调节的超参数,用来衡量Obj函数到底是更在乎简单程度,还是更在乎在训练集上的经验损失。所谓经验损失就是你在训练集上错了多少就叫经验损失。对于不同的loss和不同的Regularization这两项加合起来,让这两项的和最小,就达到了一个兼顾的目的,所以它们俩都要相对比较小,才是最好的模型效果。如果说为了达到使L(θ)让它下降一点点,而Ωθ上升好多,就代表着过拟合。模型复杂度上升了好多才带来了一点点提升,这种事情并不是我们想要的。我们希望一个简单的模型,能给我一个最好的答案;如果做不到这俩的话,也希望一个相对简单的模型给我一个相对比较好的结果就行了。加法在这里面达到了兼顾的目的。
对于不同的loss和不同的Regularization组合,再对它进行最优化,就构成了我们所谓的不同的算法。
比如对于mse损失函数组合一个L2正则就是岭回归,表达为:
对于mse损失函数组合一个L1正则就是lasso回归,表达为:
对于Logistic loss交叉熵损失函数组合一个L2正则就叫做逻辑回归,表达为:
所以逻辑回归的损失函数里必定会带这λw^2这项,没有这项就不能叫做逻辑回归。
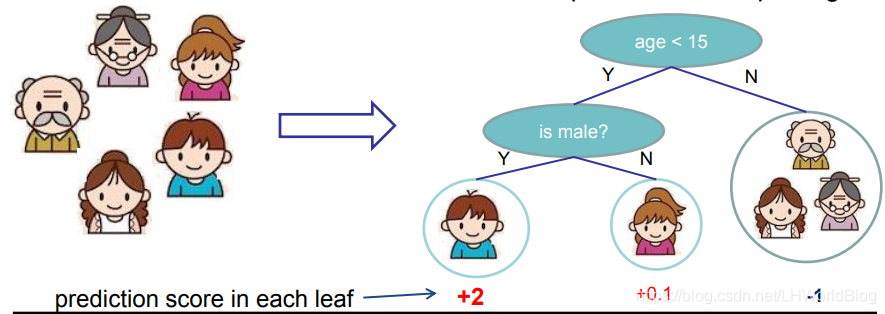
1.2 回归树概念在来回顾下回归树的相关概念,对于回归树(CART树Classification and Regression Trees)来讲,它的决策的分裂条件和决策树是一样的,也是多次尝试分裂,哪次结果最好就留下来。最后它会得到一个叶子节点,也能表达是一个连续的值,我们在此称之为score分数,对于回归树我们得到的是一组分数。比如下面例子: