
导读:本文将会分上下两篇对一个重要且常见的大数据基础设施平台展开讨论,即“实时数据平台”。 在上篇设计篇中,我们首先从两个维度介绍实时数据平台:从现代数仓架构角度看待实时数据平台,从典型数据处理角度看待实时数据处理;接着我们会探讨实时数据平台整体设计架构、对具体问题的考量以及解决思路。 在下篇技术篇中,我们会进一步给出实时数据平台的技术选型和相关组件介绍,并探讨不同模式适用哪些应用场景。希望通过对本文的讨论,读者可以得到一个有章可循、可实际落地的实时数据平台构建方案。
一、相关概念背景 1.1 从现代数仓架构角度看待实时数据平台现代数仓由传统数仓发展而来,对比传统数仓,现代数仓既有与其相同之处,也有诸多发展点。首先我们看一下传统数仓(图1)和现代数仓(图2)的模块架构:

图1 传统数仓
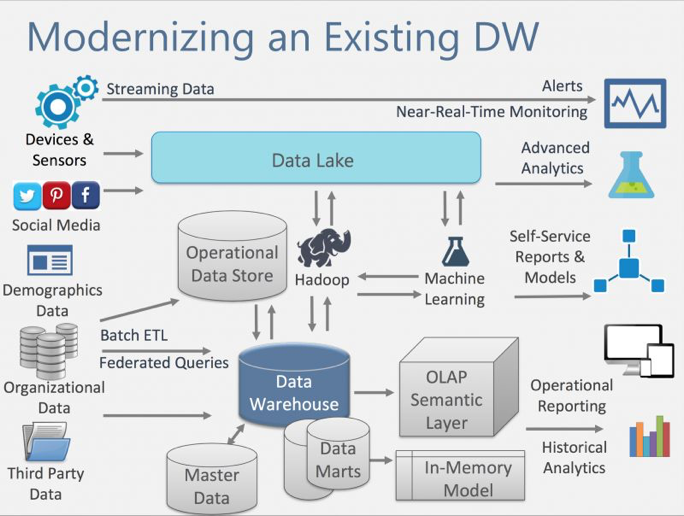
图2 现代数仓
传统数仓大家都很熟悉,这里不做过多介绍,一般来说,传统数仓只能支持T+1天时效延迟的数据处理,数据处理过程以ETL为主,最终产出以报表为主。
现代数仓建立在传统数仓之上,同时增加了更多样化数据源的导入存储,更多样化数据处理方式和时效(支持T+0天时效),更多样化数据使用方式和更多样化数据终端服务。
现代数仓是个很大的话题,在此我们以概念模块的方式来展现其新的特性能力。首先我们先看一下图3中Melissa Coates的整理总结:
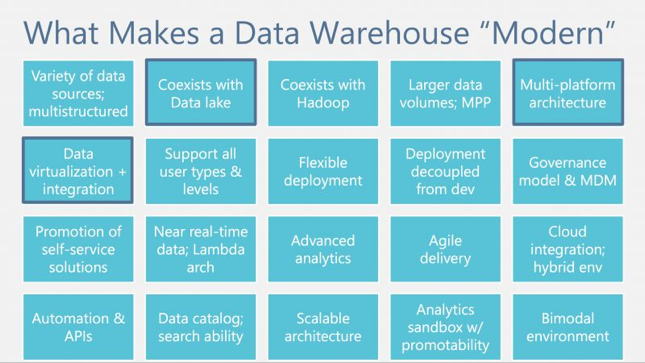
在图3 Melissa Coates的总结中我们可以得出,现代数仓之所以“现代”,是因为它有多平台架构、数据虚拟化、数据的近实时分析、敏捷交付方式等等一系列特性。
在借鉴Melissa Coates关于现代数仓总结的基础上,加以自己的理解,我们也在此总结提取了现代数仓的几个重要能力,分别是:
数据实时化(实时同步和流式处理能力)
数据虚拟化(虚拟混算和统一服务能力)
数据平民化(可视化和自助配置能力)
数据协作化(多租户和分工协作能力)
1)数据实时化(实时同步和流式处理能力)数据实时化,是指数据从产生(更新至业务数据库或日志)到最终消费(数据报表、仪表板、分析、挖掘、数据应用等),支持毫秒级/秒级/分钟级延迟(严格来说,秒级/分钟级属于准实时,这里统一称为实时)。这里涉及到如何将数据实时的从数据源中抽取出来;如何实时流转;为了提高时效性,降低端到端延迟,还需要有能力支持在流转过程中进行计算处理;如何实时落库;如何实时提供后续消费使用。实时同步是指多源到多目标的端到端同步,流式处理指在流上进行逻辑转换处理。
但是我们要知道,不是所有数据处理计算都可以在流上进行,而我们的目的,是尽可能的降低端到端数据延迟,这里就需要和其他数据流转处理方式配合进行,后面我们会进一步讨论。
2) 数据虚拟化(虚拟混算和统一服务能力)数据虚拟化,是指对于用户或用户程序而言,面对的是统一的交互方式和查询语言,而无需关注数据实际所在的物理库和方言及交互方式(异构系统/异构查询语言)的一种技术。用户的使用体验是面对一个单一数据库进行操作,但其实这是一个虚拟化的数据库,数据本身并不存放于虚拟数据库中。
虚拟混算指的是虚拟化技术可以支持异构系统数据透明混算的能力,统一服务指对于用户提供统一的服务接口和方式。

图4 数据虚拟化
(图1-4均选自“Designing a Modern Data Warehouse + Data Lake” - Melissa Coates, Solution Architect, BlueGranite)
3)数据平民化(可视化和自助配置能力)普通用户(无专业大数据技术背景的数据从业人员),可以通过可视化的用户界面,自助的通过配置和SQL方式使用数据完成自己的工作和需求,并无需关注底层技术层面问题(通过计算资源云化,数据虚拟化等技术)。以上是我们对数据平民化的解读。
对于Data Democratization的解读,还可以参见以下链接:
https://www.forbes.com/sites/bernardmarr/2017/07/24/what-is-data-democratization-a-super-simple-explanation-and-the-key-pros-and-cons