
Redis是目前非常流行的缓存数据库啦,其中一个主要作用就是为了避免大量请求直接打到数据库,以此来缓解数据库服务器压力;用上缓存难道就高枕无忧了吗?no,no,no,没有这么完美的技术, 缓存穿透、缓存雪崩、缓存击穿这些问题都得好好聊聊。
正文 1. 缓存穿透 1.1 简要描述缓存穿透是指查找的数据在缓存和数据库中都不存在,导致每一次请求数据从缓存中都获取不到,而将请求打到数据库服务器,但数据库中也没有对应的数据,最后每一次请求都到数据库;如果在高并发场景或有人恶意攻击,就会导致后台数据库服务器压力增大,最终系统可能崩掉。来个直接点的图:
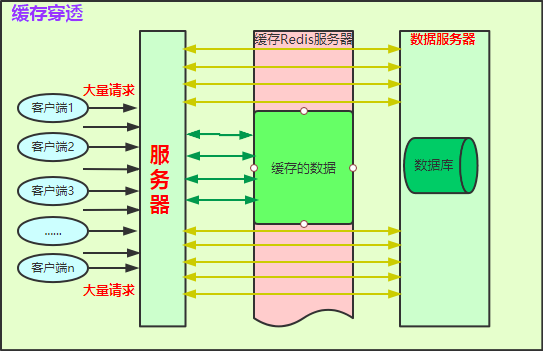
简要说明:
缓存Redis服务器颜色说明:绿色块代表有缓存数据,粉色块代表缓存中没有数据;绿色箭头代表直接从缓存中获取数据;黄色箭头代表穿过缓存从数据库中查数据,但不一定有。
流程大概如下:
大量客户端发起大量请求到服务器;
服务器代码逻辑将先经过缓存,如果有缓存数据(绿色部分),直接从缓存中获取数据数据返回;如果缓存中没有数据(粉色部分),请求就会直接打到数据库服务器(如黄色箭头)。
如果存在大量无缓存数据的请求,最终数据库将因为过大压力而崩掉,导致系统不可用。
1.2 常用解决措施
缓存空值:如果没有在数据库中获取到数据,可以将其对应键的空值进行缓存,并设置较短过期时间;
优点:在过期时间内直接通过缓存返回空值;从而避免数据库压力;
缺点:
消耗Redis内存:如果是攻击者换着非常规的键值请求,如果每次都缓存到Redis中,大量的空数据也占内存空间;
数据不一致:如果是正常数据,刚开始没有数据,然后将空值进行缓存,并设置短暂的过期时间;如果在过期时间内正常维护了对应的数据,此时取到值仍是空,并没有去数据库中获取新维护数据,导致数据获取不一致。
布隆过滤器
加一层过滤器进行拦截,判断请求对应的键是否在过滤器中,如果不在就直接返回,不去请求数据库,也不用缓存空值。而布隆过滤器采用bit位的形式标识对应键(每个键进行Hash过后都会得到具体的位置)是否存在,可以用极少的空间标识超大量的数据。
缺点:布隆过滤器可以判断数据一定不在过滤器中,而对于存在的判断有误判率,因为Hash算法存在冲突的情况。
1.3 布隆过滤器布隆过滤器不是专门用来针对缓存穿透的,它的应用场景很多,比如避免邮件重发、爬虫软件重爬、视频推送重复等;可能有的小伙伴还不明白为什么可以这么用,那先简单说说布隆过滤器的原理。
瞅个图先:
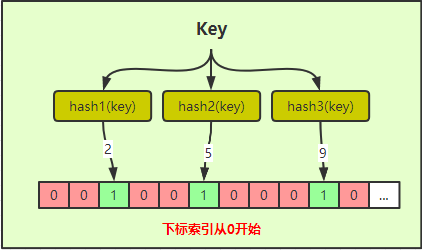
简要说明:
先来一个Key,后续需要判断Key是否存在(这里Key可以是任意想存的数据,比如用户ID、视频标识等);
将Key进行多次hash计算;每次的hash算法得到的结果都不一样;上图只画了三次hash计算,其实实际根据误判率不一样,hash次数就不一样;
将hash结果对应下标索引的bit位改为1,表示存在; 上图经过三次hash,结果分别为2、5、9,则将对应的位置改为1;
如果需要判断Key是否在过滤器中,同样需进行多次hash计算,上图为三次,将计算出来的结果作为索引去获取对应的标识,三次中只要有一次对应位置的值为0,那就证明Key不存在过滤器中。 如果是判定存在,则三次的结果对应位置的值应该都为1,不过这样是有误判可能,因为不同的Key,hash的结果有可能是一样的,从而就导致设置对应索引位时就会有冲突,如下图;
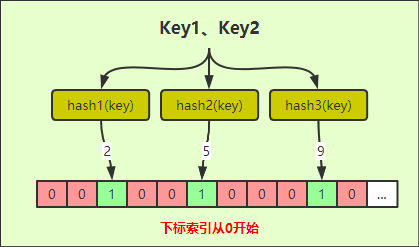
先假设Key1、Key2经过三次hash的结果一样(实际场景是存在的),倘若Key1先来都将2、5、9位置的值设为1,那Key2进来判断存在时,由于hash的结果一样,从而就误判为在过滤器中,其实不存在;
误判率在布隆过滤器中是可以控制,如果需要降低误判率,那就多进行几次hash计算,那位置相同的概率就降低啦;但这样会影响效率,另外也会有内存的额外开销,hash次数多,需要标识的位就越多。 就算有误判率,也很小,在绝大多数场景下可接受。
1.4 布隆过滤器的使用