
1)精度不高:语言是一个高度复杂的东西,采用简单的线性叠加显然会造成很大的精度损失。词语权重同样不是一成不变的,而且也难以做到准确。
2)新词发现: 对于新的情感词,比如给力,牛逼等等,词典不一定能够覆盖。
3)词典构建难: 基于词典的情感分类,核心在于情感词典。而情感词典的构建需要有较强的背景知识,需要对语言有较深刻的理解,在分析外语方面会有很大限制。
三、基于机器学习的情感分类方法基于机器学习的情感分类即为分类问题,文本分类中的各方法均可采用,文本分类问题可查看我的另外一篇文章《自然语言处理之文本分类》。
常见的分类算法有,基于统计的Rocchio算法、贝叶斯算法、KNN算法、支持向量机方法,基于规则的决策树方法,和较为复杂的神经网络。这里我们介绍两种用到的分类算法:朴素贝叶斯和支持向量机。情感分类模型的构建方法也很多,这里我们对《自然语言处理系列篇--情感分类》中的建模方法进行总结。
3.1 分类算法 3.1.1 朴素贝叶斯贝叶斯公式:$P(C|X)=P(X|C)P(C)/P(X)$
先验概率P(C)通过计算训练集中属于每一个类的训练样本所占的比例,类条件概率P(X|C)的估计—朴素贝叶斯,假设事物属性之间相互条件独立,$P(X|C)=\prod P(x_{i}|c_{i})$。朴素贝叶斯有两用常用的模型,概率定义略有不同,如下:设某文档d=(t1,t2,…,tk),tk是该文档中出现过的单词,允许重复。
多项式模型:
先验概率P(c)= 类c下单词总数/整个训练样本的单词总数。
条件概率P(tk|c)=(类c下单词tk在各个文档中出现过的次数之和+1)/( 类c下单词总数+|V|)
伯努利模型:
先验概率P(c)= 类c下文件总数/整个训练样本的文件总数。
条件概率P(tk|c)=(类c下包含单词tk的文件数+1)/(类c下单词总数+2)
通俗点解释两种模型不同点在于:计算后验概率时,对于一个文档d,多项式模型中,只有在d中出现过的单词,才会参与后验概率计算,伯努利模型中,没有在d中出现,但是在全局单词表中出现的单词,也会参与计算,不过是作为“反例”参与的。
3.1.2 支持向量机模型SVMSVM展开来说较为复杂,这里借助两张图帮助概念性地解释一下。对于线性可分的数据,可以用一超平面f(x)=w*x+b将这两类数据分开。如何确定这个超平面呢?从直观上而言,这个超平面应该是最适合分开两类数据的直线。而判定“最适合”的标准就是这条直线离直线两边的数据的间隔最大。
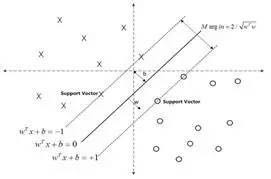
而对于线性不可分的数据,则将其映射到一个更高维的空间里,在这个空间里建立寻找一个最大间隔的超平面。怎么映射呢?这就是SVM的关键:核函数。
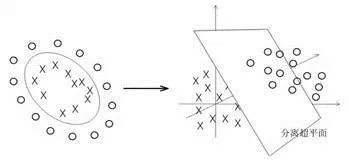
现在常用的核函数有:线性核,多项式核,径向基核,高斯核,Sigmoid核。如果想对SVM有更深入的了解,请参考《支持向量机通俗导论(理解SVM的三层境界)》一文。
3.2 情感分类系统的实现情感分类主要处理一些类似评论的文本,这类文本有以下几个特点:时新性、短文本、不规则表达、信息量大。我们在系统设计、算法选择时都会充分考虑到这些因素。情感分灰系统分为在线、离线两大流程,在线流程将用户输出的语句进行特征挖掘、情感分类、并返回结果。离线流程则负责语料下载、特征挖掘、模型训练等工作,系统结构如图3-1所示:
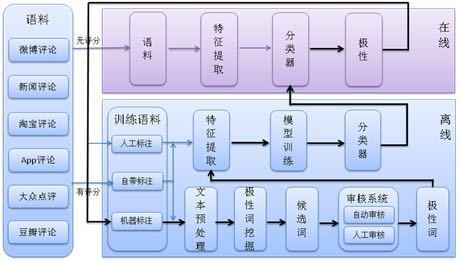
图3-1 情感分类系统框架图
3.2.1 语料库建设