
语料的积累是情感分类的基石,特征挖掘、模型分类都要以语料为材料。而语料又分为已标注的语料和未标注的语料,已标注的语料如对商家的评论、对产品的评论等,这些语料可通过星级确定客户的情感倾向;而未标注的语料如新闻的评论等,这些语料在使用前则需要分类模型或人工进行标注,而人工对语料的正负倾向,又是仁者见仁、智者见智,所以一定要与标注的同学有充分的沟通,使标注的语料达到基本可用的程度。
3.2.2极性词挖掘情感分类中的极性词挖掘,有一种方法是“全词表法”,即将所有的词都作为极性词,这样的好处是单词被全面保留,但会导致特征维度大,计算复杂性高。我们采用的是“极性词表法”,就是要从文档中挖掘出一些能够代表正负极性的词或短语。如已知正面语料“@jjhuang:微信电话本太赞了!能免费打电话,推荐你使用哦~”,这句话中我们需要挖掘出“赞”、“推荐”这些正极性词。分为以下两步:
1)文本预处理 语料中的有太多的噪音,我们在极性词挖掘之前要先对文本预处理。文本预处理包含了分词、去噪、最佳匹配等相关技术。分词功能向大家推荐腾讯TE199的分词系统,功能强大且全面,拥有短语分词、词性标注等强大功能。去噪需要去掉文档中的无关信息如“@jjhuang”、html标签等,和一些不具有分类意义的虚词、代词如“的”、“啊”、“我”等,以起到降维的作用。最佳匹配则是为了确保提出的特征能够正确地反映正负倾向,如“逍遥法外”一词,如果提取出的是“逍遥”一词,则会被误认为是正面情感特征,而“逍遥法外”本身是一个负面情感词,这里一般可以采用最长匹配的方法。
2)极性词选择 文本预处理之后,我们要从众多词语中选出一些词作为极性词,用以训练模型。我们对之前介绍的TF-IDF方法略作变化,用以降维。因为我们训练和处理的文本都太短,DF和TF值大致相同,我们用一个TF值就可以。另外,我们也计算极性词在反例中出现的频率,如正极性词“赞”必然在正极性语料中的TF值大于在负极性语料中的TF值,如果二者的差值大于某个域值,我们就将该特征纳入极性词候选集,经过人工审核后,就可以正式作为极性词使用。
3.2.3极性判断极性判断的任务是判断语料的正、负、中极性,这是一个复杂的三分类问题。为了将该问题简化,我们首先对语料做一个主客观判断,客观语料即为中性语料,主观语料再进行正、负极性的判断。这样,我们就将一个复杂三分类问题,简化成了两个二分类问题。如下:
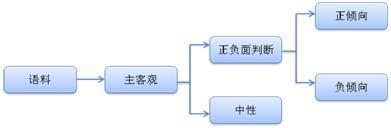
在分类器选择中,主客观判断我们使用了上节介绍的支持向量机模型。而极性判断中,我们同时使用了朴素贝叶斯和支持向量机模型。其中朴素贝叶斯使用人工审核过的极性词作特征,而支持向量机模型则使用全词表作为特征。两个模型会对输入的语料分别判断,给出正、负极性的概率,最后由决策模块给出语料的极性。
在朴素贝叶斯模型中,我们比较了多项式模型和伯努力模型的效果。伯努力模型将全语料中的单词做为反例计算,因为评测文本大多是短文本,导致反例太多。进而伯努力模型效果稍差于多项式模型,所以我们选择了多项式模型。
支持向量机模型中,我们使用的是台湾大学林智仁开发的SVM工具包LIBSVM,这是一个开源的软件包,可以解决模式识别、函数逼近和概率密度估计等机器学习基本问题,提供了线性、多项式、径向基和S形函数四种常用的核函数供选择。LIBSVM 使用的一般步骤是:
按照LIBSVM软件包所要求的格式准备数据集;
对数据进行简单的缩放操作;
考虑选用RBF 核函数;
采用交叉验证选择最佳参数C与g;
采用最佳参数C与g 对整个训练集进行训练获取支持向量机模型;
利用获取的模型进行测试与预测。