
所有GPU 各自独立与参数服务器通信,交换、融合梯度。每个 worker 在每轮训练开始前从参数服务器获取模型参数,读取训练数据,进行训练,训练结束后便立即应用梯度来更新参数服务器上的模型参数。
异步更新通信效率高速度快,但往往收敛不佳,因为一些速度慢的节点总会提供过时、错误的梯度方向。同步更新通信效率低,通常训练慢,但训练收敛稳定,因为同步更新基本等同于单卡调大的batch size训练。但是传统的同步更新方法(各个GPU卡算好梯度,求和算平均的方式),在融合梯度时,会产生巨大的通信数据量。
通过比对不同分布式并行方式、系统架构和参数更新,微信扫一扫识物最终选择基于数据并行的参数同步更新的Ring all-reduce的分布式训练方法。
三、多机通信技术
相比于单机多卡,多机多卡分布式训练要保证多台机器之间是可以互相通信的以及不同机器之间梯度可传递。
并行任务的通信一般可以分为点对点通信和集体通信。点对点通信这种模式只有一个sender和一个receiver,实现起来比较简单。而涉及到分布式训练,一般是多台服务器,用到集体通信模式,包含多个sender多个receiver。集体通信常用的通信方式主要有下面几个:broadcast、gather、scatter、reduce、all-reduce等。
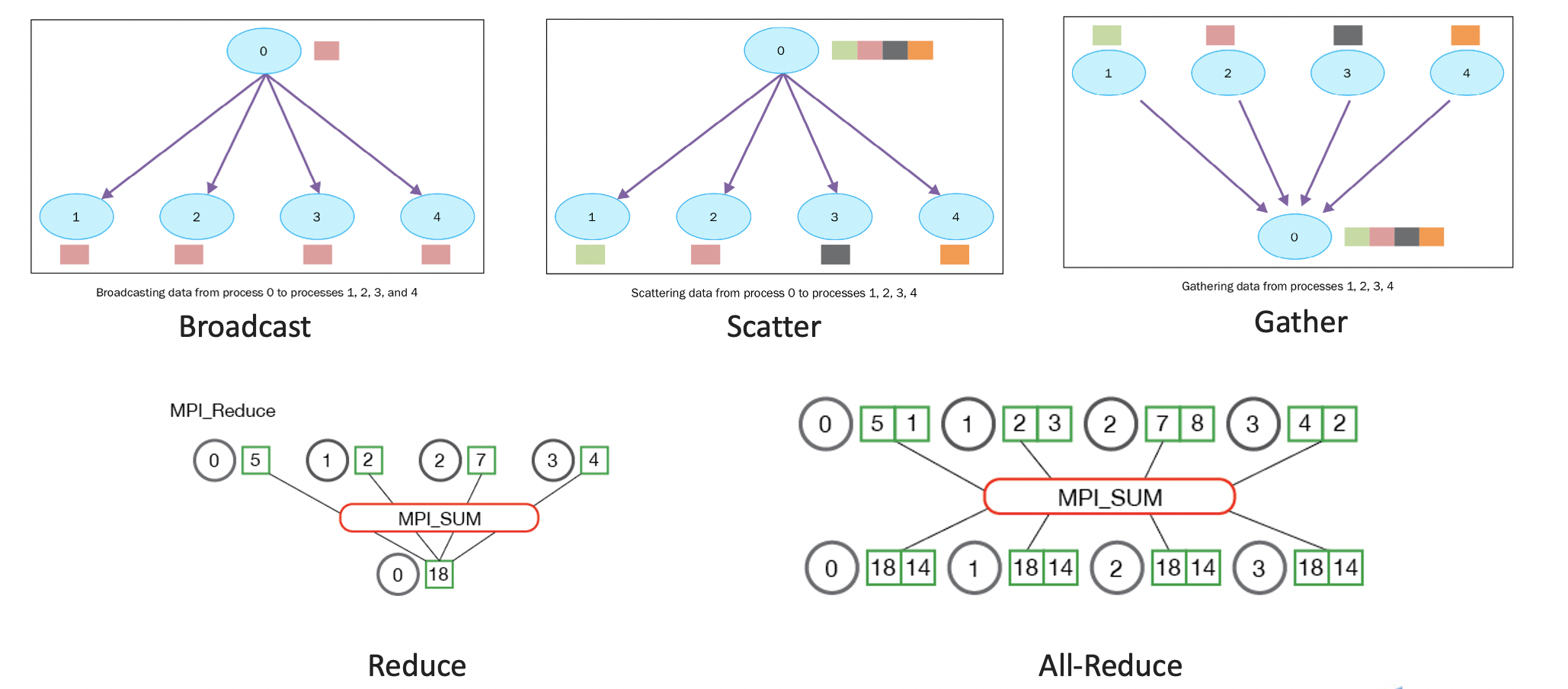
1. MPI
在微信的自研训练平台中,多机的通信是基于消息传递接口(Message Passing Interface,MPI)来实现的,MPI是一种基于信息传递的并行编程技术,定义了一组具有可移植性的编程接口,是一种编程接口标准。
在基于MPI编程模型中,计算是由一个或多个彼此通过调用库函数进行消息收、发通信的进程所组成。MPI中的通讯器定义了一组能够互相发消息的进程。在这组进程中,每个进程会被分配一个序号,称作秩(rank),进程间显性地通过指定秩来进行通信。MPI涉及到的一些操作包括数据移动,聚集、同步等。
由于深度学习训练参数大多在GPU上的,如果只是依靠MPI来同步参数,参数需要先从GPU搬到CPU,然后不同机器CPU之间再通信,通信结束之后再将参数从CPU搬到GPU,这个过程的通信效率是很低的。所以为了提高通信效率,在训练的过程中使用基于nvidia开发的NCCL进行通信。
2. NCCL
NCCL是Nvidia Collective multi-GPU Communication Library的简称,是Nvidia开发的能够实现多GPU的集体通信的库,能够很方便的集成至任何深度学习的训练框架。在实现 Allreduce、Reduce、Broadcast、Allgather等方面做了很多优化,可以在PCIe、Nvlink、InfiniBand上实现较高的通信速度。
目前NCCL1.0版本只支持单机多卡,卡之间通过PCIe、NVlink、GPU Direct P2P来通信。NCCL 2.0会支持多机多卡,多机间通过Sockets (Ethernet)或者InfiniBand with GPU Direct RDMA通信。
四、Horovod训练框架
目前分布式训练框架有许多,Horovod 是 Uber 开源的一个深度学习工具,囊括了TensorFlow, Keras, PyTorch, and Apache MXNet 这些分布式训练框架。
并且Horovod的梯度同步和权值同步利用基于MPI和NCCL的 all-reduce算法,而非参数服务器架构,通信效率更高。Horovod可以利用NVLINK、RDMA、GPUDirectRDMA、自动检测通信拓扑以及回退到 PCIe 和 TCP/IP 通信这些功能。同时,将已有的训练代码改成分布式训练代码,改动量少,简化分布式训练的运行和启动。
基于此,微信扫一扫识物选择Horovod的分布式训练框架,在微信自研的训练平台上进行训练。
Horovod的多机通信初始化是基于MPI的,通过MPI初始化通信环境和进程分配。有如下几个常用的环境参数:
size: 进程数量,也就是GPU数量;
rank:进程的唯一ID, 0-size;
local size: 每个worker的本地进程数量;
local rank: 每个worker的进程本地唯一ID。
通过这些参数来控制机器进程之间的通信。
由于训练采用的是数据并行这种模式,所以需要对数据进行分布式采样。Horovod可以直接调用pytorch自带的分布式采样函数torch.utils.data.distributed.DistributedSampler。

这种方式可以适用于简单的分布式训练任务。但是在识物的检索训练过程中,我们希望dataloader可以做一些平衡采样或者三元组采样,上面的sampler只支持分布式采样。