
微信“扫一扫”识物上线一段时间,由前期主要以商品图(鞋子/箱包/美妆/服装/家电/玩具/图书/食品/珠宝/家具/其他)作为媒介来挖掘微信内容生态中有价值的信息,扩张到各种垂类领域的识别,包括植物/动物/汽车/果蔬/酒标/菜品/地标识别等,识别核心依托于深度学习的卷积神经网络模型。随着每天千万级的增长数据和越来越多的模型参数量,深度学习训练一次时间大概需要一周左右。如何能够快速训练优化模型并上线,成为我们亟待解决的问题。
一、引言
如今,依托强大的GPU算力,深度学习得到迅猛发展。在图像处理、语音识别领域掀起了前所未有的一场革命。相较于传统的方法,以卷积神经网络(CNN)为代表的深度学习方法可以高度地重点学习数据的特性,在图像处理领域已经取得了统治地位。
随着扫一扫识物日调用量的持续增加,图片数据正以每天千万级的量级增长,在这个争分夺秒的时代里,得数据者得天下。同时,神经网络的复杂性呈爆炸式增长,像15年微软提出图像分类的ResNet模型有7 ExaFLOPs/6千万个参数,17年谷歌的神经网络机器翻译模型有100 ExaFLOPS/87亿个参数。
在大部分场景下,模型可以在一台GPU服务器上,使用一个或者多个GPU进行训练。但随着数据集的增大,训练时间也相应增长,有些时候训练需要一周甚至更长时间。因此,如何能够快速迭代优化深度学习模型,成为我们算法开发者亟须解决的问题。
下文将通过从分布式训练方法的选择、多机通信技术原理进行讲解,基于Horovod的框架在微信自研平台打通分布式训练和实验结果来介绍微信扫一扫识物中的深度学习模型分布式训练。
二、分布式训练
1. 并行方式
多机多卡相比较于单机单卡,可以将模型训练的时间大大缩短。一般我们一台服务器只支持8张GPU卡,而采用分布式的多机多卡训练方式,可以将几十甚至几百台服务器调度起来一起训练一个模型,进一步突破模型训练的上限。
按照分布式并行训练方式,分布式训练一般分为数据并行和模型并行两种。
(1)数据并行
分布式系统中不同的GPU都有同一个模型的完全拷贝,每个GPU只获得整个数据的不同部分,然后将所有GPU的神经网络梯度按照同步或者异步的方式合并。
(2)模型并行
分布式系统中每个GPU使用相同的数据,所有GPU上只分布着模型的部分内容,训练过程中交换神经网络的激活部分。
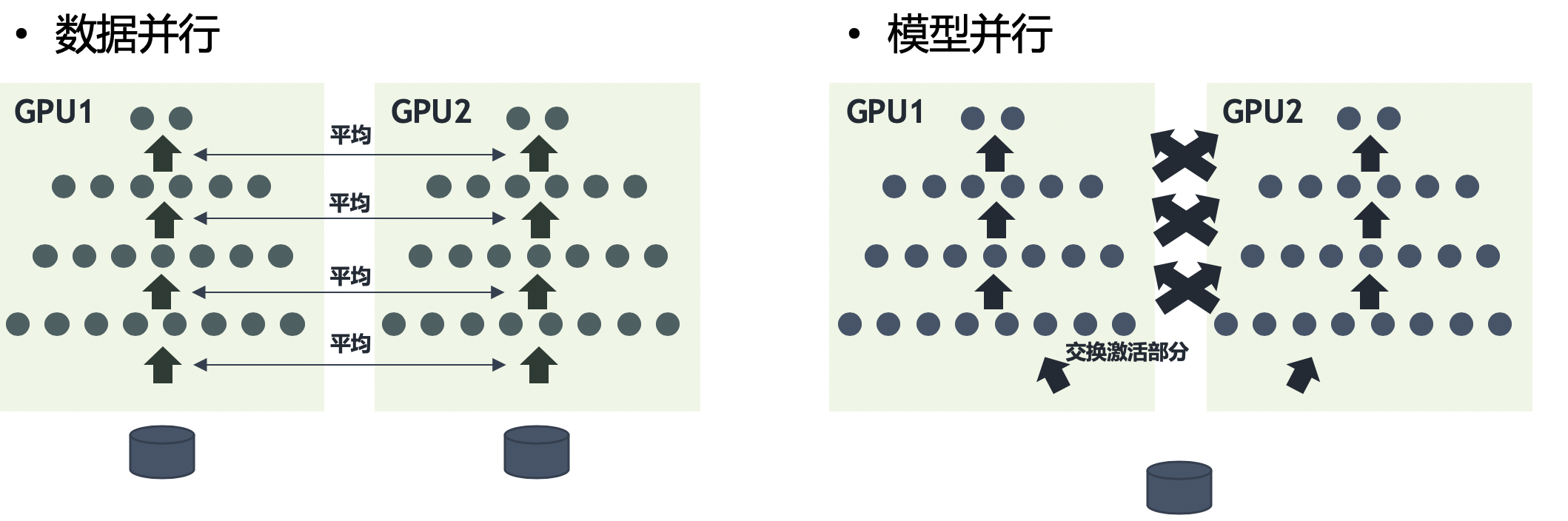
因为模型并行各个部分存在一定的依赖,不能随意增加GPU的数量,规模伸缩性差,在实际训练中用的不多。而数据并行,各部分独立,规模伸缩性好,实际训练中更为常用,提速效果也更好。在实现性、容错性和好的集群利用率上,数据并行优于模型并行。
2. 系统架构
分布式训练系统架构主要包括两种:Parameter Server Architecture(就是常见的PS架构,参数服务器)和Ring all-reduce Architecture。
(1)Parameter Server 架构
在PS架构中,集群中的节点被分为两类:parameter server和worker。其中parameter server存放模型的参数,而worker负责计算参数的梯度。
在每个迭代过程,worker从parameter sever中获得参数,然后将计算的梯度返回给parameter server,parameter server聚合从worker传回的梯度,然后更新参数,并将新的参数广播给worker。
(2)Ring all-reduce 架构
在Ring all-reduce架构中,各个设备都是worker,并且形成一个环,没有中心节点来聚合所有worker计算的梯度。在一个迭代过程,每个worker完成自己的mini-batch训练,计算出梯度,并将梯度传递给环中的下一个worker,同时它也接收从上一个worker的梯度。对于一个包含N个worker的环,各个worker需要收到其它N-1个worker的梯度后就可以更新模型参数。
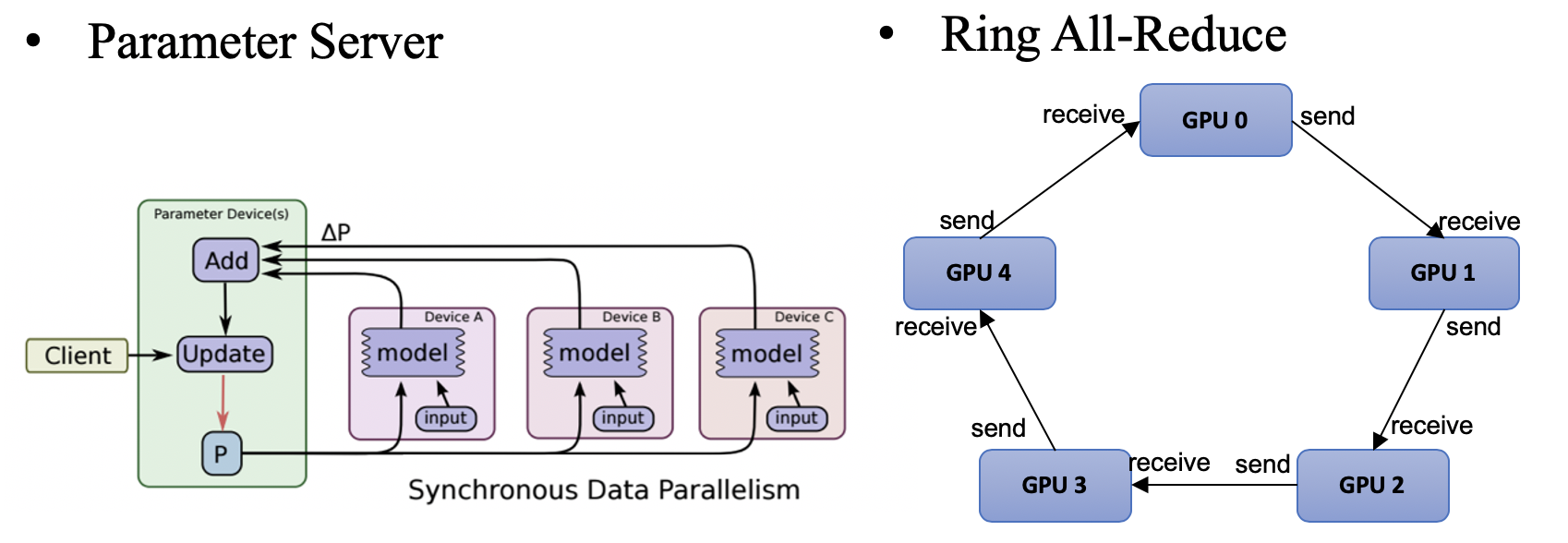
采用PS计算模型的分布式,通常会遇到网络的问题,随着worker数量的增加,其加速比会迅速的恶化。相比PS架构,Ring all-reduce架构网络通信量不随着worker(GPU)的增加而增加,是一个恒定值,集群中每个节点的带宽都被充分利用。
3. 参数更新
(1)同步更新
所有 GPU 在同一时间点与参数服务器交换、融合梯度。在每轮训练的时候需要汇总所有 worker训练得到的梯度值,然后取平均值来更新参数服务器上的模型参数。
(2)异步更新