
HTTP协议中通过如下两个首部来描述和控制传输编码:
字段 含义 典型值Transfer-Encoding 发送方告知接收方,我方已经进行了何种传输编码 chuncked 分块编码
TE 请求方告知服务器可以用哪种传输编码 trailers, chuncked 接受分块编码,并且愿意接受在报文结尾上的拖挂
分块编码的报文形式是这样的:
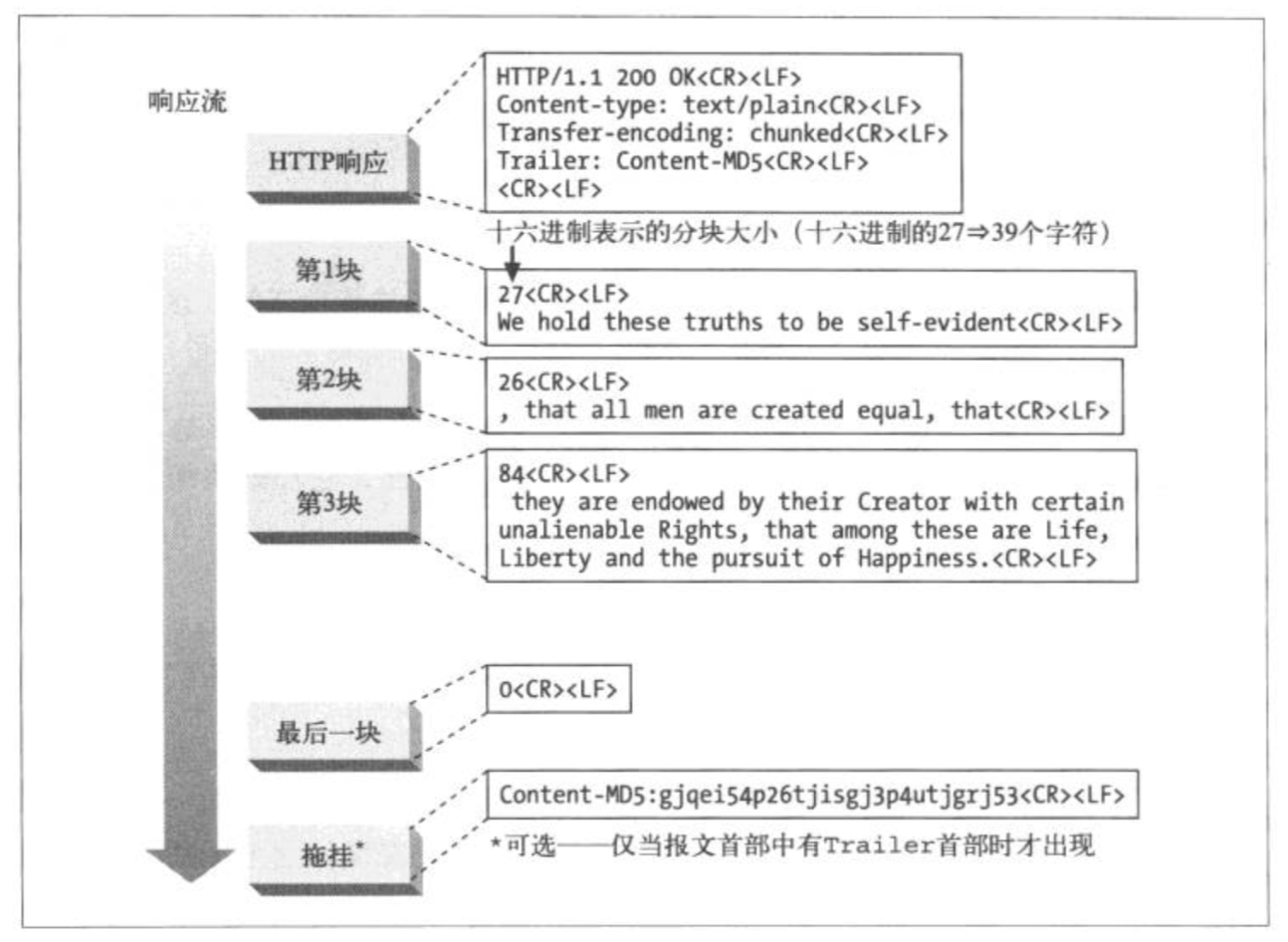
每个分块包含一个长度值(十六进制,字节数)和该分块的数据。<CR><LF>用于区隔长度值和数据。长度值不包含分块中的任何<CR><LF>序列。最后一个分块,用长度值0来表示结束。注意看报文首部包含一个Trailer: Content-MD5, 所以在紧跟着最后一个报文结束之后,就是一个拖挂。其他如,Content-Length, Trailer, Transfer-Encoding也可以作为拖挂。
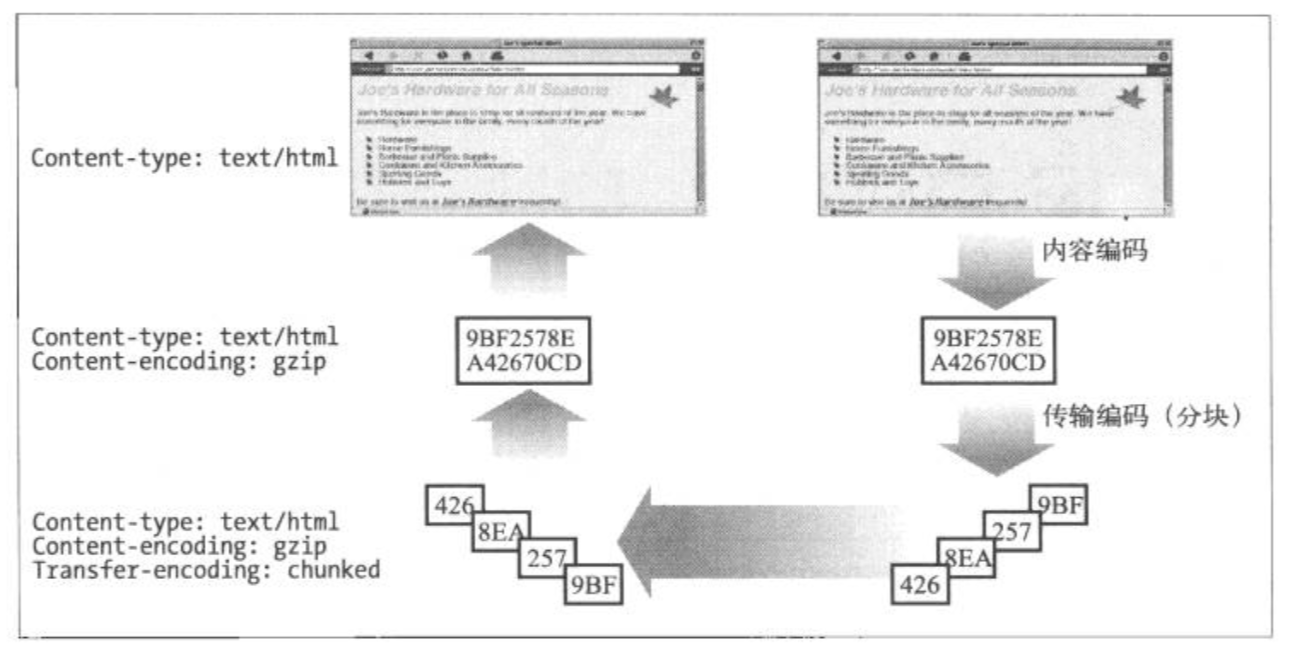
内容编码和传输编码是可以结合起来使用的。
HTTP为了支持国际化的内容,客户端要告知服务器自己能理解的何种语言,浏览器上安装了何种字母表编码算法。这通过Accept-Charset和Accept-Language首部实现。
比如:
Accept-Language: fr, en;q=0.8 Accept-Charset: iso-8859-1, utf-8表示:客户端接受法语(优先级默认为1.0)、英语(优先级为0.8),支持iso-8859-1, utf-8两种字符集编码。服务器则会在Content-Type首部里放上charset.
本质上,HTTP报文的body部分存放的就是一串二进制码,我们先把二进制码转换成字符代码(如ascii是一个字节表示一个字符,而utf-8则表示一个字符的字节数不定,每个字符1~6个字节),之后,用字符代码支字符集中找到对应的元素。
比较常见的字符集是US-ASCII: 这个字符集是所有字符集的始祖,早在1968年就发布了标准。ASCII码的代码值从0到127, 只需要7个bit位就可以覆盖代码空间。HTTP报文的首部、URL使用的字符集就是ASCII码。
US-ASCII是把每个字符编码成固定的7位二进制值。UTF-8则是无固定的编码方案。第一个字节的高位用来表示编码后的字符所用的字节数(如果所用的字节数是5,则第一个字节前5bit都是1,第6bit是0),所需的后续的字节都含有6位的代码值。
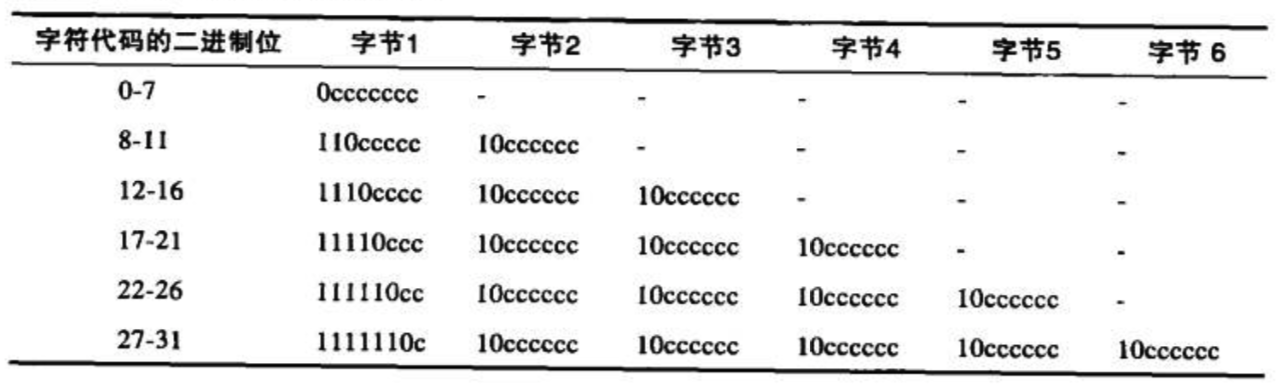
举个例子,汉字“严”的Unicode编码为4E25(100111000100101), 共有15位,落在上表中的第三行,因此“严”的编码就需要三个字节。将100111000100101填入上表中的c位即可。因此,严的UTF-8编码是11100100 10111000 10100101,转换成十六进制就是E4B8A5. 比如我在谷歌搜索框里搜索“严”字,google发出的请求如下:
https://www.google.com.hk/search?q=%E4%B8%A5&oq=%E4%B8%A5&aqs=chrome..69i57j0l5.3802j0j4&sourceid=chrome&ie=UTF-8&gws_rd=crq=%E4%B8%A5这个就是搜索的词了。
重点向与负载均衡Web内容通常分散地分布在很多地方,这可以防止“单点故障”,万一某个地方发生地震了,机房被毁了,那还有其他地方的机房可以提供服务。所谓狡兔三窟嘛。
这样,用户的请求会根据负载均衡的原则,被重定向到它应该去的地方。
HTTP重定向服务器收到客户端请求后,向客户端返回一条带有状态码302重定向的报文,告诉他们应该去其他的地方试试。web站点将重定向看成一种简单的负载均衡策略来使用,重定向服务器找到可用的负载最小的机器,由于服务器知道客户端的地址,理论上来说,可以做到最优的重定向选择。
当然,缺点也是显而易见的,由于客户端要发送两次请求,因此增加耗时。
DNS重定向DNS将几个IP地址关联到一个域上,采用算法决定返回的IP地址。可以是简单的轮转;也可以是更高级的算法,返回负载最轻的服务器的IP地址,称为负载均衡算法;如果考虑地理位置,并返回给客户端最近位置的地址,称为邻接路由算法;还有一种是绕过出现故障的地址,称为故障屏蔽算法。
DNS服务器总是会返回所有的IP地址,但是DNS客户端一般只会使用第一个IP地址,而且会缓存下来,之后会一直用这个地址。所以,DNS轮转通常不会平衡单个客户端的负载。但是,由于DNS服务器对于不同的请求,总是会返回轮转后的IP地址列表,因此,会把负载分散到多个客户端。
HTTP连接HTTP连接是HTTP报文传输的关键通道。
并行连接