
对于一个页面上同时出现多个对象的时候,如果浏览器并行地打开多个连接,同时去获取这些对象,多个连接的TCP握手时延可以进行重叠,看起来速度会快起来。
如一个包含3张图片的页面,浏览器要发送4次HTTP请求来获取页面。1个用于顶层的HTML页面,3个用于图片。如果采用串行方式,那么连接时延会进行叠加。
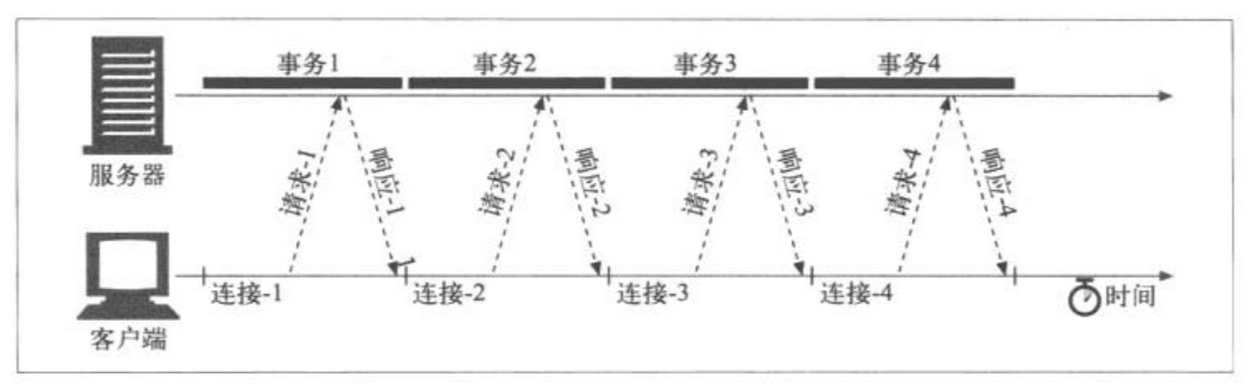
采用并行连接之后:

但是并行连接也不绝对提升速度,如果一个页面有数百个内嵌对象,那要启动数百个连接,对服务器的性能也是非常大的挑战。所以,通常浏览器会限制并行连接的总数据在一个较小的值,通常是4个,而且服务端可以随意关闭客户端超量的连接。
另一方面,如果客户端网络带宽较小,每个连接都会去争抢有限的带宽,每个连接都会获取较小的速度,即每个对象都会以较小的速度去加载。这样,并行连接带来的速度提升就会比较小,甚至没有提升。
持久连接HTTP keep-alive机制
我们知道HTTP请求是“请求-应答”模式,每次请求-应答都要新建一个连接,完成之后要断开连接。HTTP是无状态的,连接之间没有任何关系。
HTTP是应用层协议,TCP是传输层协议。HTTP底层仍然采用TCP进行传输数据。TCP为HTTP提供了一层可靠的比特传输通道。HTTP一般交换的数据都不大,而每次连接都要进行TCP三次握手,很大一部分时间都消耗在这上面,有时候甚至能达到50%。如果能复用连接,就可以减少由于TCP三次握手所带来的时延。
HTTP 1.1默认开启keep-alive机制,从上面抓到的包也可以看到。这样,数据传输完成之后保持TCP连接不断开,之后同域名下复用连接,继续用这个通道传输数据。服务器在响应一个请求后,可以保持这个连接keep-alive timeout的时间,在这个时间内没有请求,则关闭此连接;否则,重新开始倒计时keep-alive timeout时间。
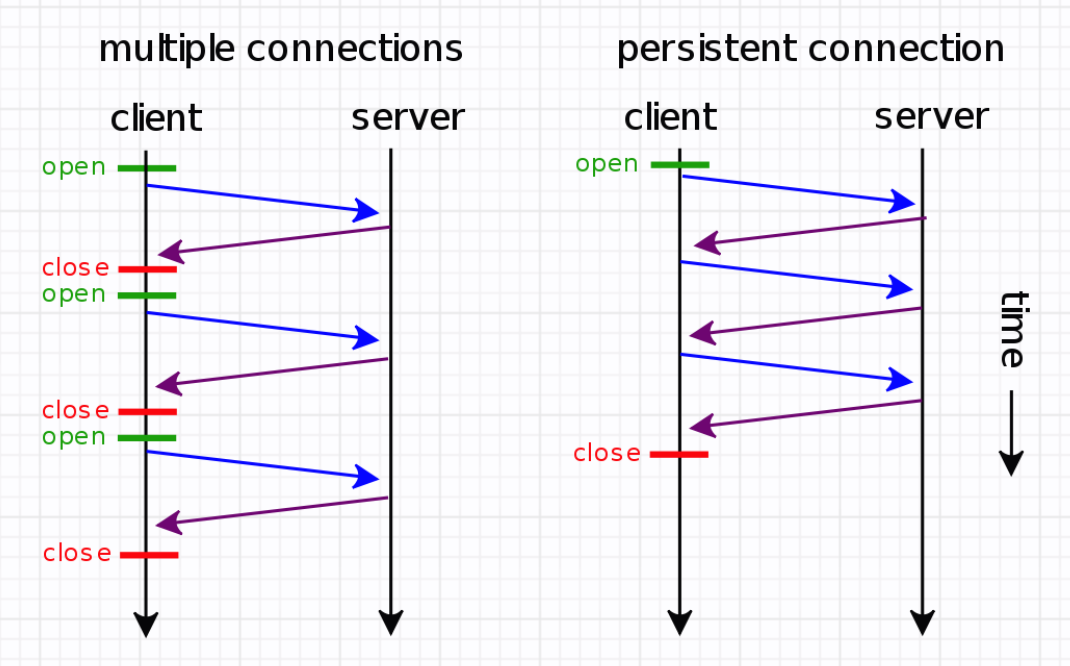
HTTP有keep-alive机制,目的是可以在一个TCP
连接上传输多个HTTP事务,以此提高通信效率。底层的TCP其实也有keep-alive机制,它是为了探测TCP连接的活跃性。TCP层的keepalive可以在任何一方设置,可以是一端设置、两端同时设置或者两端都没有设置。新建socket的时候需要设置,从而使得协议栈调用相关函数tcp_set_keepalive,来激活连接的keep-alive属性。
当网络两端建立了TCP连接之后,闲置(双方没有任何数据流发送往来)时间超过tcp_keepalive_time后,服务器内核就会尝试向客户端发送侦测包,来判断TCP连接状况(有可能客户端崩溃、强制关闭了应用、主机不可达等等)。如果没有收到对方的回答(ack包),则会在 tcp_keepalive_intvl后再次尝试发送侦测包,直到收到对方的ack,如果一直没有收到对方的ack,一共会尝试 tcp_keepalive_probes次,每次的间隔时间在这里分别是15s, 30s, 45s, 60s, 75s。如果尝试tcp_keepalive_probes次后,依然没有收到对方的ack包,则会丢弃该TCP连接。TCP连接默认闲置时间是2小时,一般设置为30分钟足够了。
管道化连接在keep-alive的基础上,我们可以做地更进一步,在响应到达之前,我们将多条请求放入请求队列,服务端在收到请求后,必须按照顺序对应请求的响应。但由于网络环境非常复杂,因此即使请求是按顺序发送的,也不一定是按顺序到达服务端的。所以最好是在响应中附带一些可以标识请求的参数。
为了安全起见,管道化的连接只适合“幂等”的请求,一般我们认为:GET/HEAD/PUT/DELETE/TRACE/OPTIONS等方法都是幂等的。
小结以上,就是所有HTTP的通信细节了。其实比较简单,更多的细节可以在用到的时候再去仔细研究。
不知道你对HTTP的理解有没有更上一层楼?欢迎一起交流探讨。
