
经常听到 Java 性能不如 C/C++ 的言论,也经常听说 Java 程序需要预热,那么其中主要原因是啥呢?
面试的时候谈到 JVM,也有很多面试官喜欢问,为啥 Java 程序越执行越快呢?
一般人都能回答上来,类加载,缓存预热等等,但是深入下去,最重要的却没有答上来,今天本系列文章就来帮助大家理解这个问题的关键。本篇文章是 TLAB 预热。
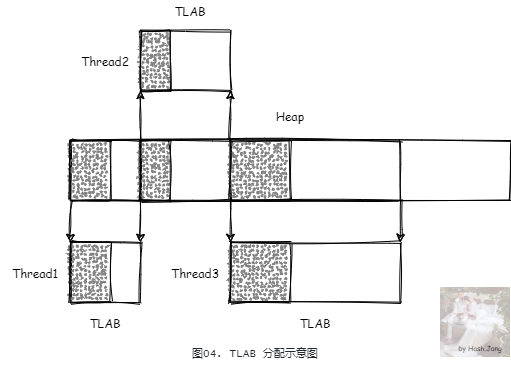
TLAB(Thread Local Allocation Buffer)线程本地分配缓存区,这是一个线程专用的内存分配区域。
既然是一个内存分配区域,我们就先要搞清楚 Java 内存大概是如何分配的。
我们这里不考虑栈上分配,这些会在 JIT 的章节详细分析,我们这里考虑的是无法栈上分配需要共享的对象。
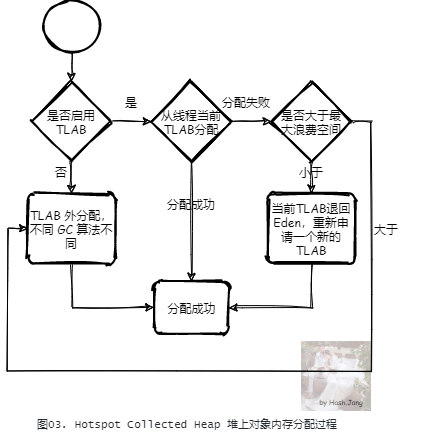
对于 HotSpot JVM 实现,所有的 GC 算法的实现都是一种对于堆内存的管理,也就是都实现了一种堆的抽象,它们都实现了接口 CollectedHeap。当分配一个对象堆内存空间时,在 CollectedHeap 上首先都会检查是否启用了 TLAB,如果启用了,则会尝试 TLAB 分配;如果当前线程的 TLAB 大小足够,那么从线程当前的 TLAB 中分配;如果不够,但是当前 TLAB 剩余空间小于最大浪费空间限制(这是一个动态的值,我们后面会详细分析),则从堆上(一般是 Eden 区) 重新申请一个新的 TLAB 进行分配。否则,直接在 TLAB 外进行分配。TLAB 外的分配策略,不同的 GC 算法不同。例如G1:
如果是 Humongous 对象(对象在超过 Region 一半大小的时候),直接在 Humongous 区域分配(老年代的连续区域)。
根据 Mutator 状况在当前分配下标的 Region 内分配
这里,我们先只关心 TLAB 分配。
对于单线程应用,每次分配内存,会记录上次分配对象内存地址末尾的指针,之后分配对象会从这个指针开始检索分配。这个机制叫做 bump-the-pointer (撞针)。
对于多线程应用来说,内存分配需要考虑线程安全。最直接的想法就是通过全局锁,但是这个性能会很差。为了优化这个性能,我们考虑可以每个线程分配一个线程本地私有的内存池,然后采用 bump-the-pointer 机制进行内存分配。这个线程本地私有的内存池,就是 TLAB。只有 TLAB 满了,再去申请内存的时候,需要扩充 TLAB 或者使用新的 TLAB,这时候才需要锁。这样大大减少了锁使用。
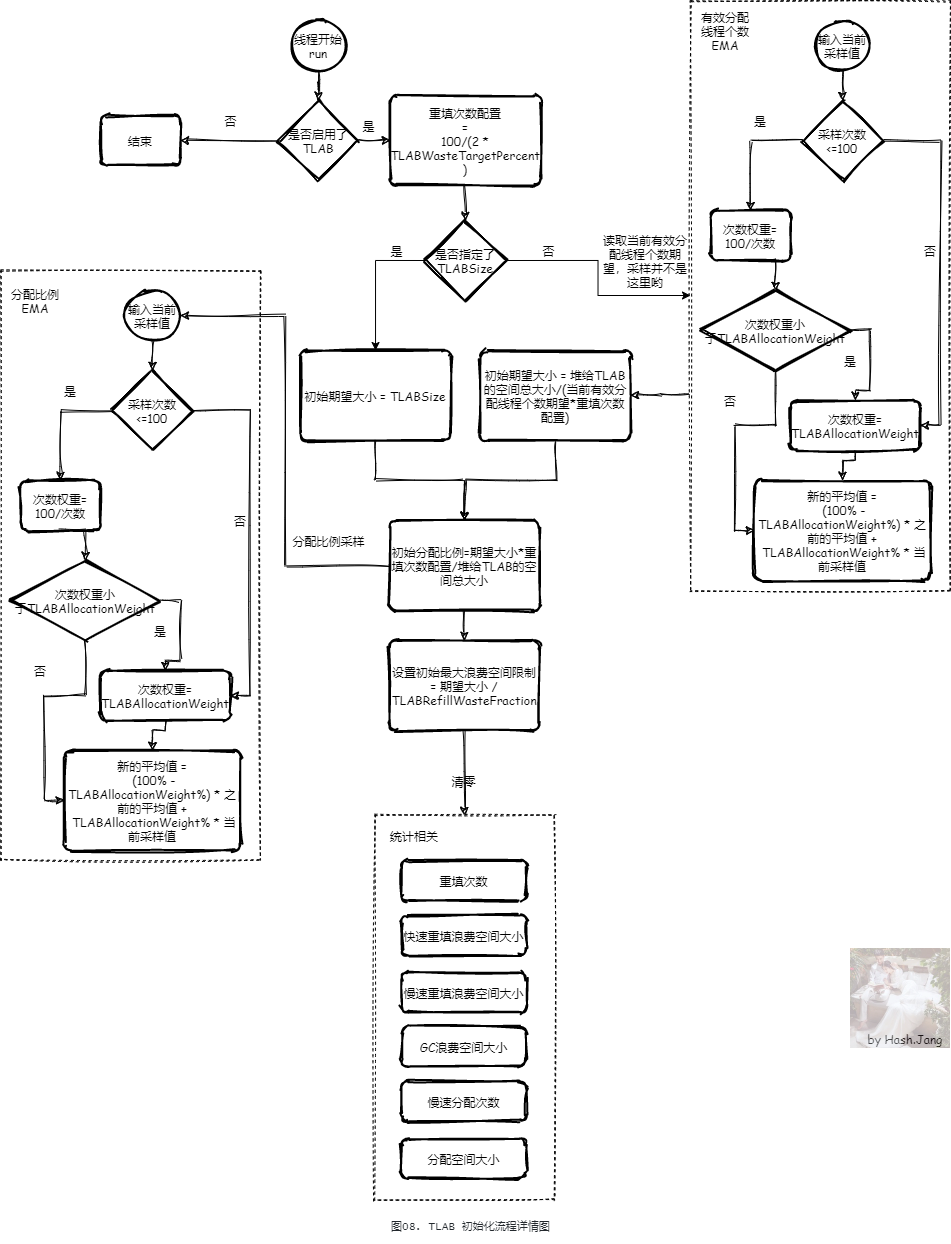
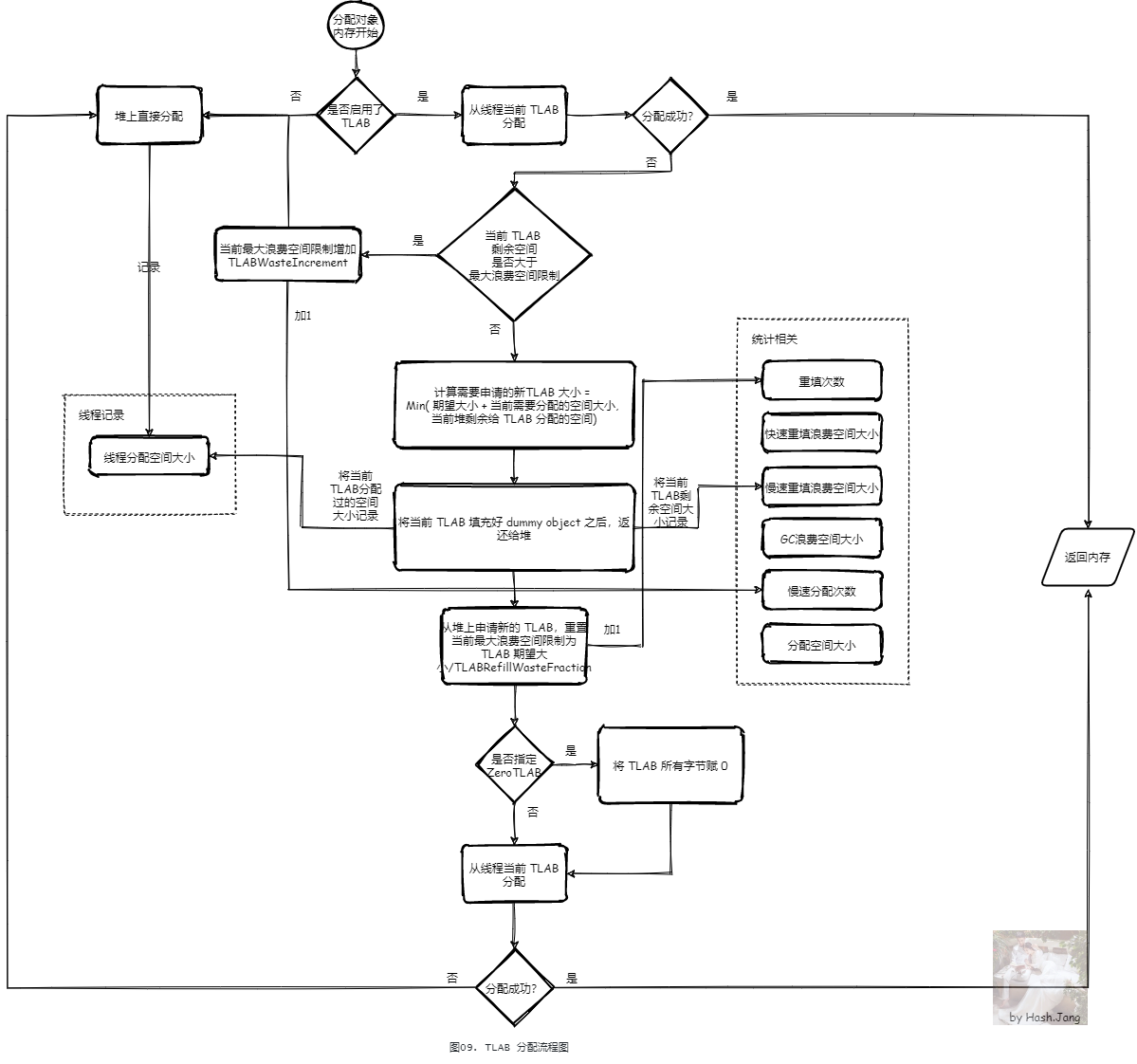

根据之前的分析,每个线程的 TLAB 的大小,会根据线程分配的特性,不断变化并趋于稳定,大小主要是由分配比例 EMA 决定,但是这个采集是需要一定运行次数的。并且 EMA 的前 100 次采集默认是不够稳定的,所以 TLAB 大小也在程序一开始的时候变化频繁。当程序线程趋于稳定,运行一段时间后, 每个线程 TLAB 大小也会趋于稳定并且调整到最适合这个线程对象分配特性的大小。这样,就更接近最理想的只有 Eden 区满了才会 GC,所有 Eden 区的对象都是通过 TLAB 分配的高效分配情况。这就是 Java 代码越执行越快在 TLAB 方面的原因。
每日一刷,轻松提升技术,斩获各种offer:
