
摘要:本文简单介绍一下什么是统计信息、统计信息记录了什么、为什么要收集统计信息、怎么收集统计信息以及什么时候收集统计信息。 1 WHY:为什么需要统计信息 1.1 query执行流程
下图描述了GaussDB的SQL引擎从接收客户端SQL语句到执行SQL语句需要经历的关键步骤,以及各个流程中可能对执行产生影响的因素
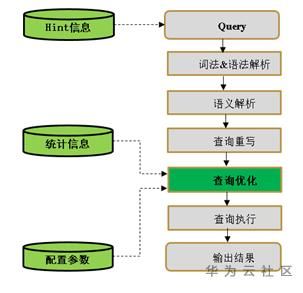
1) 词法&语法解析
按照约定的SQL语句规则,把输入的SQL语句从字符串转化为格式化结构(Stmt),如果SQL语句存在语法错误,都会在这个环节报错。
2) 语义解析
语义解析类似一个翻译器,把外部输入的可视化的对象翻译为数据库内部可识别的对象(比如把Stmt中以字符串记录的表名称转化为数据库内部可识别的oid),如果语句存在语义错误(比如查询的表对象不存在),数据库会在这个环节报错。
3) 查询重写
根据规则将“语义解析”的输出等价转化为执行上更为优化的结构,比如把查询语句中的视图逐层展开至最低层的表查询。
4) 查询优化
数据库确认SQL执行方式、生成执行计划的过程
5) 查询执行
根据执行计划执行SQL并输出结果的过程
整个执行流程中,优化器决定了查询语句的具体执行方式,对SQL语句的性能起着关键性的作用。数据库查询优化器分为两类:基于规则的优化器(Rule-Based Optimizer,RBO) 和基于代价的优化器(Cost-Based Optimizer,CBO)。RBO是一种基于规则的优化,对于指定的场景采用指定的执行方式,这种优化模型对数据不敏感;SQL的写法往往会影响执行计划,不了解RBO的细则的人员开发的SQL性能不可控,因此RBO逐渐被抛弃,目前GaussDB等数据库厂商的优化器都是CBO模型。CBO模型是根据SQL语句生成一组可能被使用的执行计划,并估算出每种执行计划的代价,最终选择选择一个代价最小的执行方式。
1.2 CBO模型数据库执行SQL语句的时候,会把执行拆分为若干步骤,如下SQL
select * from t1 join t2 on t1.a=t2.b where t1.b = 2 and t2.a = 3;