
通俗来讲:递归就是方法自己调用自己,通过每次传入的参数不同,可以解决复杂的问题。
为什么需要递归递归算法可以把本身问题分解规模小的同类问题,通过求解规模小的同类问题的解,之后不断进行返回值,最终可以求得规模大的问题。
来看看递归的优缺点: 优点 缺点1. 逻辑性好;2. 可读性好;3.代码简洁。 1. 由于递归需要利用栈,所以占用空间大,可能会发生栈溢出;2. 会存在重复计算,需要进行优化。
递归的三大要素
第一要素: 明确你这个函数想要干什么。先不管函数里面的代码什么,而是要先明白,你这个函数的功能是什么,要完成什么样的一件事。
第二要素: 寻找递归结束条件。我们需要找出当参数为啥时,递归结束,之后直接把结果返回,请注意,这个时候我们必须能根据这个参数的值,能够直接知道函数的结果是什么。
第三要素: 找出函数的等价关系式。我们要不断缩小参数的范围,缩小之后,我们可以通过一些辅助的变量或者操作,使原函数的结果不变。
递归的过程上面的递归的过程比较抽象,接下来自己慢慢讲:
需要了解的知识点栈:栈是一种数据结构,可以实现先进后出的功能。我们写的程序需要调用线程来执行,如下图,通过查看JVM的内存管理模型,可以知道虚拟机栈是线程私有的,其中虚拟机栈的作用就是每次方法调用的数据需要通过栈来传递。
利用阶乘问题讲解递归的调用机制:
class Solution{ public static void main(String[] args){ int res = factorial(3); } //第一步,明确函数的功能 public static int factorial(int n){ //第二步,递归的结束条件 if(n == 1){ return 1; }else{ //第三步,函数的等价关系式 return factorial(n - 1) * n; } } }图解:方法递归时,实际内存运行过程。
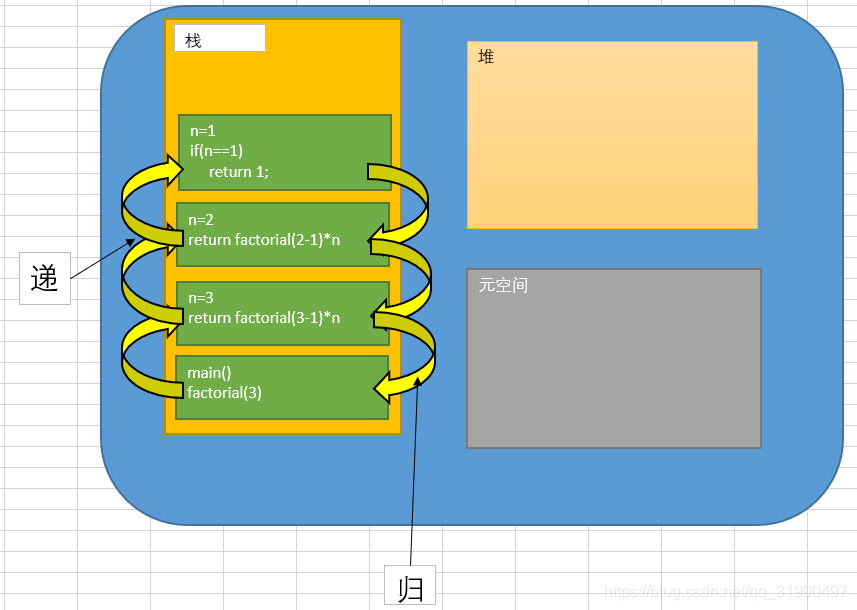
执行一个方法时,就会创建一个新的独立栈空间。
方法的局部变量是独立的,不会相互影响,比如程序中的变量n。
如果方法中使用的是引用类型的变量(比如数组),就会共享该引用类型的数据。
递归必须要向退出递归的条件逼近,否则就会无限递归,会出现StackOverflowError。
当一个方法执行完毕,或者遇到return,就会返回,遵循谁调用,就将结果返回给谁。
实例2:利用递归反转链表反转链表,如对链表1->2->3->4 进行反转为4->3->2->1。
首先定义链表的节点
class Node{ int val; Node next; }按照递归的三要素来
第一步:定义函数的功能
设函数reverseLinkedList(head)的功能是反转链表,其中head表示链表的头节点。
Node reverseLinkedList(Node head){ }第二步:递归的结束条件
当链表没有节点或只有一个节点时,此时不用进行反转,这个作为递归的结束条件。
Node reverseLinkedList(Node head){ if(head == null || head.next == null){ return head; } }第三步:寻找等价条件
这个有一定的难度,根据需要遵守的规则,在找等价条件的过程中,一定是要逼近递归的结束条件。
Node reverseLinkedList(Node head){ if(head == null || head.next == null){ return head; } //不断去移动指针,不断去逼近结束条件。 Node newList = reverseLinkedList(head.next); }根据上述求阶乘的例子,可以知道此时的内存运行过程,通过不断地移动指针(head.next),最终只用一个节点,如,通过递过程,对于1->2->3->4链表此时为:
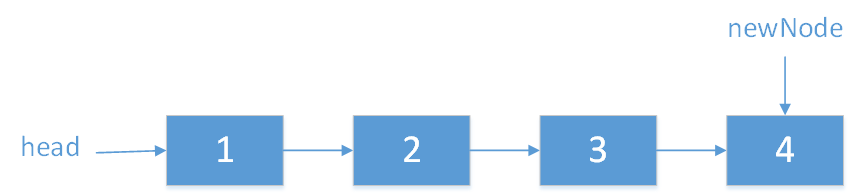
接下来就是归过程了,交换指针的指向。 //用递归的方法反转链表 public static Node reverseList2(Node head){ // 1.递归结束条件 if (head == null || head.next == null) { return head; } // 递归反转 子链表 Node newList = reverseList2(head.next); // 改变 3,4节点的指向。 // 通过 head.next获取节点4 Node t1 = head.next; // 让 4 的 next 指向 4 t1.next = head; // 3 的 next 指向 null. head.next = null; // 把调整之后的链表返回。 return newList; }