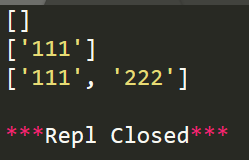
import re #匹配数字 r=re.compile(r'\d+') r1=r.findall('This is a demo') r2=r.findall('This is 111 and That is 222',0,11) r3=r.findall('This is 111 and That is 222',0,27) print(r1) print(r2) print(r3)
运行功效:
re.finditer函数
和 findall 雷同,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
re.finditer(pattern, string, flags=0)
pattern:匹配的正则表达式。
string:待匹配的字符串。
flags:符号位,用于节制正则表达式的匹配方法,如是否区分巨细写,多行匹配等。
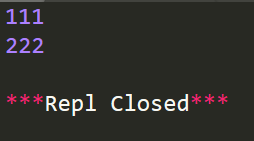
import re r=re.finditer(r'\d+','This is 111 and That is 222') for i in r: print (i.group())
运行功效:
re.split函数
将一个字符串凭据正则表达式匹配的子串举办支解后,以列表形式返回。
re.split(pattern, string[, maxsplit=0, flags=0])
pattern:匹配的正则表达式。
string:待匹配的字符串。
maxsplit:支解次数,maxsplit=1支解一次,默认为0,不限次数。
flags:符号位,用于节制正则表达式的匹配方法,如:是否区分巨细写,多行匹配等。
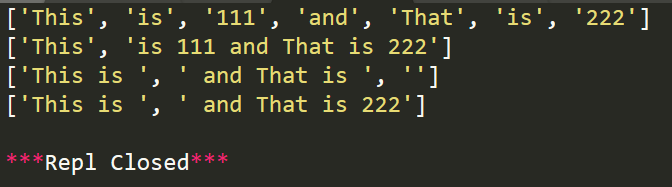
import re r1=re.split('\W+','This is 111 and That is 222') r2=re.split('\W+','This is 111 and That is 222',maxsplit=1) r3=re.split('\d+','This is 111 and That is 222') r4=re.split('\d+','This is 111 and That is 222',maxsplit=1) print(r1) print(r2) print(r3) print(r4)
运行功效:
re.sub函数
re.sub函数用于替换字符串中的匹配项。
re.sub(pattern, repl, string, count=0, flags=0)
pattern:正则中的模式字符串。
repl:替换的字符串,也可为一个函数。
string:要被查找替换的原始字符串。
count:模式匹配后替换的最大次数,默认0暗示替换所有的匹配。
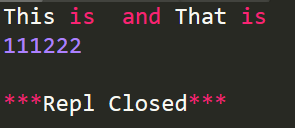
import re r='This is 111 and That is 222' # 删除字符串中的数字 r1=re.sub(r'\d+','',r) print(r1) # 删除非数字的字符串 r2=re.sub(r'\D','',r) print(r2)
运行功效:
参考资料:
到此这篇关于Python常用的正则表达式处理惩罚函数详解的文章就先容到这了,更多相关python 正则表达式处理惩罚函数内容请搜索剧本之家以前的文章或继承欣赏下面的相关文章但愿各人今后多多支持剧本之家!
您大概感乐趣的文章: