首先我们打开自己的织梦后台点击 采集——采集节点管理——增加新节点
这里我们以采集普通文章为例,我们选择普通文章,然后确定
我们进入了采集的设置页面,填写节点名称,就是给这个新节点取个名字,这里你可以任意填写。
然后打开你想要采集的文章列表页,这里我们以织梦官网为例打开这个页面,右键——查看源文件
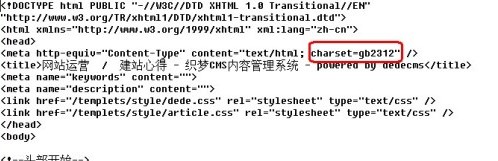
找到目标页面编码,就在charset后面
页面基本信息其他的一般就不用管了,填完了如图

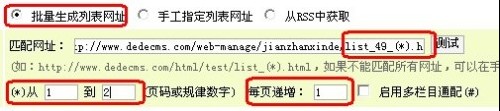
现在我们来填写列表网址获取规则
看看文章列表第一页的地址
对比第二页的地址
我们发现了他们除了49_后面的数字不一样,其他的都一样,所以我们可以这样写
(*).html
就是把1换成了(*) 因为这里只有2页,所以我们就填从1到2 每页递增当然是1了,2-1...是等于1吧
这里我们就填写完了
可能大家采集的有些列表没有规则,那就只有手工指定列表网址了,如图
每行写一个页面地址
列表规则写完了,我们就开始写文章网址匹配规则了,回到文章列表页
右键查看源文件 找到区域开始的HTML,就是找文章列表开始的标志。
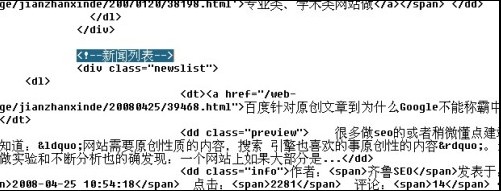
我们很容易的找到了如图中的“新闻列表” 。从这里开始,后面就是文章列表里
我们再找文章列表结束的HTML
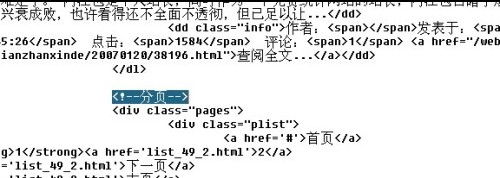
就是这个了,一个很容易找到的标志
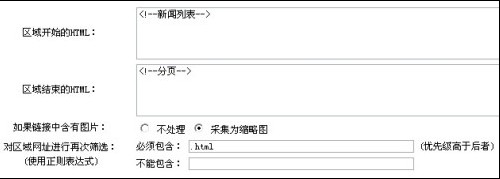
如果链接中含有图片: 不处理 采集为缩略图 这里根据自己的需要选择
对区域网址进行再次筛选:
(使用正则表达式)
必须包含: (优先级高于后者)
不能包含:
打查看文件,我们可以很清楚的看到,文章链接都是以.html结束的
所以,我们在必须包含后面填.html 如果遇到有些列表很麻烦,还可以填写后面的不能包含
我们点击保存设置进入下一步,可以看到我们获得的文章网址
看到这些就是对的了,我们保存信息进入下一步设置内容字段获取规则
我们看看文章有没有分页,随便进入一篇文章看看。。我们看到这里的文章没有分页
所以这里的我们就默认了

我们现在来找文章标题等等 随便进入一篇文章,右键查看源文件
看看这些
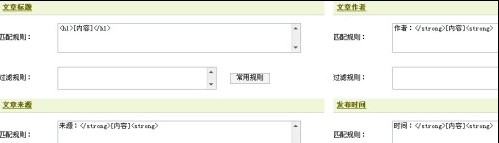
依照源码填写
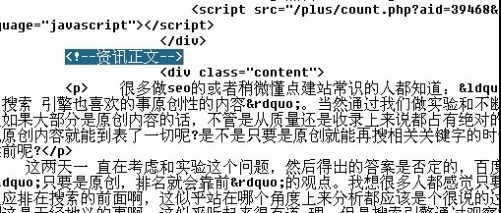
我们再来填写文章内容的开始,结束
和上面的一样,找到开始和结束标志
开始

结束
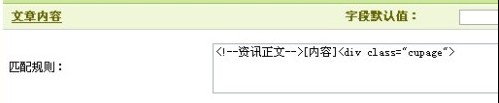
你想过滤文章中的什么内容就到过滤规则里写吧,比如要过滤文章中的图片
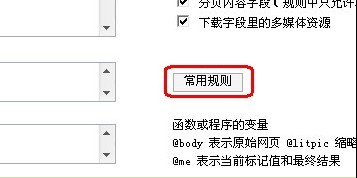
选择常用规则
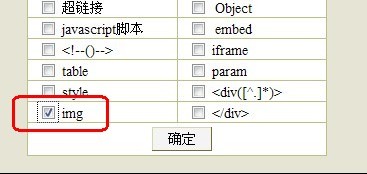
再勾选IMG 然后确定
这样我们就把正文中的图片过滤了
设置完毕后点保存设置并预览

这样一个采集规则就写好了,很简单吧有些网站很难写,可要多下点功夫了哦
我们点保存并开始采集——开始采集网页 一会的功夫就采集完了

我们看看我们采集到的文章
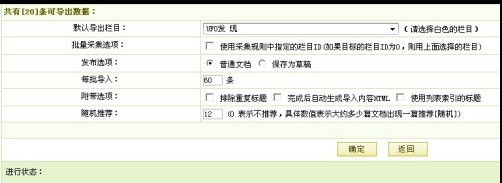
成功了,我们导出数据吧