腾讯云ES在社区开源的内核之上,根据云上的内外部业务的场景案例积累,做了大量的内核优化。除了上面介绍的translog的优化,还有带“_id”的写入操作剪枝优化、查询计划优化等等,满足了客户在性能方面的需要,并积极将一些通用的优化提交至社区,截至目前为止,腾讯云提交的pr约有50+被合并到了主干。
2.扩容能力在疫情期间,继续沿用原有的架构很难满足快速扩容的需求,导致服务质量数据上报写入慢,数据大量堆积在队列中。腾讯云ES有着完善的分布式设计,单个集群支持扩容至数百甚至上千个节点。有可靠完备的选主算法逻辑以及sharding路由策略做保障。数据分片支持数据冗余,防止由于硬件故障导致的数据丢失,并提升集群的读性能。同时,数据可以按索引维度设置数据分片及副本数目,可以根据业务特点更灵活地设置合理的数值,降低了数据存储的成本。
腾讯云ES依托于腾讯云CVM进行构建,资源池充足,仅在疫情刚开始的一个月内就扩容了3W核,集群弹性伸缩的便利性得到了验证。扩容节点数目及变更节点配置等均为自动化功能,支持控制台及API一键操作,扩容过程平滑,不影响业务读写。
在集群扩容的场景中,相信很多业务都遇到过使用ES进行扩容后,大量新写入数据有读写热点,都堆积到新加入的节点上,导致节点被打挂,影响整个集群的写入性能。随着数据的增长,腾讯会议业务也扩容至千级节点的规模,那么上面的问题在腾讯云ES中是如何解决的呢?
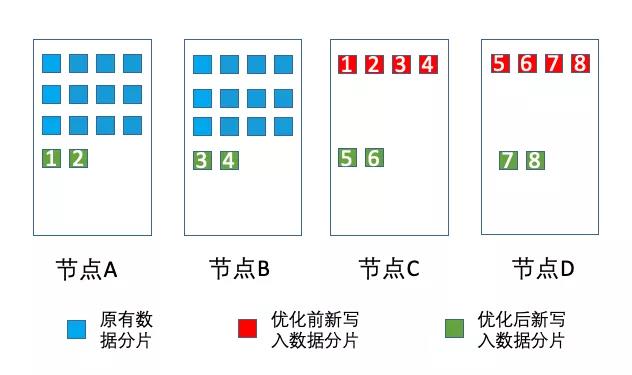
社区开源版本的ES,在shard分配的时候,会优先考虑各个节点上已有的shard数量,目的是尽量保持各个节点的shard和数据的均衡。当集群数据在各节点之间已经处于balance状态时,这时候增加新节点。由于新节点上面的shard数最少,就会造成上面的问题,新写入的数据都分配在新的节点上,造成新的节点压力过高而宕机。
为了帮助客户解决上述问题,腾讯云ES内核团队在原有allocationDecider责任链基础上,开发了一个新的decider分配算法,将一个index的所有分片,尽量平均地分配在各个节点上,使得新写入数据的读写流量被均匀分担,避免了新写入数据的访问热点。
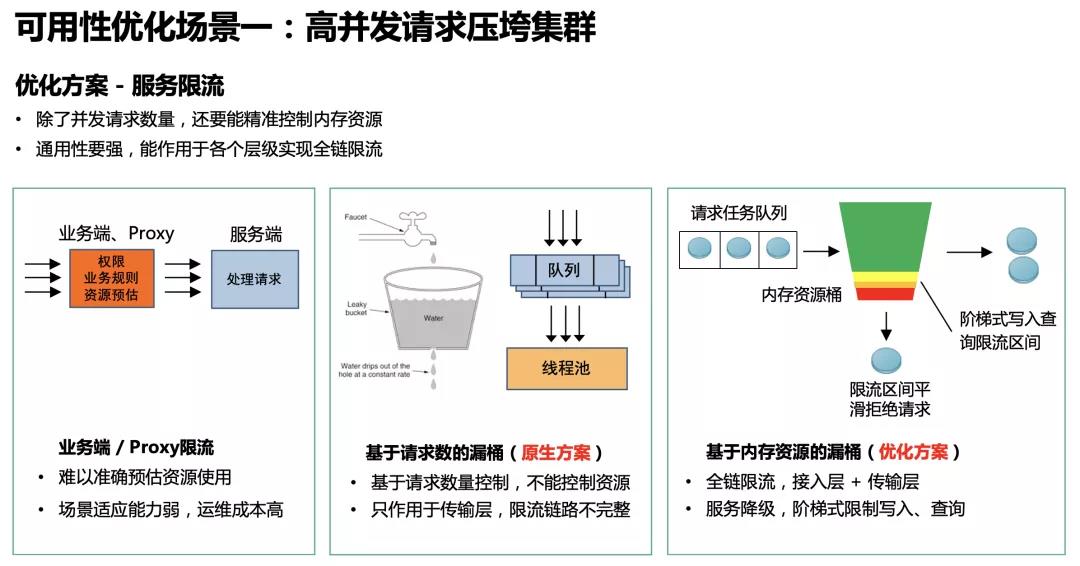
3. 稳定性腾讯会议服务质量分析系统,从2月份进行ES架构的方案切换开始,写入吞吐从5w/s不断攀升,现已达到100w+/s。业务的突发增长有时候来的很突然,并不能在前期做有效的评估。社区中的很多用户也遇到过类似的问题,由于没有预估到业务突发的增长,并且在业务层没有做好服务降级等机制,导致突发的写入查询流量打崩了整个集群,使ES服务甚至整个业务长时间不可用。那么,在类似腾讯会议这样的场景中,是怎样解决ES突增写入查询流量的问题的呢?
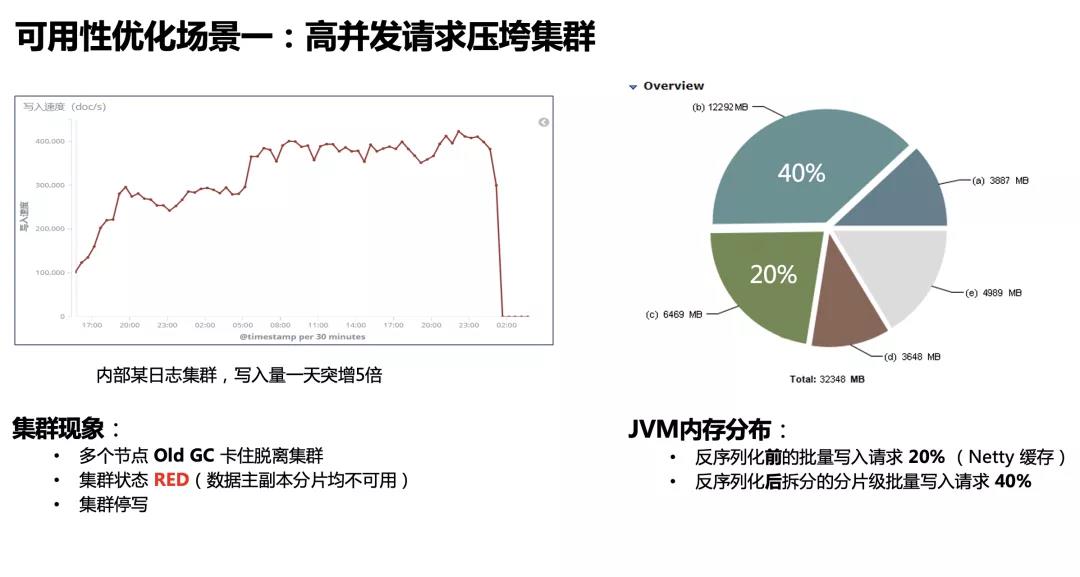
例如早期我们内部一个日志集群,写入量一天突增 5 倍,集群多个节点 Old GC 卡住脱离集群,集群 RED,写入停止,这个痛点确实有点痛。我们对挂掉的节点做了内存分析,发现大部分内存是被反序列化前后的写入请求占用。我们来看看这些写入请求是堆积在什么位置。
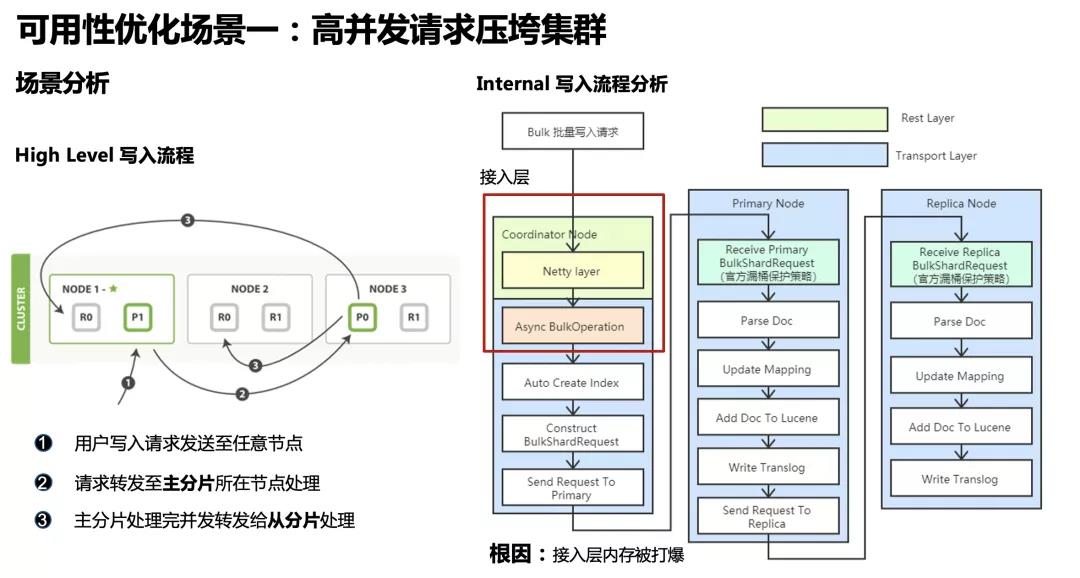
ES high level 的写入流程,用户的写入请求先到达其中一个数据节点,我们称之为数据节点。然后由该协调节点将请求转发给主分片所在节点进行写入,主分片写入完毕再由主分片转发给从分片写入,最后返回给客户端写入结果。右边是更细节的写入流程,而我们从堆栈中看到的写入请求堆积的位置就是在红色框中的接入层,节点挂掉的根因是协调节点的接入层内存被打爆。