
针对这种高并发场景,我们的优化方案是服务限流。除了要能控制并发请求数量,还要能精准地控制内存资源,因为内存资源不足是主要的矛盾。另外通用性要强,能作用于各个层级实现全链限流。
在很多数据库使用场景,会采用从业务端或者独立的 proxy 层配置相关的业务规则的限流方案,通过资源预估等方式进行限流。这种方式适应能力弱,运维成本高,而且业务端很难准确预估资源消耗。
ES原生版本本身有限流策略,是基于请求数的漏桶策略,通过队列加线程池的方式实现。线程池大小决定了处理并发度,处理不完放到队列,队列放不下则拒绝请求。但是单纯地基于请求数的限流不能控制资源使用量,而且只作用于分片级子请求的传输层,对于我们前面分析的接入层无法起到有效的保护作用。原生版本也有内存熔断策略,但是在协调节点接入层并没有做限制。
我们的优化方案是基于内存资源的漏桶策略。我们将节点 JVM 内存作为漏桶的资源,当内存资源足够的时候,请求可以正常处理;当内存使用量到达一定阈值的时候分区间阶梯式平滑限流。例如上图中浅黄色的区间限制写入,深黄色的区间限制查询,底部红色部分作为预留 buffer,预留给处理中的请求、merge 等操作,以保证节点内存的安全性。
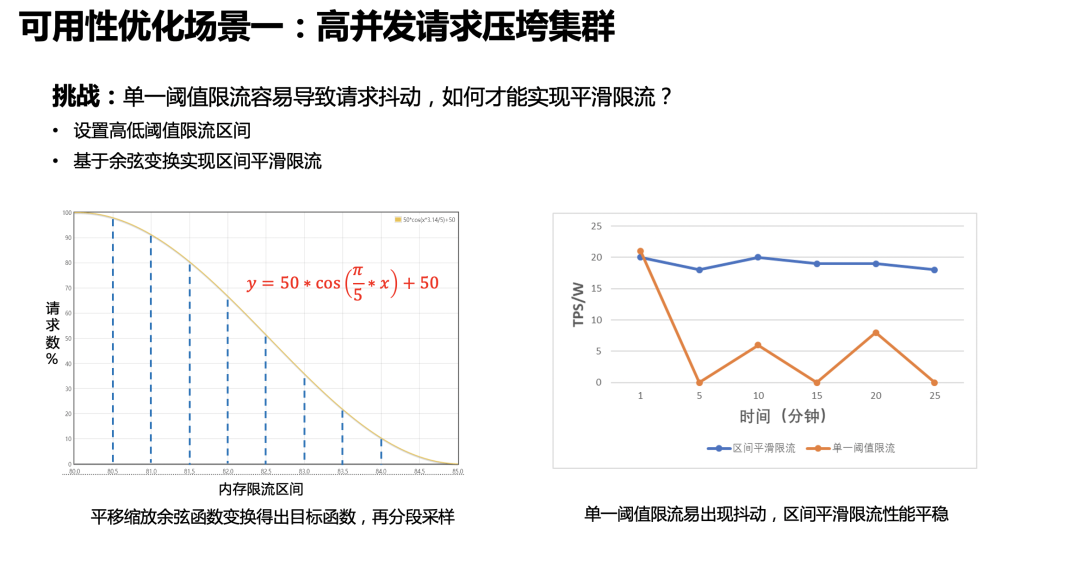
限流方案里面有一个挑战是:我们如何才能实现平滑限流?因为采用单一的阈值限流很容易出现请求抖动,例如请求一上来把内存打上去马上触发限流,而放开一点点请求又会涌进来把内存打上去。我们的方案是设置了高低限流阈值区间,在这个区间中,基于余弦变换实现请求数和内存资源之间的平滑限流。当内存资源足够的时候,请求通过率 100%,当内存到达限流区间逐步上升的时候,请求通过率随之逐步下降。而当内存使用量下降的时候,请求通过率也会逐步上升,不会一把放开。通过实际测试,平滑的区间限流能在高压力下保持稳定的写入性能。
我们基于内存资源的区间平滑限流策略是对原生版本基于请求数漏桶策略的有效补充,并且作用范围更广,覆盖协调节点、数据节点的接入层和传输层,并不会替代原生的限流方案。
4. 易用性用户数暴增,留给系统验证切换的时间非常短,这要求我们必须使用一种简单快速的解决方案。需要在一周之内输出适用方案,并进行线上数据的切换。如原架构使用kafka队列做数据的投递,由自研的消息接入服务进行消息的接入、清洗并最终写入自研的服务质量数据存储分析服务。由于时间紧迫,新的方案需要尽量保留原有架构的大部分基础设施,并做尽量少的代码开发改动。
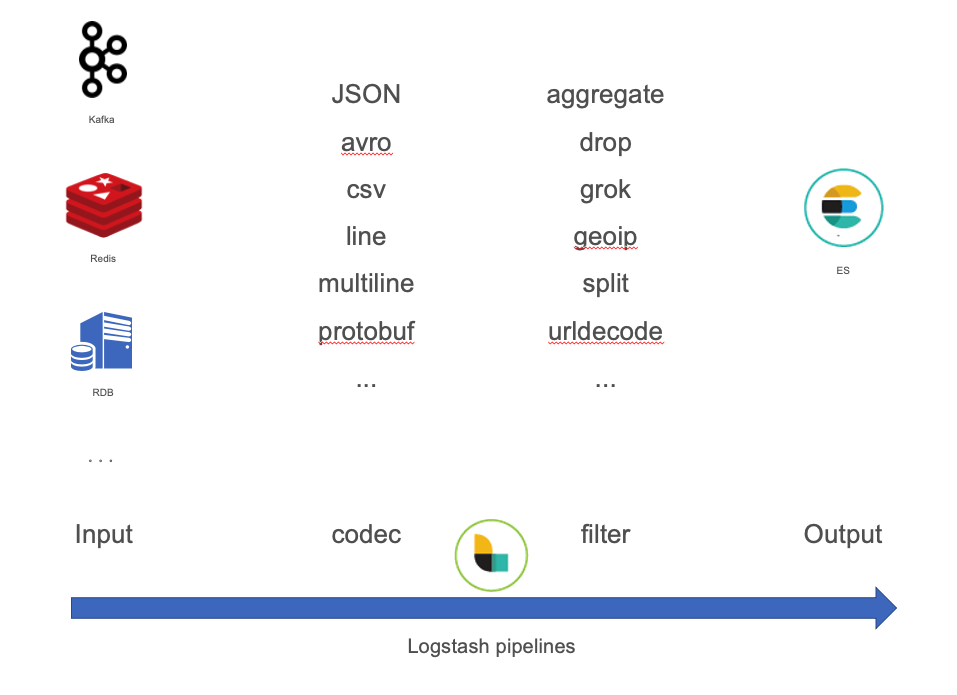
在这方面,ES的社区生态做得非常完备。从采集端、收集端到存储都有一整套解决方案。通过logstash的易用性和强大的生态插件,可以快速替代原有的自研数据接入组件,进行数据的清洗转换等ETL过程。如原有架构中使用的kafka,在logstash中就已经包含了相应的input插件。并且有大量数据格式的解析插件支持,对于数据的一些解析、过滤、清洗等操作可以直接在logstash的pipeline中进行简单的配置即可,基本上是0开发量。
丰富的各语言SDK,方便快速的对服务质量分析平台前后台进行快速切换,实际从代码修改到上线完成只用了一天的时间。同时,ES社区也比较活跃,国内有10万+的开发者参与其中,问题都可以比较快地得到回复和解决。在此,也特别感谢ES的研发团队及一线运维团队,在疫情期间,对腾讯会议进行了7*24小时的支持,并对于使用ES的一些疑难问题给出了大量的解决方案。
三、腾讯云ES高可用架构为业务提供高效稳定的读写能力在腾讯会议服务质量数据分析系统全部切换至ELK架构之后,达成了100w+/s的数据写入性能要求,数据从入队列到可被搜索到的延迟时间从小时级别缩短至了秒级,保证了业务数据同步的实时性要求以及运营分析系统的查询延迟要求。
截止到目前,腾讯会议集群随着业务的增长已平滑扩展至数百节点,百万核数规模,满足了业务数据增长下的扩容需求。
并且,得益于内核稳定性方向的大量优化,腾讯云ES的服务稳定性上达到了99.99%,保证了万亿级别数据量高压力使用场景下的服务稳定性,为腾讯会议的运营分析及问题排查保驾护航。