每天定时获取必应每日一图并保存做壁纸
必应每天会更新每日一途,这些图片都是特别好看,适合做封面壁纸等等。我做了一个自动脚本,让它每天定时获取每日一图,然后设置为个人主页博客的封面,封面和背景一共九张图片,每天更新后以队列的顺序替换。
这里是成品:个人搭建的博客主页
获取每日一图的链接 从接口获取链接必应提供了一个获取每日一图的接口,https://cn.bing.com/HPImageArchive.aspx?format=js&idx=0&n=1,访问此接口会返回一个json数据,数据如下:
{ "images": [ { "startdate":"20201116", "fullstartdate":"202011161600", "enddate":"20201117", "url":"/th?id=OHR.MischwaldFuessen_ZH-CN0005213724_1920x1080.jpg&rf=LaDigue_1920x1080.jpg&pid=hp", "urlbase":"/th?id=OHR.MischwaldFuessen_ZH-CN0005213724", "copyright":"混交林,菲森,巴伐利亚,德国 (© Erich Kuchling/DEEPOL by plainpicture)", "copyrightlink":"https://www.bing.com/search?q=%E6%B7%B7%E4%BA%A4%E6%9E%97&form=hpcapt&mkt=zh-cn", "title":"", "quiz":"/search?q=Bing+homepage+quiz&filters=WQOskey:%22HPQuiz_20201116_MischwaldFuessen%22&FORM=HPQUIZ", "wp":true, "hsh":"8df6576dae2e935290a0f48ff9ab10bb", "drk":1, "top":1, "bot":1, "hs":[] } ], "tooltips":{ "loading":"正在加载...", "previous":"上一个图像", "next":"下一个图像", "walle":"此图片不能下载用作壁纸。", "walls":"下载今日美图。仅限用作桌面壁纸。" } }上面的json数据中的images中url的value就是当天图片的地址的一半,还需要添加一个前缀https://www.bing.com/或者,两者选其一,比如今天的图片完整链接为https://www.bing.com//th?id=OHR.MischwaldFuessen_ZH-CN0005213724_1920x1080.jpg&rf=LaDigue_1920x1080.jpg&pid=hp,下载的图片格式为jpeg。
知道了图片的链接获取方法,就写一个Java程序来获取它。我们将页面的json数据一行一行读取,存入一个字符串并返回。
public static String getURLContent(String urlStr) { //请求的url URL url = null; //建立的http链接 HttpURLConnection httpConn = null; //请求的输入流 BufferedReader in = null; //输入流的缓冲 StringBuffer sb = new StringBuffer(); try{ url = new URL(urlStr); in = new BufferedReader(new InputStreamReader(url.openStream(),"UTF-8") ); String str = null; //一行一行进行读入 while((str = in.readLine()) != null) { sb.append( str ); } } catch (Exception ex) { ex.printStackTrace(); } finally{ try{ if(in!=null) { in.close(); //关闭流 } }catch(IOException ex) { ex.printStackTrace(); } } String result =sb.toString(); return result; }返回值就是上述的json数据的字符串形式,然后我们使用阿里的一个处理json数据的库来简化操作,在pom.xml文件中加入下面的依赖:
<!-- https://mvnrepository.com/artifact/com.alibaba/fastjson --> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.73</version> </dependency>利用这个工具将String类型的json数据封装成一个JSONObject,通过调用get(key)或者getString(key)获取到key对应的value,因为这个json数据里面有级联属性,所以先获取images对应的value。
//通过该链接先获取到json数据的字符串形式 String urlContent = getURLContent("http://cn.bing.com/HPImageArchive.aspx?format=js&idx=0&n=1"); //将json数据封装成json对象 JSONObject jsonObject = JSONObject.parseObject(urlContent); // 获取到key为images的值 String r = jsonObject.getString("images");这时候的r字符串就是
[ { "startdate":"20201116", "fullstartdate":"202011161600", "enddate":"20201117", "url":"/th?id=OHR.MischwaldFuessen_ZH-CN0005213724_1920x1080.jpg&rf=LaDigue_1920x1080.jpg&pid=hp", "urlbase":"/th?id=OHR.MischwaldFuessen_ZH-CN0005213724", "copyright":"混交林,菲森,巴伐利亚,德国 (© Erich Kuchling/DEEPOL by plainpicture)", "copyrightlink":"https://www.bing.com/search?q=%E6%B7%B7%E4%BA%A4%E6%9E%97&form=hpcapt&mkt=zh-cn", "title":"", "quiz":"/search?q=Bing+homepage+quiz&filters=WQOskey:%22HPQuiz_20201116_MischwaldFuessen%22&FORM=HPQUIZ", "wp":true, "hsh":"8df6576dae2e935290a0f48ff9ab10bb", "drk":1, "top":1, "bot":1, "hs":[] } ]为了方便起见,直接截取字符串的1到r.length()-1的内容,继续将其封装为json对象,然后进而获取它url对应的value
r = r.substring(1,r.length()-1); jsonObject = JSONObject.parseObject(r); String url = jsonObject.getString("url");这时候拿到的value就是我们要的链接的后缀/th?id=OHR.MischwaldFuessen_ZH-CN0005213724_1920x1080.jpg&rf=LaDigue_1920x1080.jpg&pid=hp,只需要将其和前缀拼接在一起即可作为图片的地址。我们先将地址保存在一个文件里面,文件起名叫link
String result = "http://www.bing.com/" + url; File file = new File("./link"); if (!file.exists()) { file.createNewFile(); } FileOutputStream fos = new FileOutputStream(file); fos.write(result.getBytes());到此,Java程序完成,执行此程序即可将当日的每日一图的地址存入link这个文件里。
使用shell脚本将图片下载到制定位置思路很简单,使用shell脚本调用Java程序,然后去link文件中拿到链接即可使用wget命令进行下载。
将Java程序打包成一个jar包由于我们这个项目加入了阿里巴巴处理json的以来,所以需要带着依赖打包。
点击File->Project Structure->Artifacts->Jar->From modules with dependencies

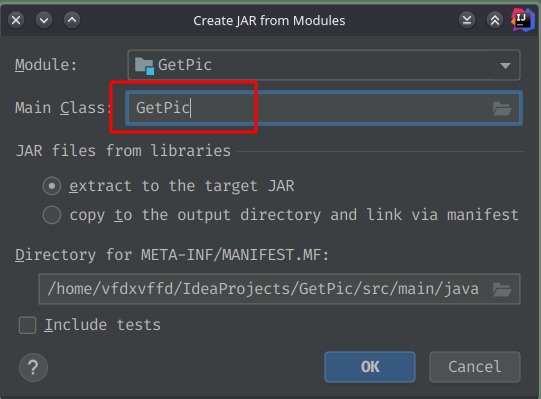
点击OK->Apply->关闭。这时候就在src下生成了一个.MF文件
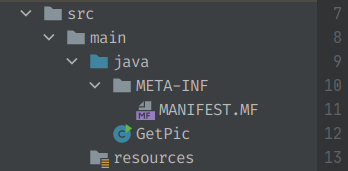
点击Build->Build Artifacts