
FastThreadLocal操作元素的时候,使用常量下标在数组中进行定位元素来替代ThreadLocal通过哈希和哈希表,这个改动特别在频繁使用的时候,效果更加显著!
想要利用上面的特征,线程必须是FastThreadLocalThread或者其子类,默认DefaultThreadFactory都是使用FastThreadLocalThread的
只用在FastThreadLocalThread或者子类的线程使用FastThreadLocal才会更快,因为FastThreadLocalThread 定义了属性threadLocalMap类型是InternalThreadLocalMap。如果普通线程会借助ThreadLocal。
我们看看NioEventLoopGroup细节:
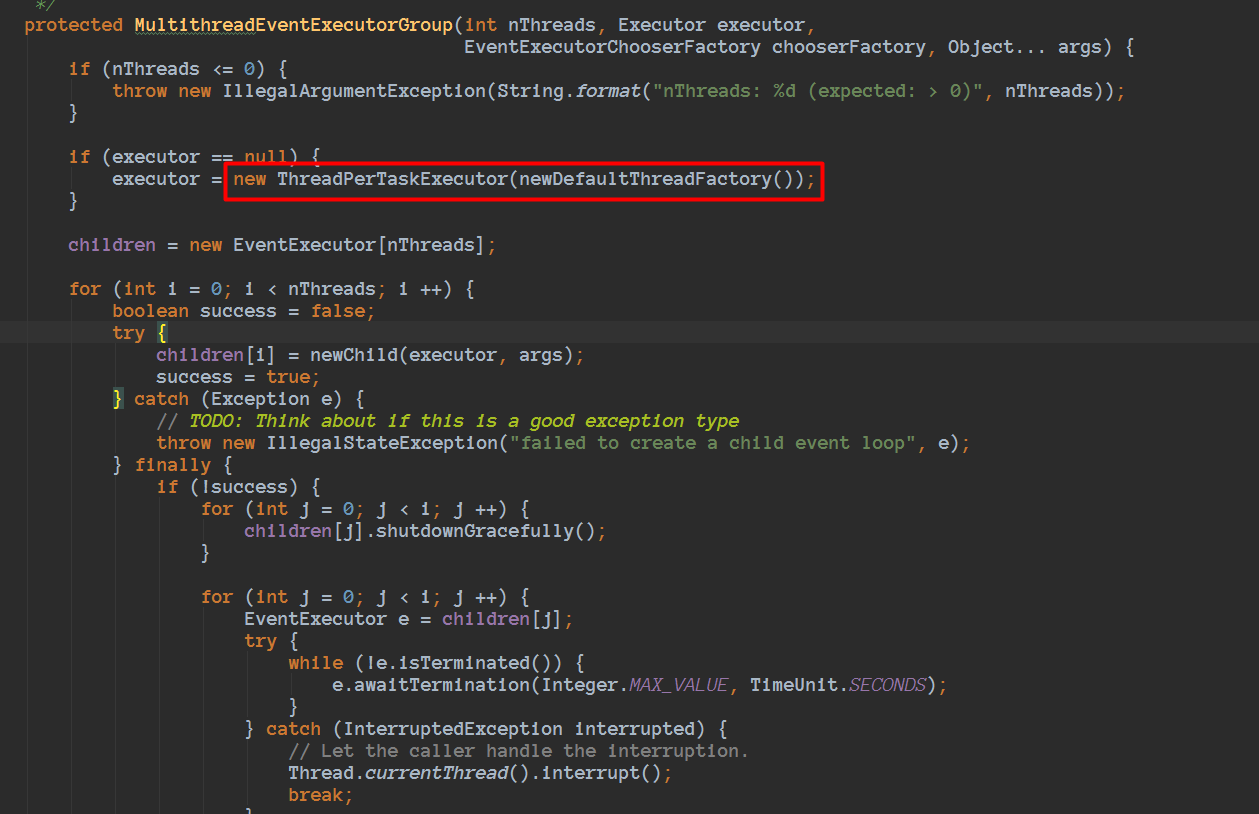
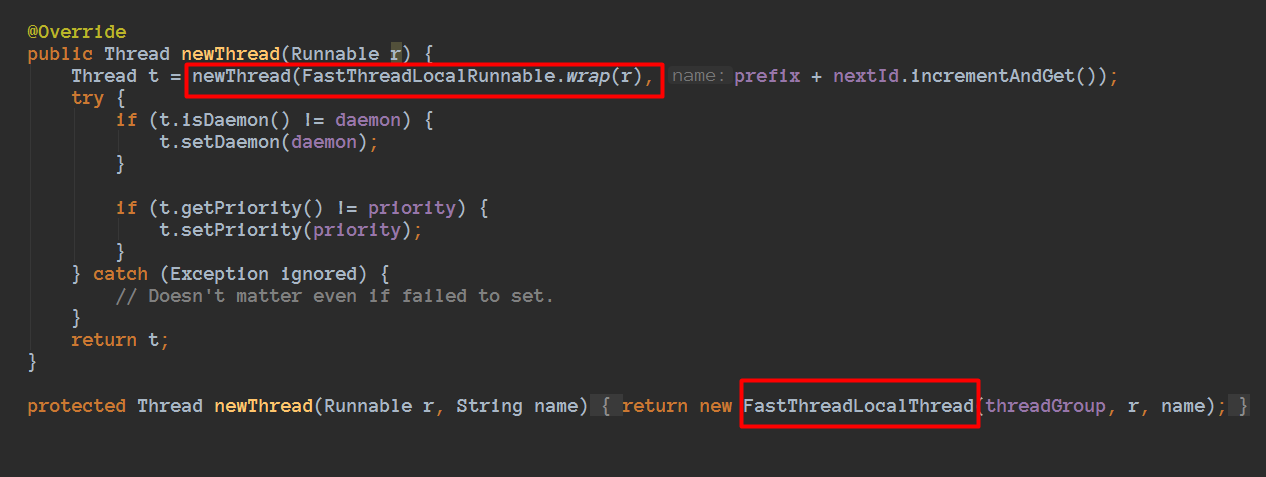
看到这里,和刚刚我们看到的注释内容一致的,是使用FastThreadLocalThread的。
netty里面使用FastThreadLocal的举例常用的:
池化内存分配:

会使用到Recycler
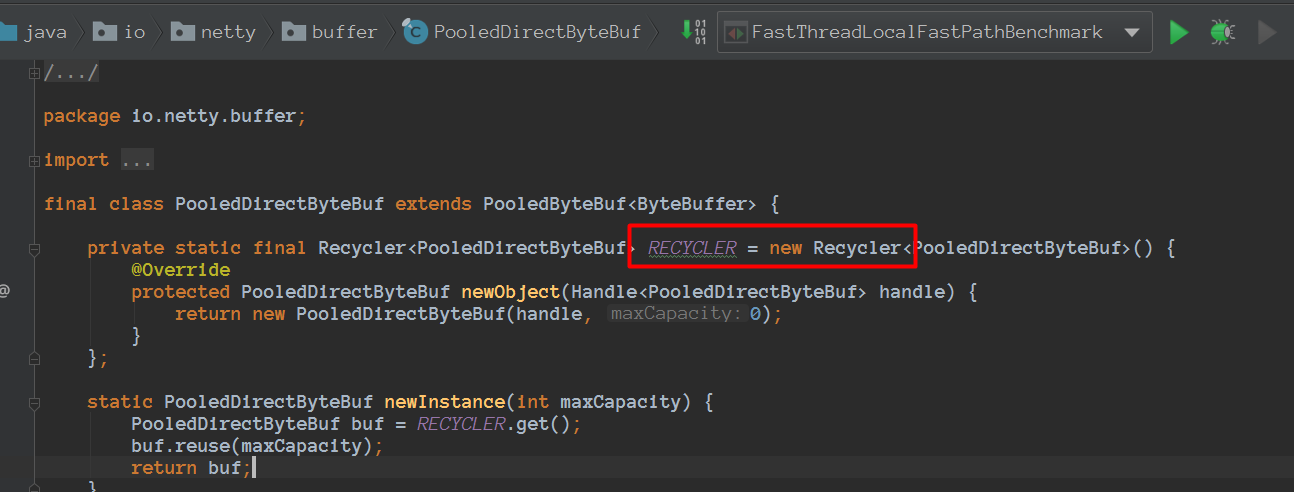
而Recycler也使用了FastThreadLocal
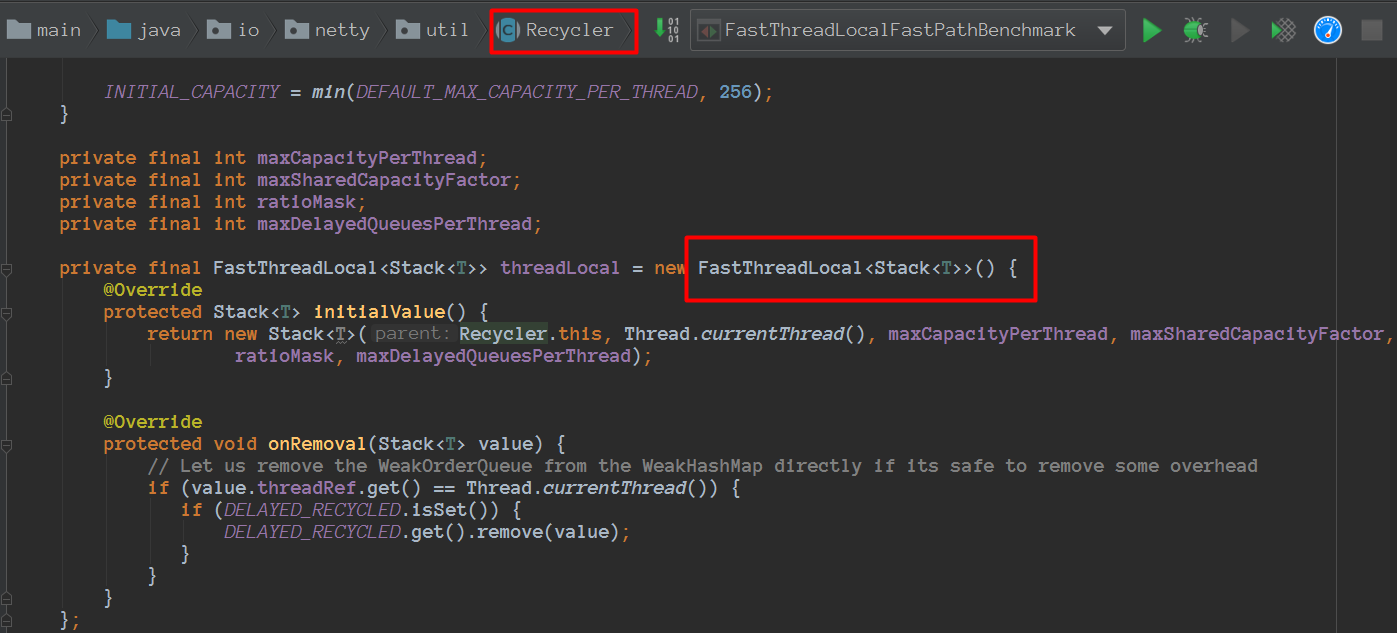
我们再看看看测试类:
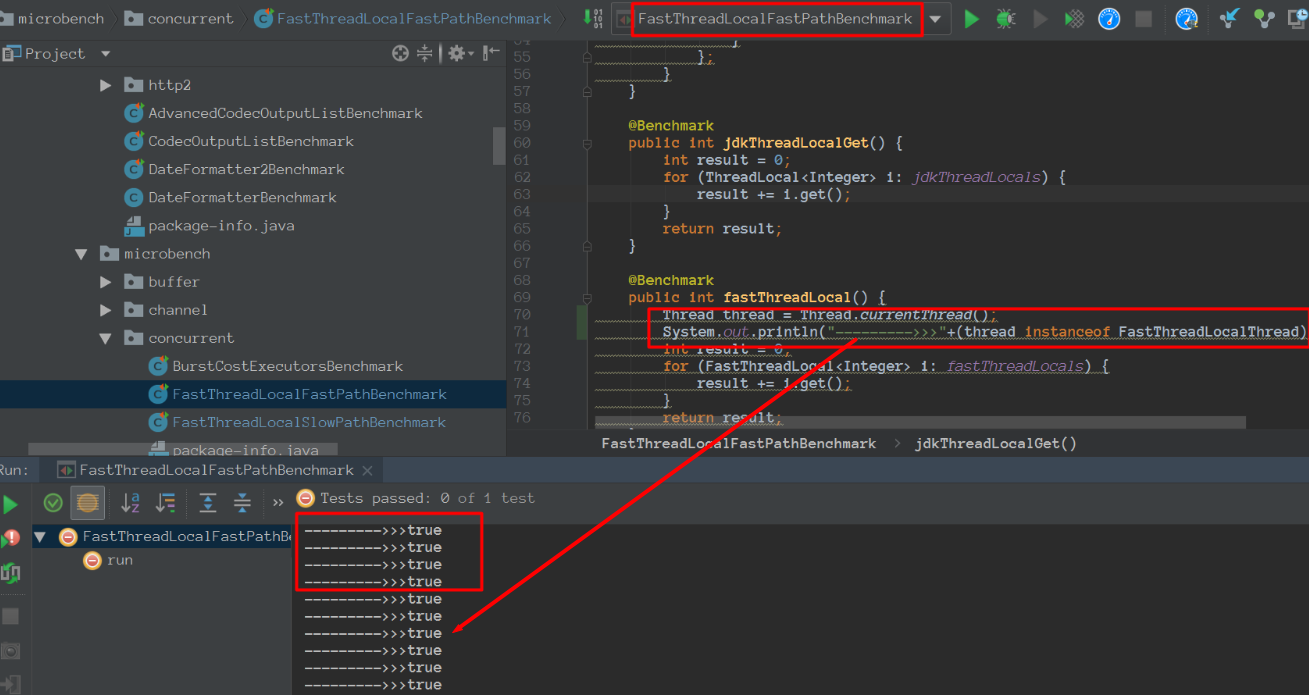
备注: 我们会发现FastThreadLocalFastPathBenchmark里面的线程是FastThreadLocal。
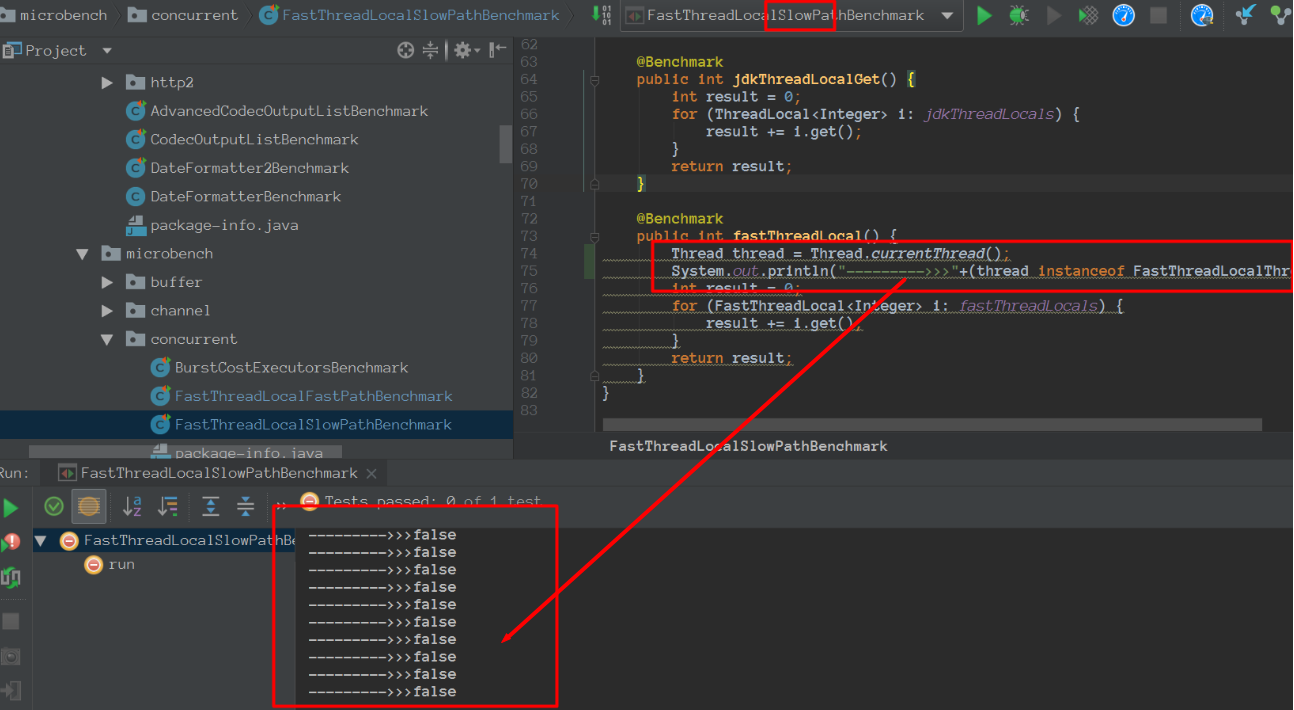
备注: 我们会发现FastThreadLocalSlowPathBenchmark里面的线程 不是FastThreadLocal。
FastThreadLocal只有被的线程是FastThreadLocalThread或者其子类使用的时候才会更快,吞吐量我这边测试的效果大概3倍左右,但是如果是普通线程操作FastThreadLocal其吞吐量比ThreadLocal还差!
FastThreadLocal利用字节填充来解决伪共享问题关于CPU 缓存 内容来源于美团:https://tech.meituan.com/2016/11/18/disruptor.html
下图是计算的基本结构。L1、L2、L3分别表示一级缓存、二级缓存、三级缓存,越靠近CPU的缓存,速度越快,容量也越小。所以L1缓存很小但很快,并且紧靠着在使用它的CPU内核;L2大一些,也慢一些,并且仍然只能被一个单独的CPU核使用;L3更大、更慢,并且被单个插槽上的所有CPU核共享;最后是主存,由全部插槽上的所有CPU核共享。

当CPU执行运算的时候,它先去L1查找所需的数据、再去L2、然后是L3,如果最后这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要尽量确保数据在L1缓存中。
另外,线程之间共享一份数据的时候,需要一个线程把数据写回主存,而另一个线程访问主存中相应的数据。
下面是从CPU访问不同层级数据的时间概念:

可见CPU读取主存中的数据会比从L1中读取慢了近2个数量级。
缓存行Cache是由很多个cache line组成的。每个cache line通常是64字节,并且它有效地引用主内存中的一块儿地址。一个Java的long类型变量是8字节,因此在一个缓存行中可以存8个long类型的变量。
CPU每次从主存中拉取数据时,会把相邻的数据也存入同一个cache line。