
在访问一个long数组的时候,如果数组中的一个值被加载到缓存中,它会自动加载另外7个。因此你能非常快的遍历这个数组。事实上,你可以非常快速的遍历在连续内存块中分配的任意数据结构。
伪共享由于多个线程同时操作同一缓存行的不同变量,但是这些变量之间却没有啥关联,但是每次修改,都会导致缓存的数据变成无效,从而明明没有任何修改的内容,还是需要去主存中读(CPU读取主存中的数据会比从L1中读取慢了近2个数量级)但是其实这块内容并没有任何变化,由于缓存的最小单位是一个缓存行,这就是伪共享。
如果让多线程频繁操作的并且没有关系的变量在不同的缓存行中,那么就不会因为缓存行的问题导致没有关系的变量的修改去影响另外没有修改的变量去读主存了(那么从L1中取是从主存取快2个数量级的)那么性能就会好很多很多。
有伪共享 和没有的情况的测试效果代码路径:https://github.com/jiangxinlingdu/nettydemo
nettydemo

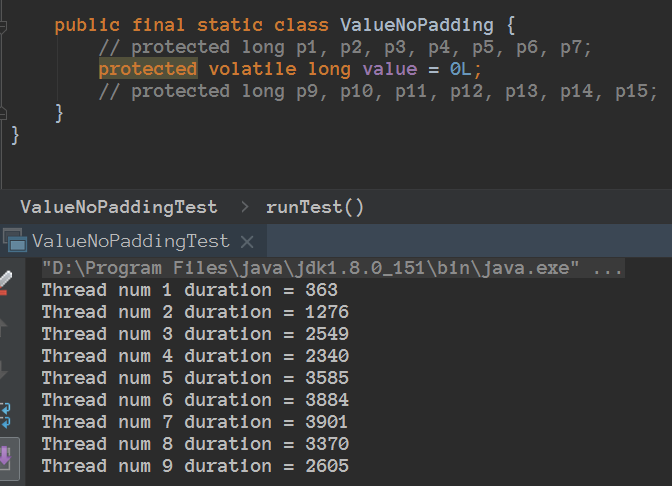
利用字节填充来解决伪共享,从而速度快了3倍左右。
FastThreadLocal使用字节填充解决伪共享之前介绍ThreadLocal的时候,说过ThreadLocal是用在多线程场景下,那么FastThreadLocal也是用在多线程场景,大家可以看下这篇:手撕面试题ThreadLocal!!!,所以FastThreadLocal需要解决伪共享问题,FastThreadLocal使用字节填充解决伪共享。


这个是我自己手算的,通过手算太麻烦,推荐一个工具JOL。
推荐IDEA插件:https://plugins.jetbrains.com/plugin/10953-jol-java-object-layout
代码路径:https://github.com/jiangxinlingdu/nettydemo
nettydemo
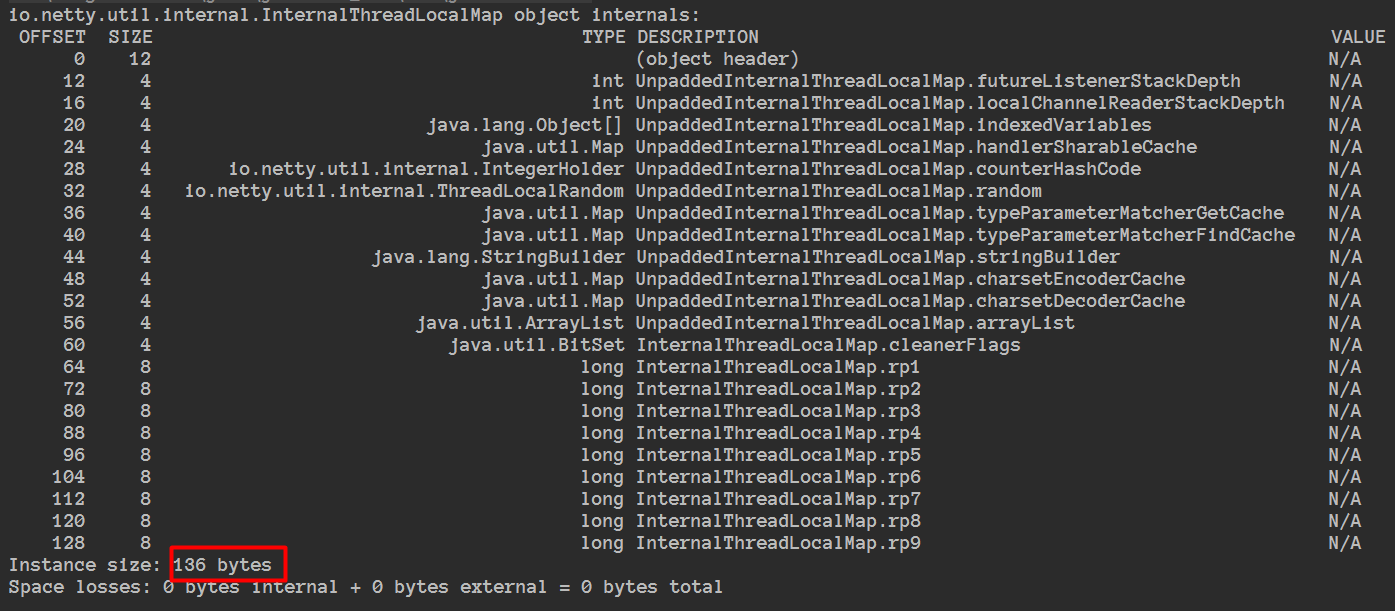
通过这个工具算起来就很容易了,如果以后有类似的需要看的,不用手一个一个算了。
FastThreadLocal被FastThreadLocalThread进行读写的时候也可能利用到缓存行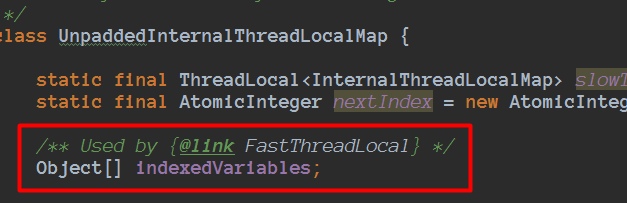
并且由于当线程是FastThreadLocalThread的时候操作FastThreadLocal是通过indexedVariables数组进行存储数据的的,每个FastThreadLocal有一个常量下标,通过下标直接定位数组进行读写操作,当有很多FastThreadLocal的时候,也可以利用缓存行,比如一次indexedVariables数组第3个位置数据,由于缓存的最小单位是缓存行,顺便把后面的4、5、6等也缓存了,下次刚刚好另外FastThreadLocal下标就是5的时候,进行读取的时候就直接走缓存了,比走主存可能快2个数量级。
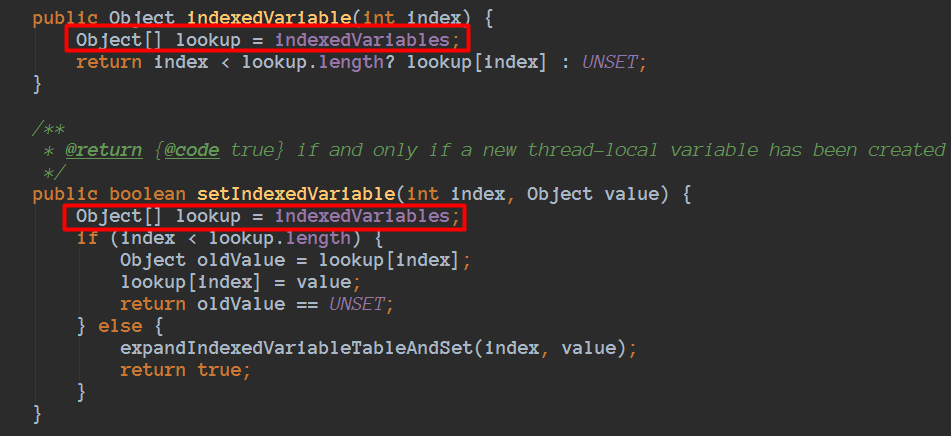
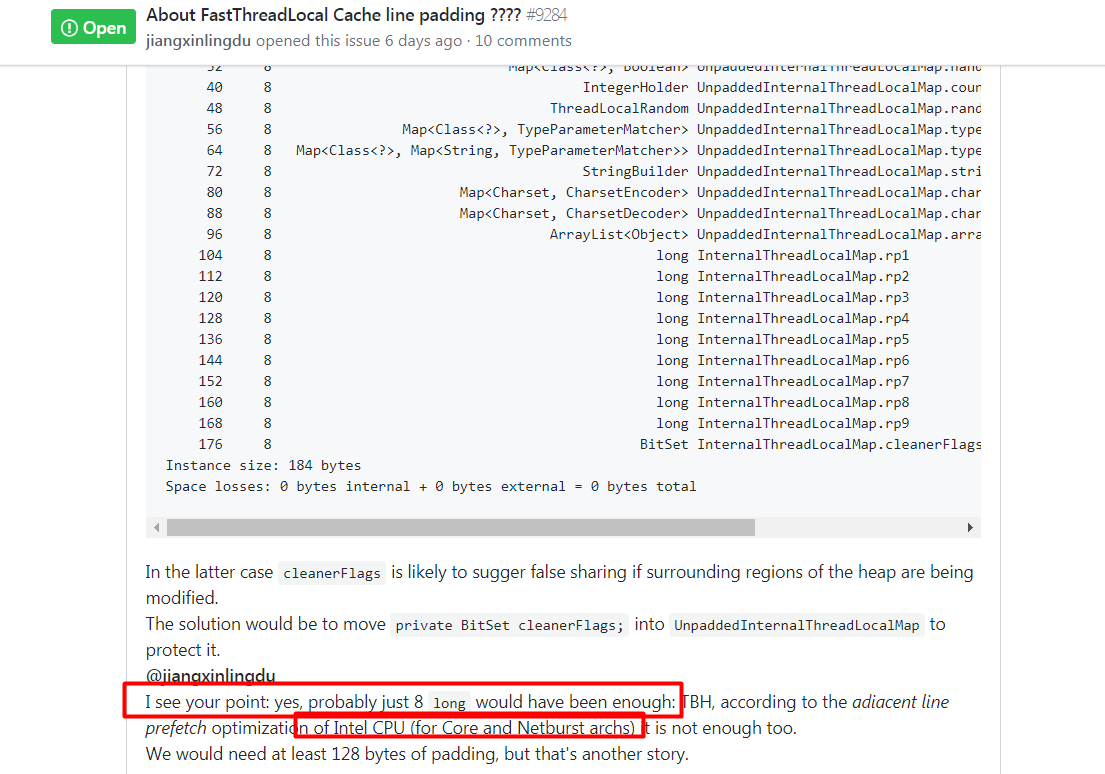
问题:为什么这里填充了9个long值呢???
我提了一个issue:https://github.com/netty/netty/issues/9284

虽然也有人回答,但是感觉不是自己想要的,说服不了自己!!!
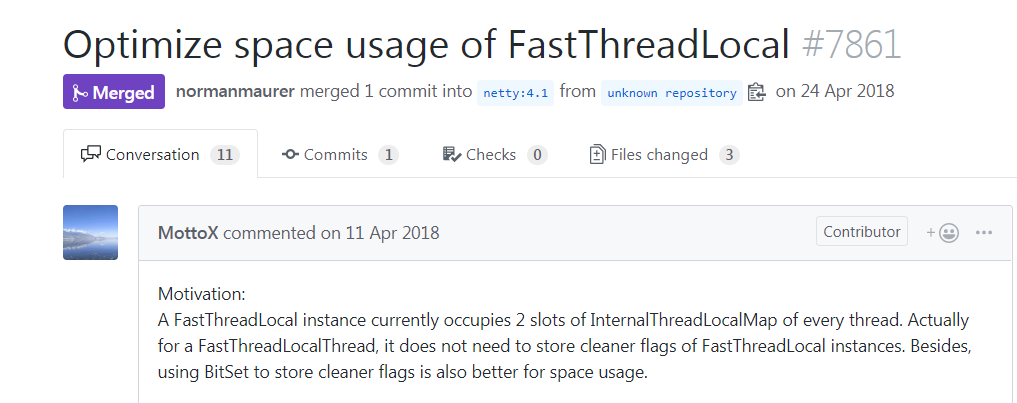
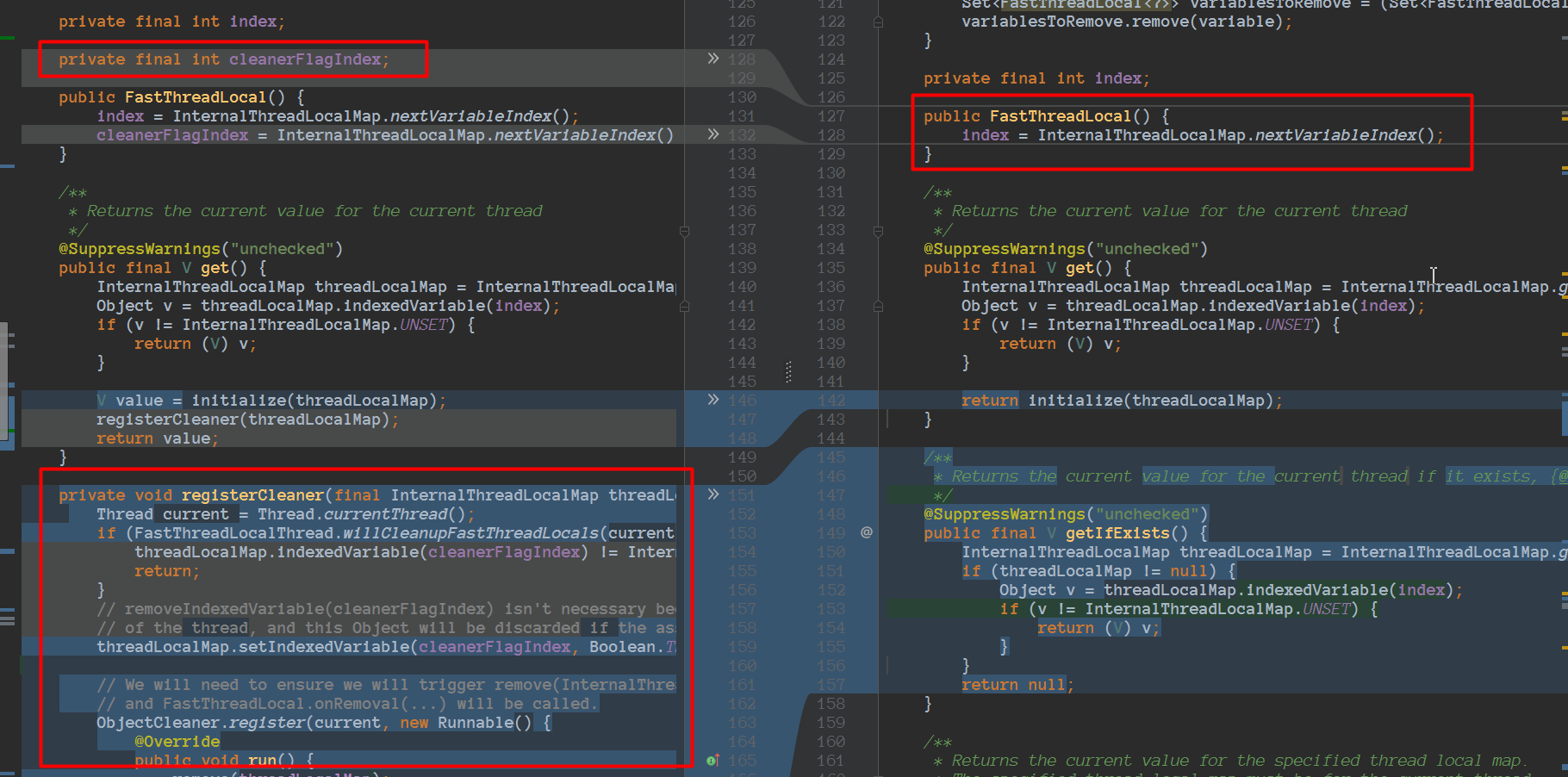
现在清理已经去掉,本文下面会介绍,所以FastThreadLocal比ThreadLocal快,并不是空间换时间,FastThreadLocal并没有浪费空间!!!
FastThreadLocal不在使用ObjectCleaner处理泄漏,必要的时候建议重写onRemoval方法最新的netty版本中已经不在使用ObjectCleaner处理泄漏:
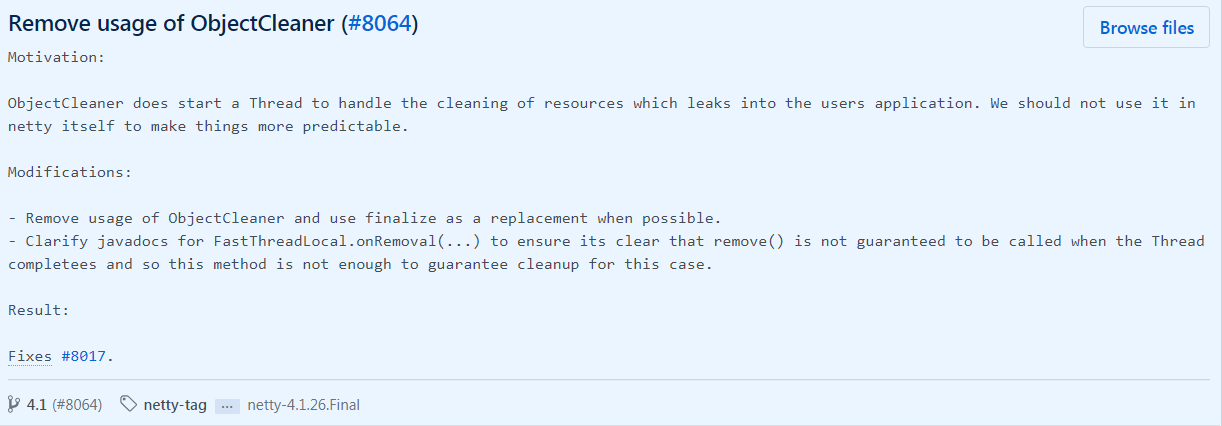
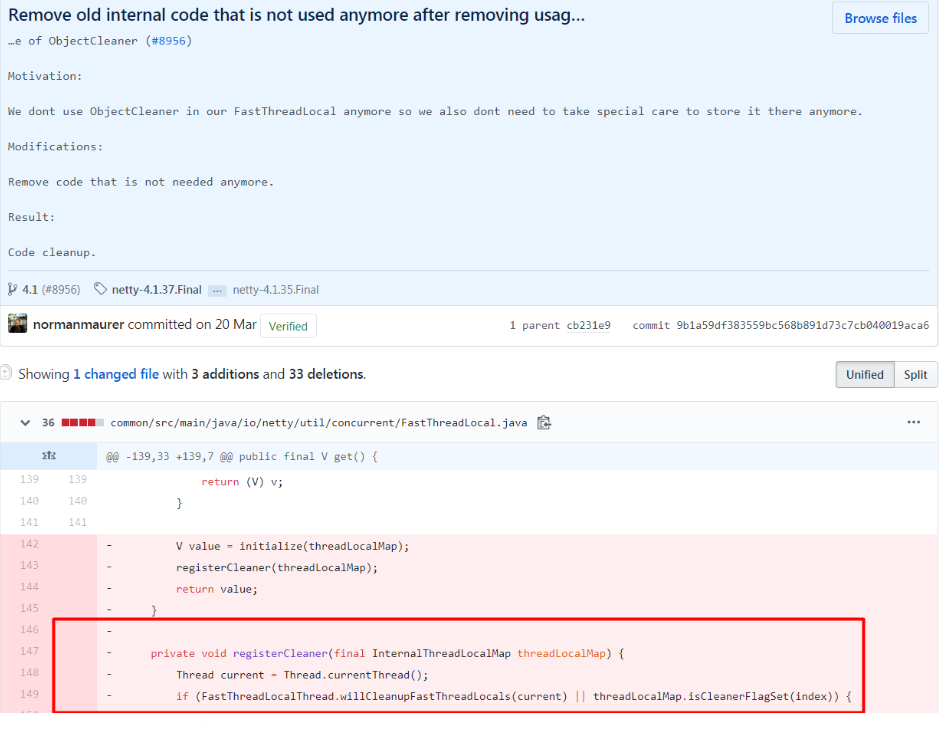
去掉原因:
https://github.com/netty/netty/issues/8017
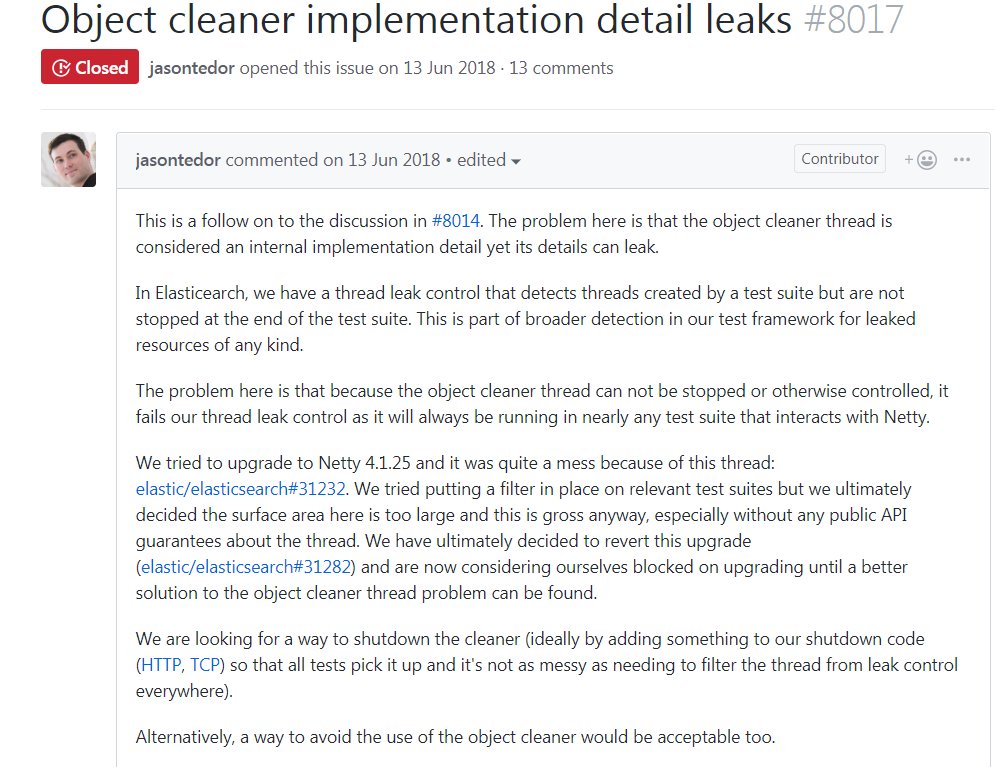
我们看看FastThreadLocal的onRemoval
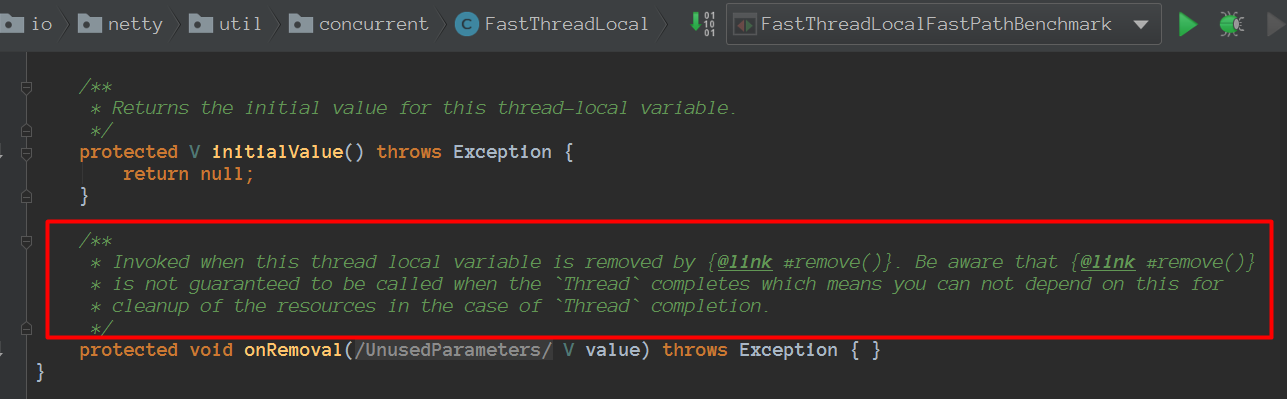
如果使用的是FastThreadLocalThread能保证调用的,重写onRemoval做一些收尾状态修改等等