
抽象类和接口的区别
我们先来看一下抽象类
* @auther draymonder */ public abstract class AbstractClassTest { private int Test1; public int Test2; public void test1() { return ; } protected void test2() { return ; } private void test3() { return ; } void test4() { return ; } public abstract void test5(); protected abstract void test6(); public static void test7() { return ; } }我们再来看一下接口
/** * @auther draymonder */ public interface IntefaceTest { public int Test1 = 0; void test1(); default void test2() { return ; } public static void test3() { return ; } }由此我们可以知道
接口中没有构造方式
接口中的方法必须是抽象的(在JDK8下interface可以使用default实现方法)
接口中除了static、final变量,不能有其他变量
接口支持多继承
Java集合 ArrayList数组的默认大小为 10。
private static final int DEFAULT_CAPACITY = 10;添加元素时使用 ensureCapacityInternal() 方法来保证容量足够,如果不够时,需要使用 grow() 方法进行扩容,新容量的大小为 oldCapacity + (oldCapacity >> 1),也就是旧容量的 1.5 倍。
Vector数组的默认大小为 10。
Vector 每次扩容请求其大小的 2 倍空间,而 ArrayList 是 1.5 倍。
Vector 是同步的,因此开销就比 ArrayList 要大,访问速度更慢。最好使用 ArrayList 而不是 Vector,因为同步操作完全可以由程序员自己来控制;
可以使用collections的同步list的方法
CopyOnWriteArrayList 在写操作的同时允许读操作,大大提高了读操作的性能,因此很适合读多写少的应用场景。
但是 CopyOnWriteArrayList 有其缺陷:
内存占用:在写操作时需要复制一个新的数组,使得内存占用为原来的两倍左右;
数据不一致:读操作不能读取实时性的数据,因为部分写操作的数据还未同步到读数组中。
所以 CopyOnWriteArrayList 不适合内存敏感以及对实时性要求很高的场景。
key & (hash - 1)等同于key % hash,但前者效率比后者高
扩容的时候,table cap变为2 * table cap,rehash仅仅需要判断key & hash如果为0,还是原来的table[old],否则是table[old+table cap]
mask码的作用 先考虑如何求一个数的掩码,对于 10010000,它的掩码为 11111111,可以使用以下方法得到: mask |= mask >> 1 11011000 mask |= mask >> 2 11111110 mask |= mask >> 4 11111111mask+1 是大于原始数字的最小的 2 的 n 次方。
num 10010000 mask+1 100000000以下是 HashMap 中计算数组容量的代码:
static final int tableSizeFor(int cap) { int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; } JDK7版本下的链表循环在扩容时候,由于是头插法,所以,原来是A->B,但是多线程情况下会出现。
线程1刚刚拿出A, 并准备rehash到B的后面,但是存在B->A还没有解除的情况,因此正好出现了A->B->A的情况
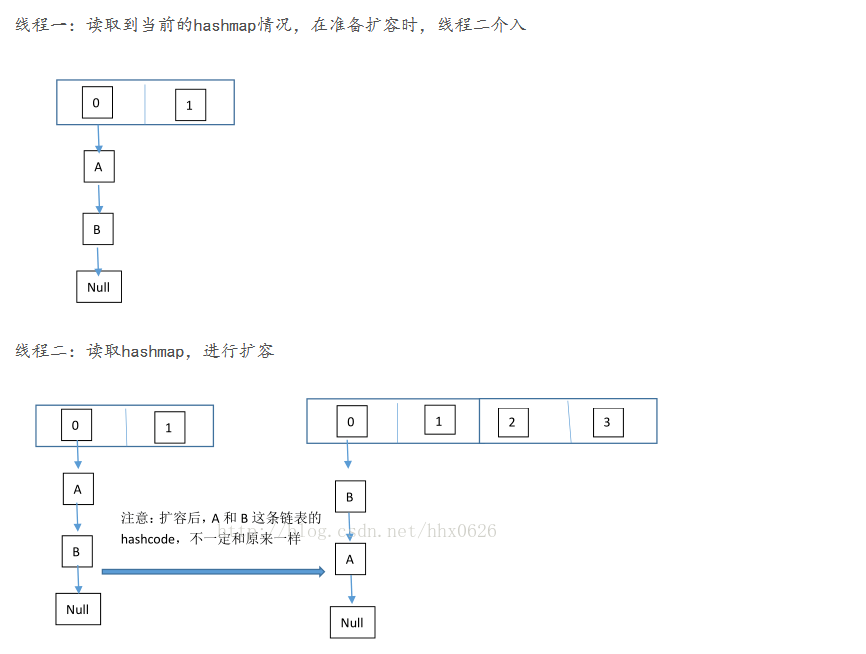

如果load factor太小,那么空间利用率太低;如果load factor太大,那么hash冲撞就会比较多
JDK8下hashmap为什么为长度为8链表转为红黑树我们来看一下hashmap的注释
Because TreeNodes are about twice the size of regular nodes, we use them only when bins contain enough nodes to warrant use (see TREEIFY_THRESHOLD). And when they become too small (due to removal or resizing) they are converted back to plain bins. In usages with well-distributed user hashCodes, tree bins are rarely used. Ideally, under random hashCodes, the frequency of nodes in bins follows a Poisson distribution () with a parameter of about 0.5 on average for the default resizing threshold of 0.75, although with a large variance because of resizing granularity. Ignoring variance, the expected occurrences of list size k are (exp(-0.5) * pow(0.5, k) / factorial(k)). The first values are: 0: 0.60653066 1: 0.30326533 2: 0.07581633 3: 0.01263606 4: 0.00157952 5: 0.00015795 6: 0.00001316 7: 0.00000094 8: 0.00000006 more: less than 1 in ten million