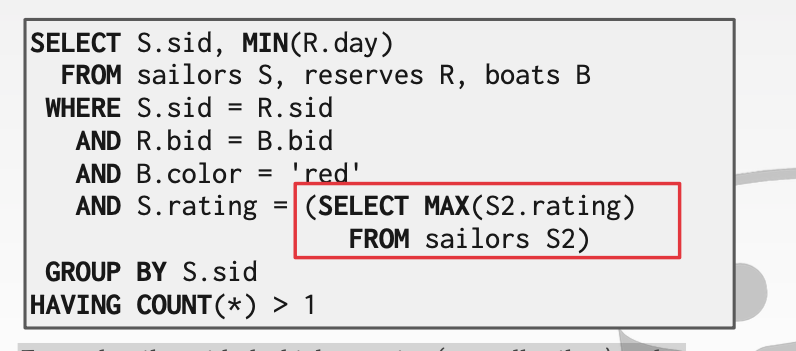
显然数据不可能完全符合均匀分布。这里具体看一下不同分布的数据如何进行
对于数据不均衡的分布。
我们对数据进行分桶。随后统计每个桶内元素的个数
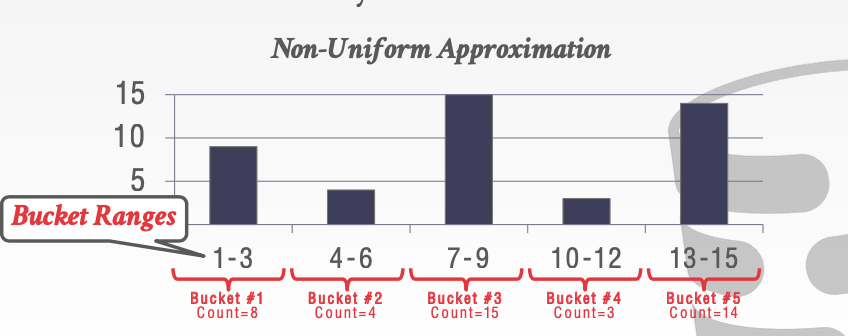
我们更改桶的范围。来尽量使每个桶内的元素个数相同
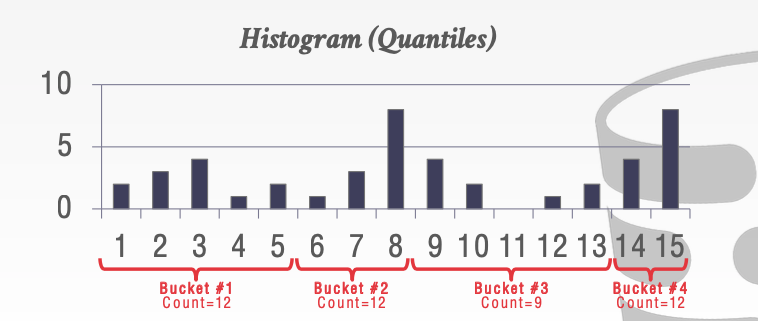
这里的sample就和深度学习里的sample一个意思。
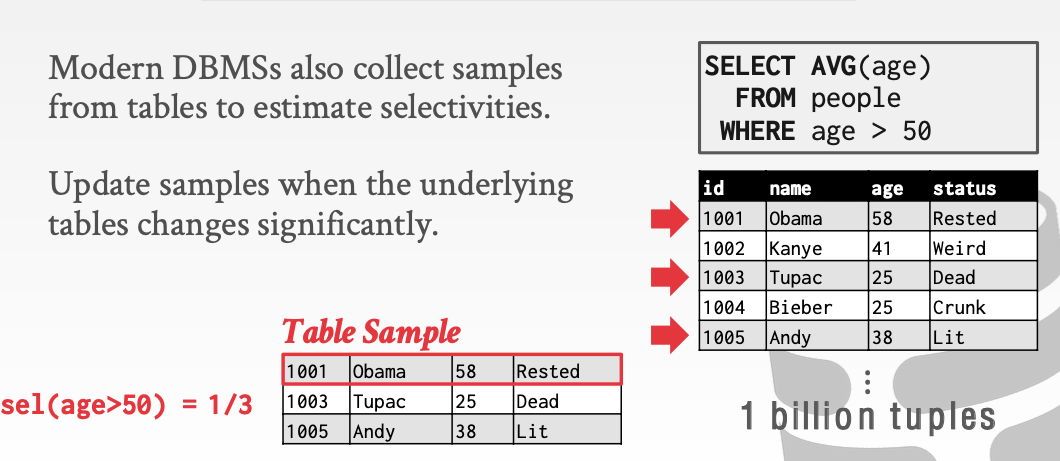
比如对于这个例子。我们在有一亿个tuple的表中随机sample出来三个tuple。以此来代表整个表中tuple的情况。当然这样是不准确的。但是作为一个简单的先学知识是完全可以的。
3. 应用动态规划的优化从下面这个例子开始
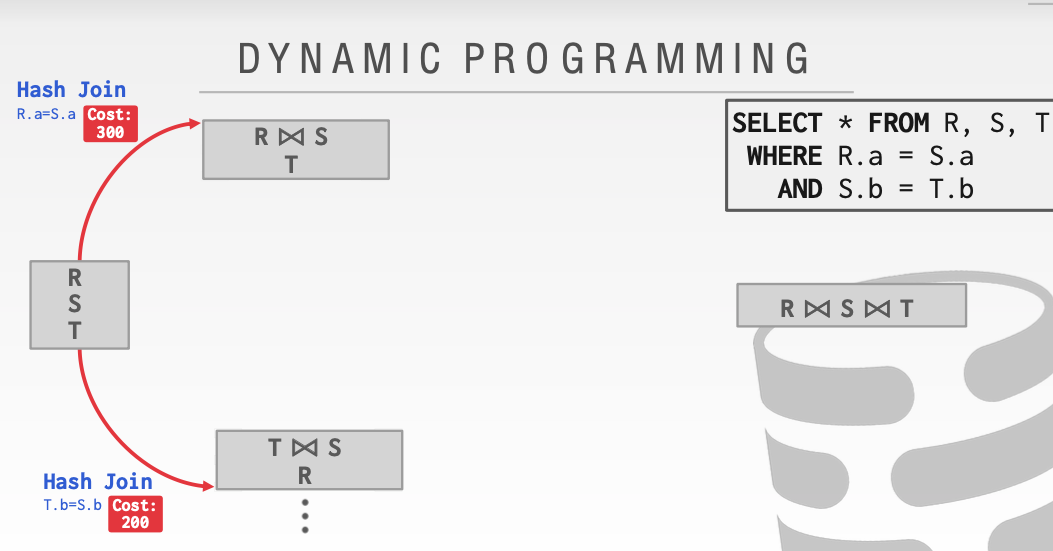
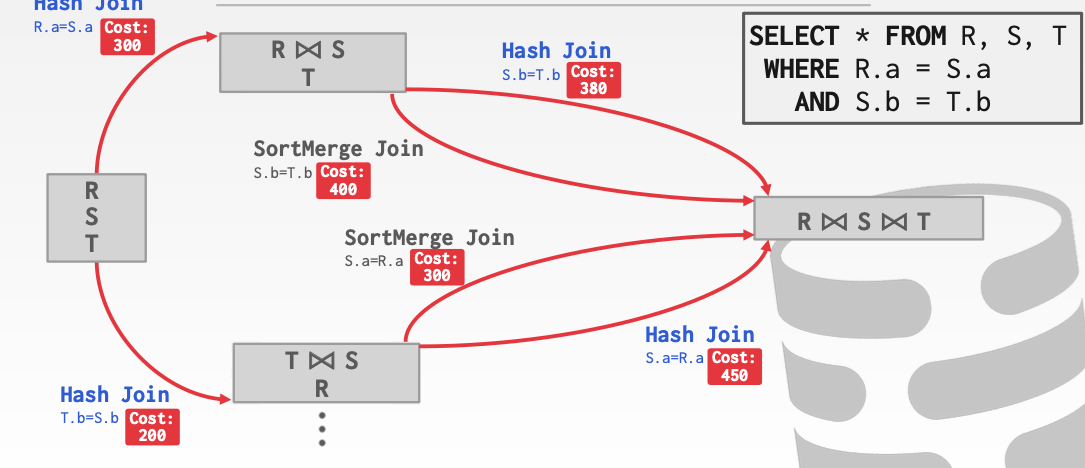
可以看见在第二步奔向第三步的时候,我们有了不同的选择。这里的Hash Join和sortMerge Join有了不同的花费。显然我们应该 选择花费更小的路径。
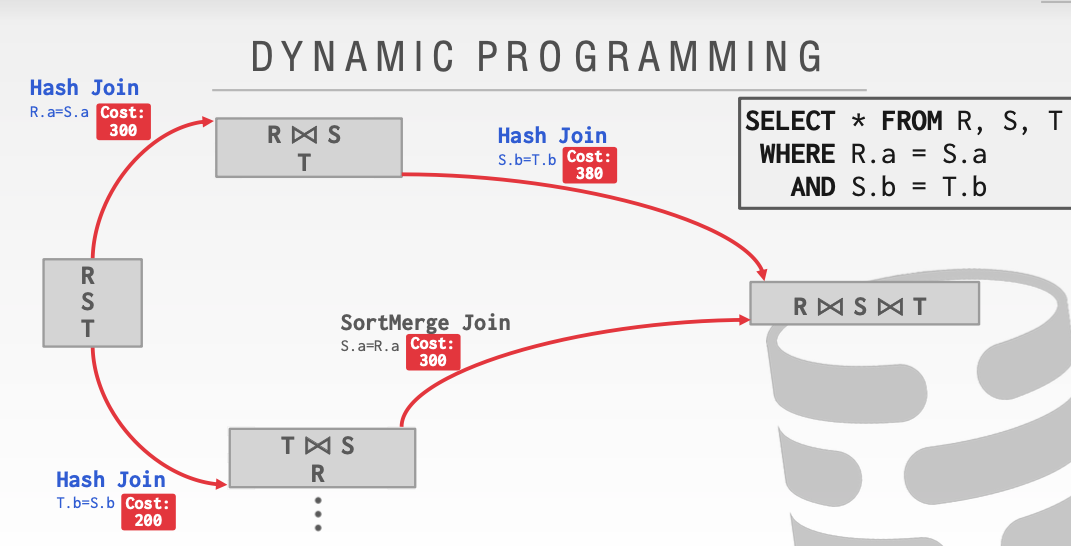
这里回到第一步我们应该选择一条花费更小的路径。由于200 + 300 < 300 + 300 。因此我们应该选择下面这条。
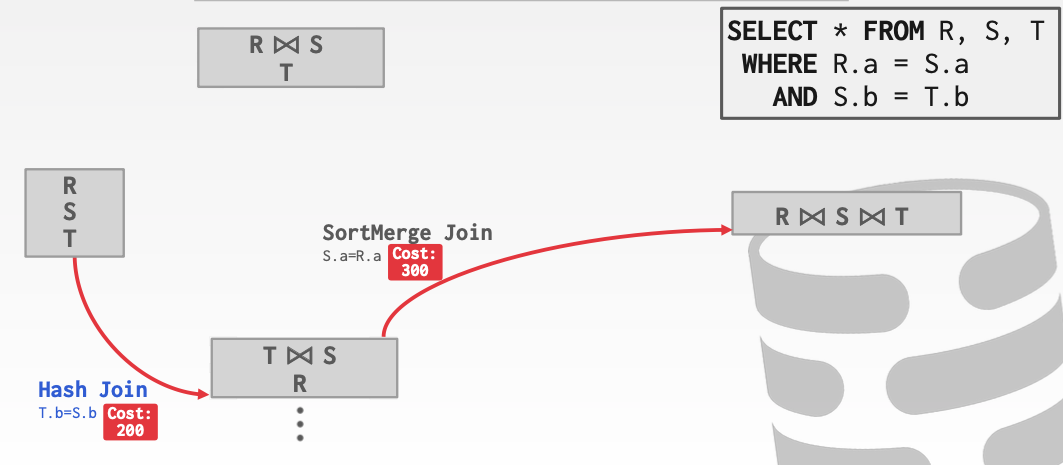
由于一条逻辑plan会对应许多的物理plan
那么如何选择一个最好的plan。请看下面的步骤
首先列举出来所有的candidate plan
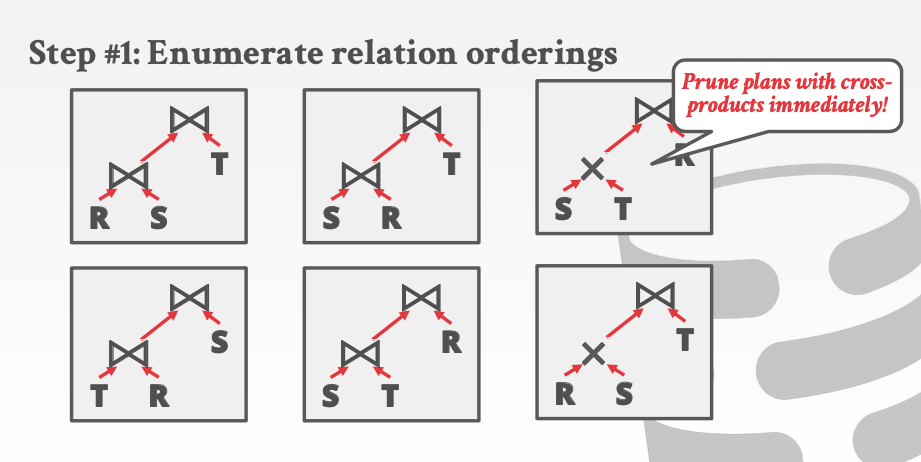
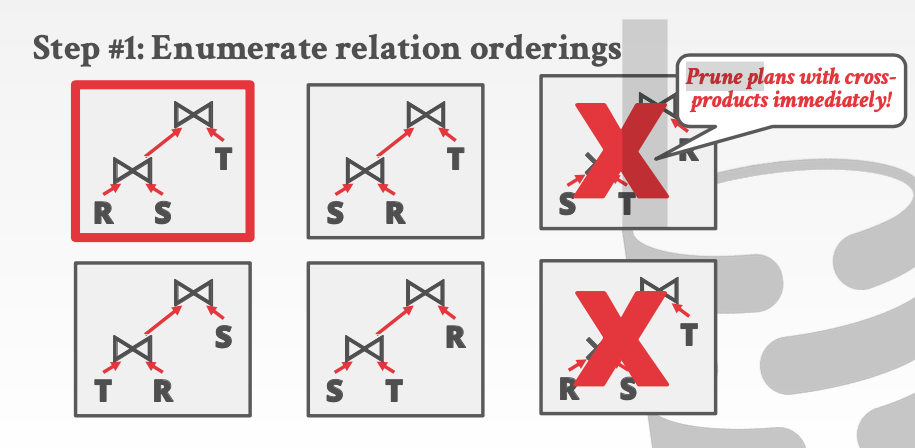
立即去掉所有带corss-product操作的plan
用不同的join算法替代join操作。这样就可以列出所有的情况
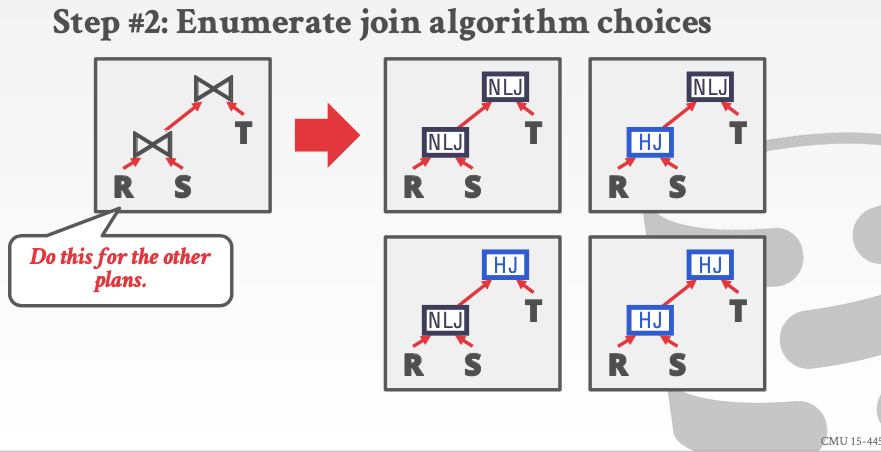
NLJ = nested Loop Join
HJ = hash join
显然我们可以从里面选择最好的。也就是两个join操作都基于HJ
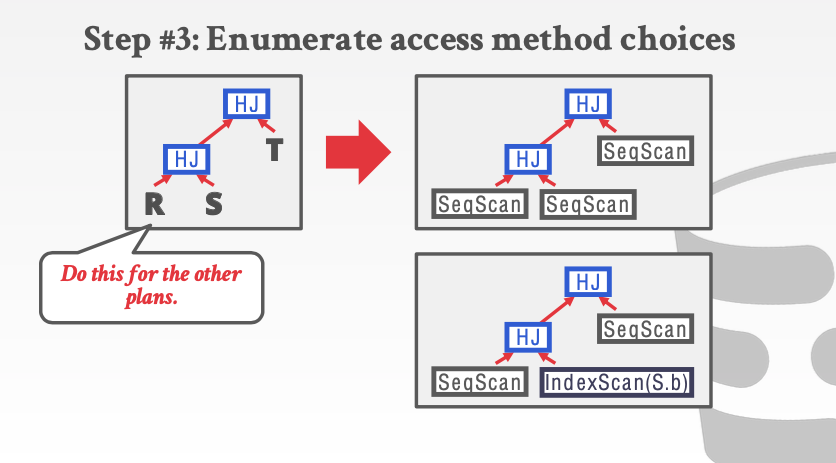
在替代所有的访问算法
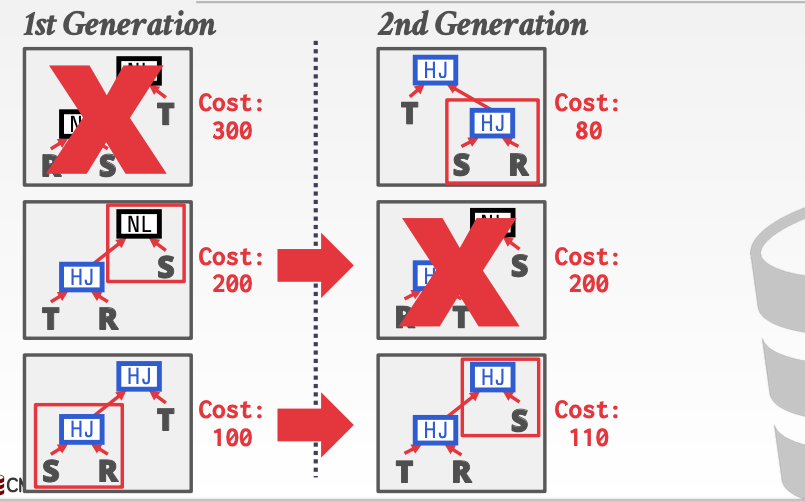
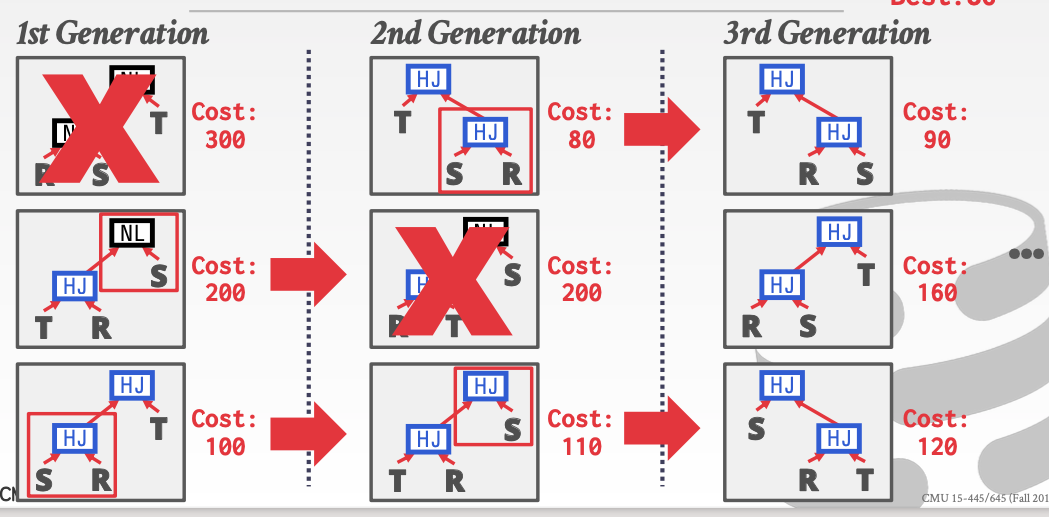
这种优化方法主要针对于语法树的重构。每次都淘汰一种花费最多的方案。对于其他的方案都给机会。
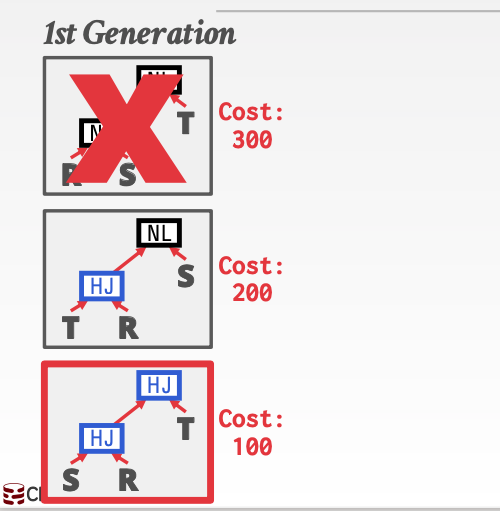
这里300花费最多。所以直接淘汰
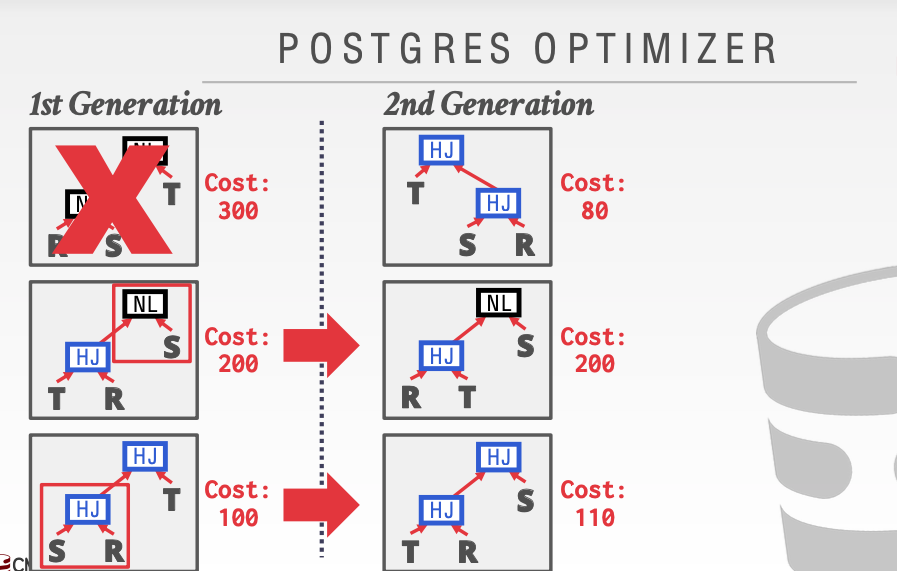
然后对于剩下的两种情况。把所有语法树重构的情况列举出来
DBMS将where子句中的嵌套子查询视为获取参数并返回单个值或一组值的函数。
有下面一些简单的方法对于子查询的优化
Rewrite
对于下面这个nested的子查询

我们可以把这个sql语句重写

DECOMpose Query
对于下面这个例子