
std::match_results用来存储匹配结果。与迭代器类似,匹配结果也有四种类型:
类型 定义std::cmatch std::match_results<const char*>
std::wcmatch std::match_results<const wchar_t*>
std::smatch std::match_resultsstd::string::const_iterator
std::wsmatch std::match_resultsstd::wstring::const_iterator
当我们使用正则表达式时,我们的目标常常不单单是判断或者查找完整匹配的内容。而是需要捕获匹配结果中的子串。例如:我们不仅要匹配出日期,还要捕获日期中的年份,月份等信息。这个时候就要使用分组功能。
我们在介绍正则表达式特殊字符的时候,提到过圆括号(和)。它们的作用就是分组。当你在正则表达式中配对的使用圆括号时,就会形成一个分组,一个正则表达式中可以包含多个分组。分组通过编号0, 1, 2, …来区分。编号0的分组是匹配的整体,其他编号根据括号的顺序来确定。
这些分组最终可以在匹配完成之后,可以通过std::match_results的API来获取。这些API如下表所示:
API 说明empty 检查匹配是否成功
size 返回完成建立的结果状态中的匹配数
max_size 返回子匹配的最大可能数量
length 返回特定分组的长度
position 分会特定分组首字符的位置
str 返回特定分组的字符序列
operation[] 返回指定的分组
prefix 返回目标序列起始和完整匹配起始之间的分组
suffix 返回完整匹配结果和目标序列结尾之间的分组
在C++中,分组叫做子匹配(sub_match)。std::sub_match 这个类型只有一个默认构造函数,通常你不会主动创建它,而是使用std::match_results的接口来获取它的对象。
示例:查找出文本中所有的年代,并分离出世纪的部分和年份的部分。 思路:年代的格式是四位数字加上“s”作为后缀。我们可以通过分组的形式分离出两个部分。图示如下:
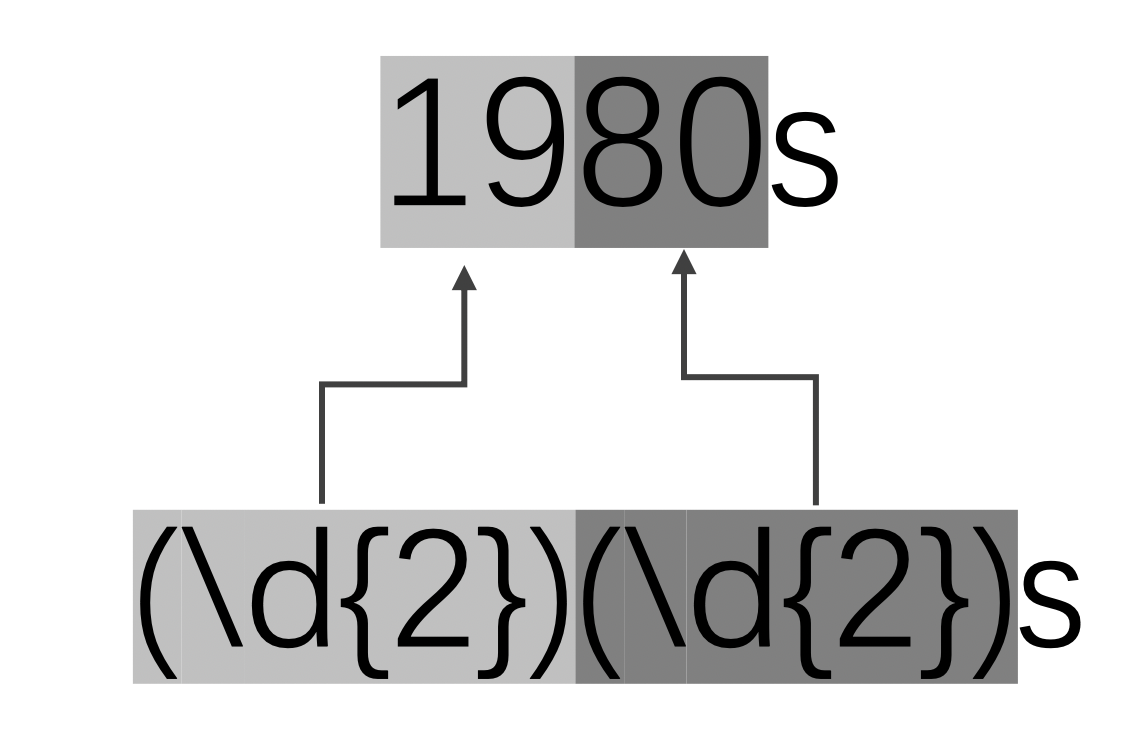
代码示例:
#include <fstream> #include <iostream> #include <regex> using namespace std; int main() { regex word_regex(R"((\d{2})(\d{2})s)"); // ① ifstream file("./content.txt"); string line; while(getline(file, line)) { auto iter_begin = sregex_iterator(line.begin(), line.end(), word_regex); auto iter_end = sregex_iterator(); for (auto iter = iter_begin; iter != iter_end; iter++) { cout << "Match content: " << iter->str(0) << ", "; // ② cout << "group Size: " << iter->size() << endl; // ③ cout << "Century: " << iter->str(1) << ", "; // ④ cout << "length: " << iter->length(1) << ", "; cout << "position: " << iter->position(1) << endl; auto year = (*iter)[2]; // ⑤ cout << "Year: " << year.str() << ", "; cout << "length: " << year.length() << ", "; cout << "position: " << iter->position(2) << endl; cout << endl; } } return 0; }这段代码说明如下:
这个正则表达式请注意其中的圆括号
先打印匹配的字符串整体
所有的分组数量,应该是 2 + 1 = 3
打印出世纪的部分
获取编号2的分组,其类型是sub_match
这段代码输出如下:
Match content: 1950s, group Size: 3 Century: 19, length: 2, position: 25 Year: 50, length: 2, position: 27 Match content: 1980s, group Size: 3 Century: 19, length: 2, position: 277 Year: 80, length: 2, position: 279 稍微深入一点的内容 同一个符号的不同含义,我们看到了正则表达式的特殊字符。但需要进一步说明的是,这些特殊字符在不同的环境可能有着不同的含义。