
1 数据库事务处理
一个数据库事务通常包含对数据库进行读或写的一个操作序列 . 当一个事务被提交给了DBMS(数据库管理系统),则DBMS需要确保该事务中的所有操作都成功完成且其结果被永久保存在数据库中,如果事务中有的操作没有成功完成,则事务中的所有操作都需要被回滚.
1 为数据库提供了一个从失败恢复到正常状态的方法 , 同时提供了数据库在异常状态下仍然能保持一致性方法
2 当多个应用程序并发访问数据库时,可以在这些应用程序之间提供隔离方法,以防止彼此的操作互相干扰
事务具有的特性:
原子性(Atomicity):事务作为一个整体被执行,对数据库的操作要么全部被执行,要么都不执行。
一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态的含义是数据库中的数据应满足完整性约束。
隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行。
持久性(Durability):一个事务一旦提交,他对数据库的修改应该永久保存在数据库中。
爬虫数据库操作封装
import pymysql '''爬虫数据库存储''' class Sql(object): def __init__(self): #创建连接 self.conn = pymysql.connect(host='xxx', port=3306, user= 'root', passwd = 'xxx', database = 'douban',charset = 'utf8') #创建游标 self.cursor = self.conn.cursor() #执行sql清空Movie self.cursor.execute("truncate table Movie") self.conn.commit() def process_item(self, item, spider): try: #执行sql插入语句 self.cursor.execute("insert into Movie (name,movieInfo,star,quote) VALUES (%s,%s,%s,%s)",(item['name'], item['movieInfo'], item['star'], item['quote'])) #提交数据 self.conn.commit() except pymysql.Error: print("Error%s,%s,%s,%s" % (item['name'], item['movieInfo'], item['star'], item['quote'])) return item def close_spider(self, spider): #关闭 self.cursor.close() self.conn.close() 2 数据库索引1 索引概述
索引(Index)是帮助MySQL高效获取数据的数据结构, 数据库查询是最重要,最基本功能之一.
常见的查询算法:
>1 顺序查找 , 数据量大时,肯定不行 > >2 二分查找, 但要求数据有序 > >3 二叉树查找,只能应用在二叉树上 > >4 为了适应各种复杂的数据结构, 数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引索引方式
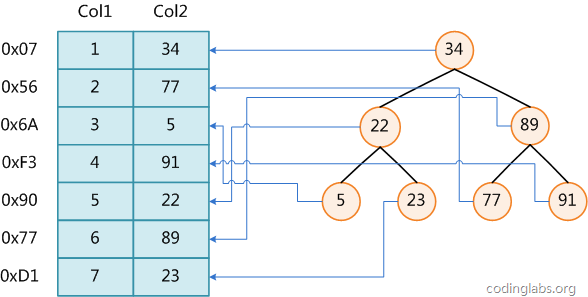
2 聚焦索引与非聚焦索引
聚焦索引
目前大部分的数据库系统及文件系统都是采用B-Tree与 B+Tree实现的即平衡树的数据结构.
我们平时建表的时候都会为表加上主键, 在某些关系数据库中, 如果建表时不指定主键,数据库会拒绝建表的语句执行。 事实上, 一个加了主键的表,并不能被称之为「表」。一个没加主键的表,它的数据无序的放置在磁盘存储器上,一行一行的排列的很整齐, 跟我认知中的「表」很接近。如果给表上了主键,那么表在磁盘上的存储结构就由整齐排列的结构转变成了树状结构,也就是上面说的「平衡树」结构,换句话说,就是整个表就变成了一个索引。没错, 再说一遍, 整个表变成了一个索引,也就是所谓的「聚集索引」。 这就是为什么一个表只能有一个主键, 一个表只能有一个「聚集索引」,因为主键的作用就是把「表」的数据格式转换成「索引(平衡树)」的格式放置 , 这样原本大量查询的数据查询次数计算 , 查找次数是以树的分叉数为底,记录总数的对数,大大降低次数数量级.
索引能让数据库查询数据的速度上升, 而使写入数据的速度下降,原因很简单的, 因为平衡树这个结构必须一直维持在一个正确的状态, 增删改数据都会改变平衡树各节点中的索引数据内容,破坏树结构, 因此,在每次数据改变时, DBMS必须去重新梳理树(索引)的结构以确保它的正确,这会带来不小的性能开销,也就是为什么索引会给查询以外的操作带来副作用的原因。
非聚焦索引即常规索引
非聚焦索引即 每次给字段建一个新索引, 字段中的数据就会被复制一份出来, 用于生成索引。 因此, 给表添加索引,会增加表的体积, 占用磁盘存储空间。