
对象头的内容如下表 。
长度 内容 说明32/64bit Mark Word 存储对象的hashCode或锁信息等
32/64bit Class Metadata Access 存储到对象类型数据的指针
32/64bit Array length 数组的长度(如果是数组)
Mark Work的格式如下所示。
锁状态 29bit或61bit 1bit是否是偏向锁? 2bit锁标志位无锁 0 01
偏向锁 线程ID 1 01
轻量级锁 指向栈中锁记录的指针 此时这一位不用于标识偏向锁 00
重量级锁 指向互斥量(重量级锁)的指针 此时这一位不用于标识偏向锁 10
GC标记 此时这一位不用于标识偏向锁 11
可以看到,当对象状态为偏向锁时, Mark Word 存储的是偏向的线程ID;当状态为轻量级锁时, Mark Word 存储的是指向线程栈中 Lock Record 的指针;当状态为重量级锁时, Mark Word 为指向堆中的monitor对象的指针 。
有关Java对象头的知识,参考《深入浅出Java多线程》。
JVM锁原理
简单点来说,JVM中锁的原理如下。
在Java对象的对象头上,有一个锁的标记,比如,第一个线程执行程序时,检查Java对象头中的锁标记,发现Java对象头中的锁标记为未加锁状态,于是为Java对象进行了加锁操作,将对象头中的锁标记设置为锁定状态。第二个线程执行同样的程序时,也会检查Java对象头中的锁标记,此时会发现Java对象头中的锁标记的状态为锁定状态。于是,第二个线程会进入相应的阻塞队列中进行等待。
这里有一个关键点就是Java对象头中的锁标记如何实现。
JVM锁的短板JVM中提供的synchronized和Lock锁都是JVM级别的,大家都知道,当运行一个Java程序时,会启动一个JVM进程来运行我们的应用程序。synchronized和Lock在JVM级别有效,也就是说,synchronized和Lock在同一Java进程内有效。如果我们开发的应用程序是分布式的,那么只是使用synchronized和Lock来解决分布式场景下的高并发问题,就会显得有点力不从心了。
synchronized和Lock支持JVM同一进程内部的线程互斥
synchronized和Lock在JVM级别能够保证高并发程序的互斥,我们可以使用下图来表示。
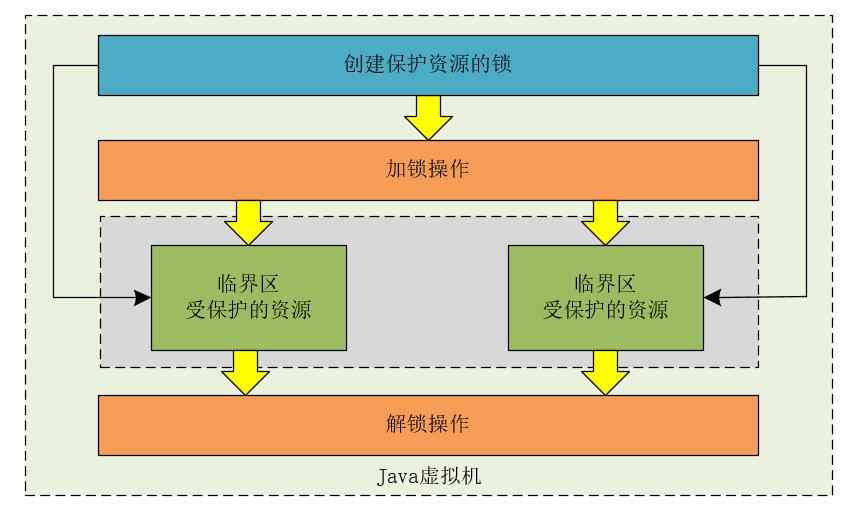
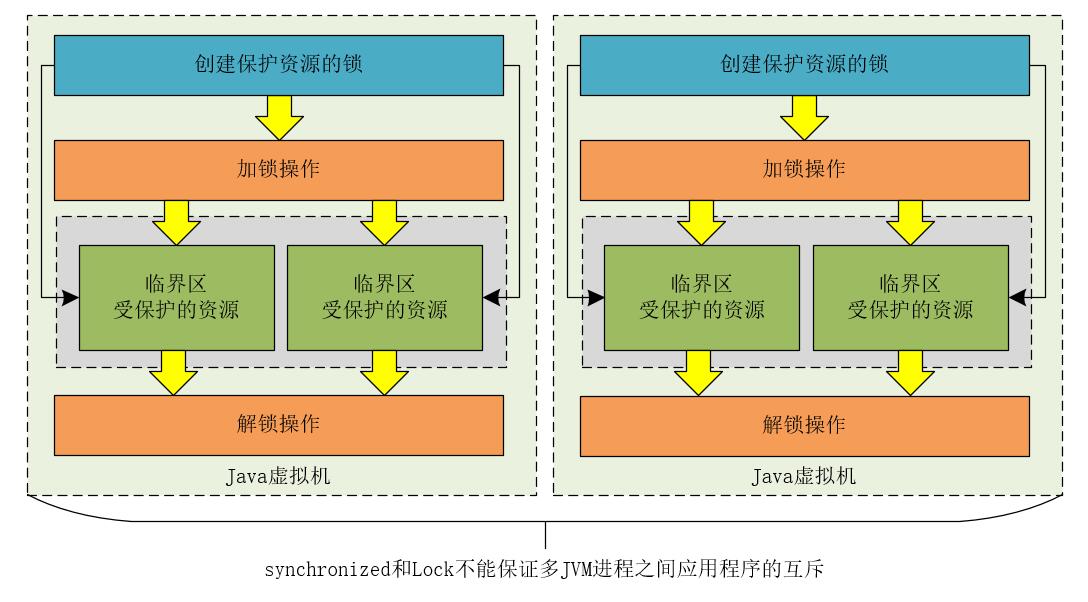
但是,当我们将应用程序部署成分布式架构,或者将应用程序在不同的JVM进程中运行时,synchronized和Lock就不能保证分布式架构和多JVM进程下应用程序的互斥性了。
synchronized和Lock不能实现多JVM进程之间的线程互斥
分布式架构和多JVM进程的本质都是将应用程序部署在不同的JVM实例中,也就是说,其本质还是多JVM进程。
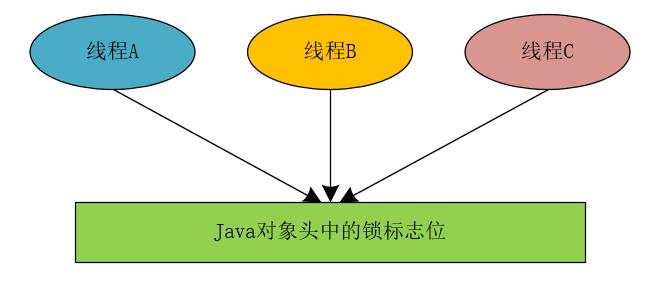
我们在实现分布式锁时,可以参照JVM锁实现的思想,JVM锁在为对象加锁时,通过改变Java对象的对象头中的锁的标志位来实现,也就是说,所有的线程都会访问这个Java对象的对象头中的锁标志位。
我们同样以这种思想来实现分布式锁,当我们将应用程序进行拆分并部署成分布式架构时,所有应用程序中的线程访问共享变量时,都到同一个地方去检查当前程序的临界区是否进行了加锁操作,而是否进行了加锁操作,我们在统一的地方使用相应的状态来进行标记。
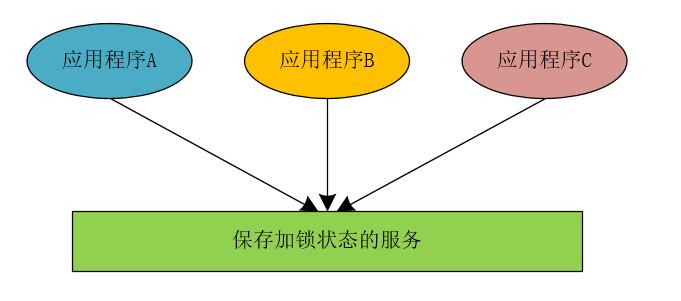
可以看到,在分布式锁的实现思想上,与JVM锁相差不大。而在实现分布式锁中,保存加锁状态的服务可以使用MySQL、Redis和Zookeeper实现。
但是,在互联网高并发环境中, 使用Redis实现分布式锁的方案是使用的最多的。 接下来,我们就使用Redis来深入解密分布式锁的架构设计。
Redis如何实现分布式锁 Redis命令在Redis中,有一个不常使用的命令如下所示。
SETNX key value这条命令的含义就是“SET if Not Exists”,即不存在的时候才会设置值。
只有在key不存在的情况下,将键key的值设置为value。如果key已经存在,则SETNX命令不做任何操作。
这个命令的返回值如下。
命令在设置成功时返回1。
命令在设置失败时返回0。