
其中,黑分类器风险判定是根据特征、机器学习算法、规则/经验模型,来判断本次请求异常的概率。而白分类器风险判定则是判断属于正常请求的概率。见下图4示意:
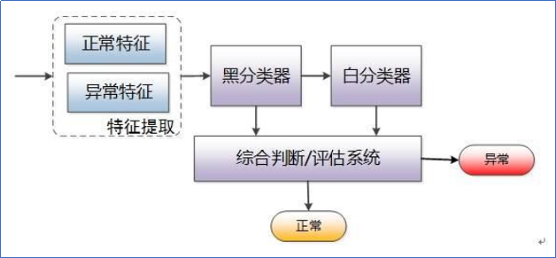
图4 风险引擎的宏观构成
2.分类器逻辑框架如何实现风险评估的判定呢?我们以黑分类器为例,来详细剖析下分类器的逻辑框架。
系统总体是采用一种矩阵式的逻辑框架。
黑分类器最初设计是整体检测判定,即按需随意地建立一个个针对黑产的检测规则、模型。但这种设计出来的结果,发现不是这个逻辑漏过了,而是那个逻辑误伤量大,要对某一类的账号加强安全打击力度,改动起来也非常麻烦。
因此,我们最终设计出一套矩阵式的框架(见下图5),较好地解决上述问题。
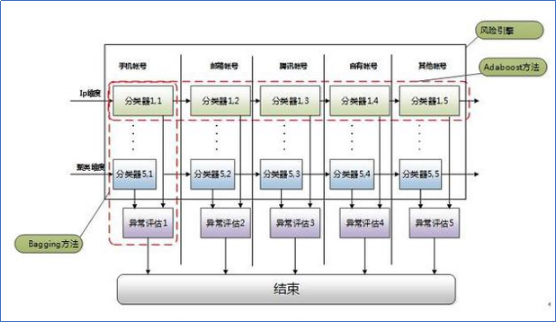
图5 黑分类器的矩阵逻辑框架
矩阵的横向采用了Adaboost方法,该方法是一种迭代算法,其核心思想是针对同一个训练集训练不同的弱分类器,然后把这些分类器集合起来,构成一个最终的分类器。而我们这里每一个弱分类器都只能解决一种帐号类型的安全风险判断,集中起来才能解决所有账户的风险检测。
这个矩阵逻辑的横向方法,在工程实现上也带来三个好处:
1.便于实现轻重分离。比如某平台虚假账号集中在邮箱账号,策略就可以加大对邮箱账号的打击力度,影响范围也局限在邮箱帐号,而不是该平台所有的账号。
2.减少模型训练的难度。模型训练最大的难度在于样本的均衡性问题,拆分成子问题,就不需要考虑不同账号类型之间的数据配比、均衡性问题,大大降低了模型训练时正负样本比率的问题。
3.逻辑的健壮性。某一个分类器的训练出现了问题,受影响的范围不至于扩展到全局。
矩阵纵向则采用了Bagging方法,该方法是一种用来提高学习算法准确度的方法。它在同一个训练集合上构造预测函数系列,然后设法将他们组合成一个预测函数,从而来提高预测结果的准确性。
腾讯大数据处理平台-魔方毫无疑问,对抗黑产刷单离不开大数据。大数据一直在安全对抗领域发挥着重要的作用,从我们的对抗经验来看,大数据不仅仅是数据规模很大,而且还包括两个方面:
1.数据广度:要有丰富的数据类型。比如,不仅仅要有社交领域的数据、还要有游戏、支付、自媒体等领域的数据,这样就提供了一个广阔的视野让我们来看待黑产的行为特点。
2.数据深度:黑产的对抗,我们一直强调纵深防御。不仅仅要有注册数据,还要有登录,以及账号的使用的数据,这样我们才能更好的识别恶意。
所以想要做风控和大数据的团队,一定要注意在自己的产品上多埋点,拿到足够多的数据,先沉淀下来。
腾讯安全团队研发了一个叫魔方的大数据处理和分析的平台,底层集成了MySQL、MongoDB,Spark、Hadoop等技术,在用户层面我们只需要写一些简单的SQL语句、完成一些配置就可以实现例行分析。
这里我们收集了社交、电商、支付、游戏等场景的数据,针对这些数据我们建立一些模型,发现哪些是恶意的数据,并且将数据沉淀下来。
沉淀下来的对安全有意义的数据,一方面就存储在魔方平台上,供线下审计做模型使用;另一方面会做成实时的服务,提供给线上的系统查询使用。
一.腾讯用户画像沉淀方法用户画像,本质上就是给账号、设备等打标签。但我们这里主要从安全的角度出发来打标签,比如IP画像,我们会标注IP是不是代理IP,这些对我们做策略是有帮助的。
我们看看腾讯的IP画像,目前沉淀的逻辑如下图6:

图6 IP画像系统构成
一般的业务都有针对IP的频率、次数限制的策略,那么黑产为了对抗,必然会大量采用代理IP来绕过限制。既然代理IP的识别如此重要,那我们就以代理IP为例来谈下腾讯识别代理IP的过程。
识别一个IP是不是代理IP,技术不外乎就是如下四种:
1.反向探测技术:扫描IP是不是开通了80,8080等代理服务器经常开通的端口,显然一个普通的用户IP不太可能开通如上的端口。
2.HTTP头部的X_Forwarded_For:开通了HTTP代理的IP可以通过此法来识别是不是代理IP;如果带有XFF信息,该IP是代理IP无疑。
3.Keep-alive报文:如果带有Proxy-Connection的Keep-alive报文,该IP毫无疑问是代理IP。
4.查看IP上端口:如果一个IP有的端口大于10000,那么该IP大多也存在问题,普通的家庭IP开这么大的端口几乎是不可能的。
以上代理IP检测的方法几乎都是公开的,但是盲目去扫描全网的IP,被拦截不说,效率也是一个很大的问题。