
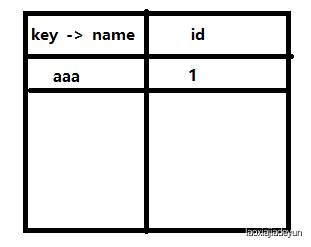
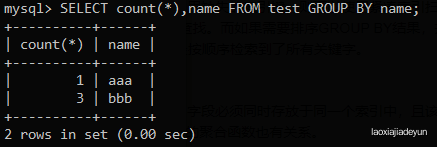
然后继续往下走,到了bbb,不存在,也放进去
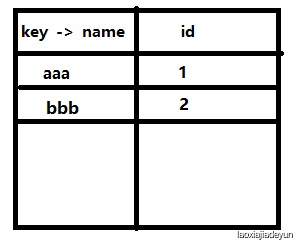
往下执行,遇到多余的bbb,已经有bbb存在,就汇总在一起,内部情况如下:
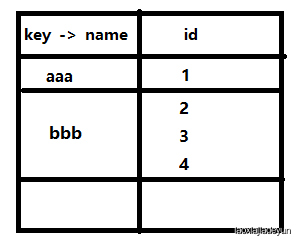
如下,最后在查询的时候根据group by内部的实现方式返回分类后的结果:
当我们加上count(*)函数时,操作过程为:查看虚拟表存在不,不存在则插入新记录,存在则count(*)字段直接加1
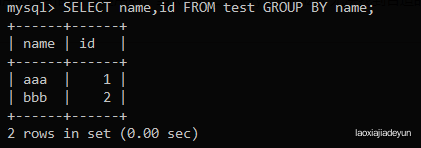
这样就能对上面的分类结果进行统计,然后将统计结果返回:
所以双查询报错的关键就在这里,主要的原因在于rand()函数在group by的过程中被触发了多次,
part 3 报错原理让我们回看一下构造的报错语句:
mysql> SELECT count(*),concat((SELECT database()),"~",floor(rand()*2))as a FROM test GROUP BY a;执行前虚拟表为空:
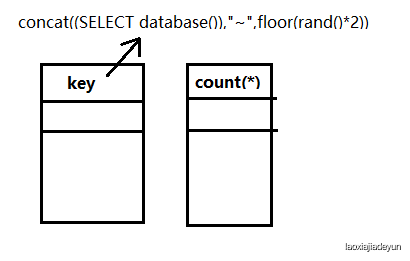
当第一次执行时,group by 分组,其取的数据的是以a为别名的这条语句,假设这时的concat((SELECT database()),"~",floor(rand()*2))生成结果为sql_test~0,group就以sql_test~0查询虚拟表,发现表中没有该值的主键,于是将这条语句的结果插入到虚拟表中。
注意!是将这条语句的结果插入到虚拟表中,而不是将 sql_test~0 插入到虚拟表中,如下:
(将concat((SELECT database()),"~",floor(rand()*2)) 以a为别名,方便作图)

由于虚拟表没有内容,所以会将其插入到虚拟表中,这里的插入过程中,由于插入的是a语句的结果,所以在插入时a语句中的rand()函数会再次执行,即插入的值可能为sql_test~0 也可能为 sql_test~1 ,这里假设插入时a执行的结果为sql_test~0 :
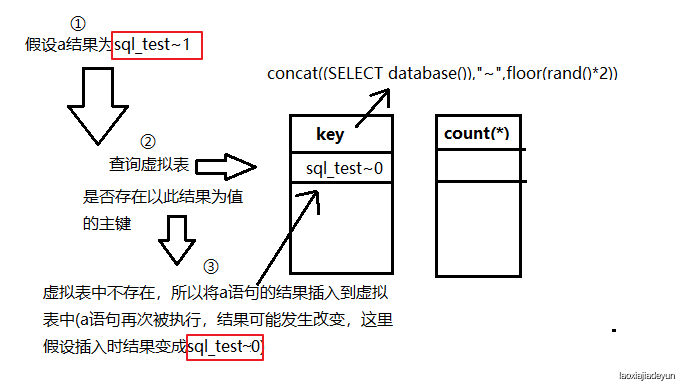
所以上面的情况就是用sql_test~1这个结果查询虚拟表,不存在该数据,于是插入虚拟表,插入时又运算一次,然后插入的值变成了sql_test~0,所以这就是主要的冲突,表中只有一条数据还好,即使查询虚拟表的值和插入虚拟表的值不是同一个,但只有虚拟表也只生成一条记录,不会出现问题。
然而当表的数据出现两条以上的时候,第group by 在处理完第一条数据后会往下继续处理第二条,于是第二条还会按第一条的处理方式进行:
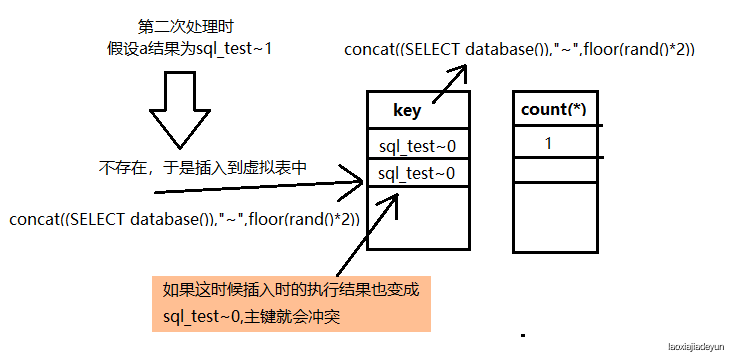
于是就会报错,报错内容如下:
ERROR 1062 (23000): Duplicate entry 'sql_test~0' for key 'group_key'
如果第二次查询和插入的结果都一致:就会有下面两种情况:
都是sql_test~0:表里已存在,该主键的count(*)值+1
都是sql_test~1:表里没有,插入形成新的主键