
首先第一点,定义机器级别程序的格式和行为被称为 指令集体系结构或指令集架构(instruction set architecture), ISA。ISA 定义了进程状态、指令的格式和每一个指令对状态的影响。大部分的指令集架构包括 ISA 用来描述进程的行为就好像是顺序执行的,一条指令执行结束后,另外一条指令再开始。处理器硬件的描述要更复杂,它可以同时并行执行许多指令,但是它采用了安全措施来确保整体行为与 ISA 规定的顺序一致。
第二点,机器级别对内存地址的描述就是 虚拟地址(virtual address),它提供了一个内存模型来表示一个巨大的字节数组。
编译器在整个编译的过程中起到了至关重要的作用,把 C 语言转换为处理器执行的基本指令。汇编代码非常接近于机器代码,只不过与二进制机器代码相比,汇编代码的可读性更强,所以理解汇编是理解机器工作的第一步。
一些进程状态对机器可见,但是 C 语言程序员却看不到这些,包括
程序计数器(Program counter),它存储下一条指令的地址,在 x86-64 架构中用 %rip 来表示。
程序执行时,PC 的初始值为程序第一条指令的地址,在顺序执行程序时, CPU 首先按程序计数器所指出的指令地址从内存中取出一条指令,然后分析和执行该指令,同时将 PC 的值加 1 并指向下一条要执行的指令。
比如下面一个例子。
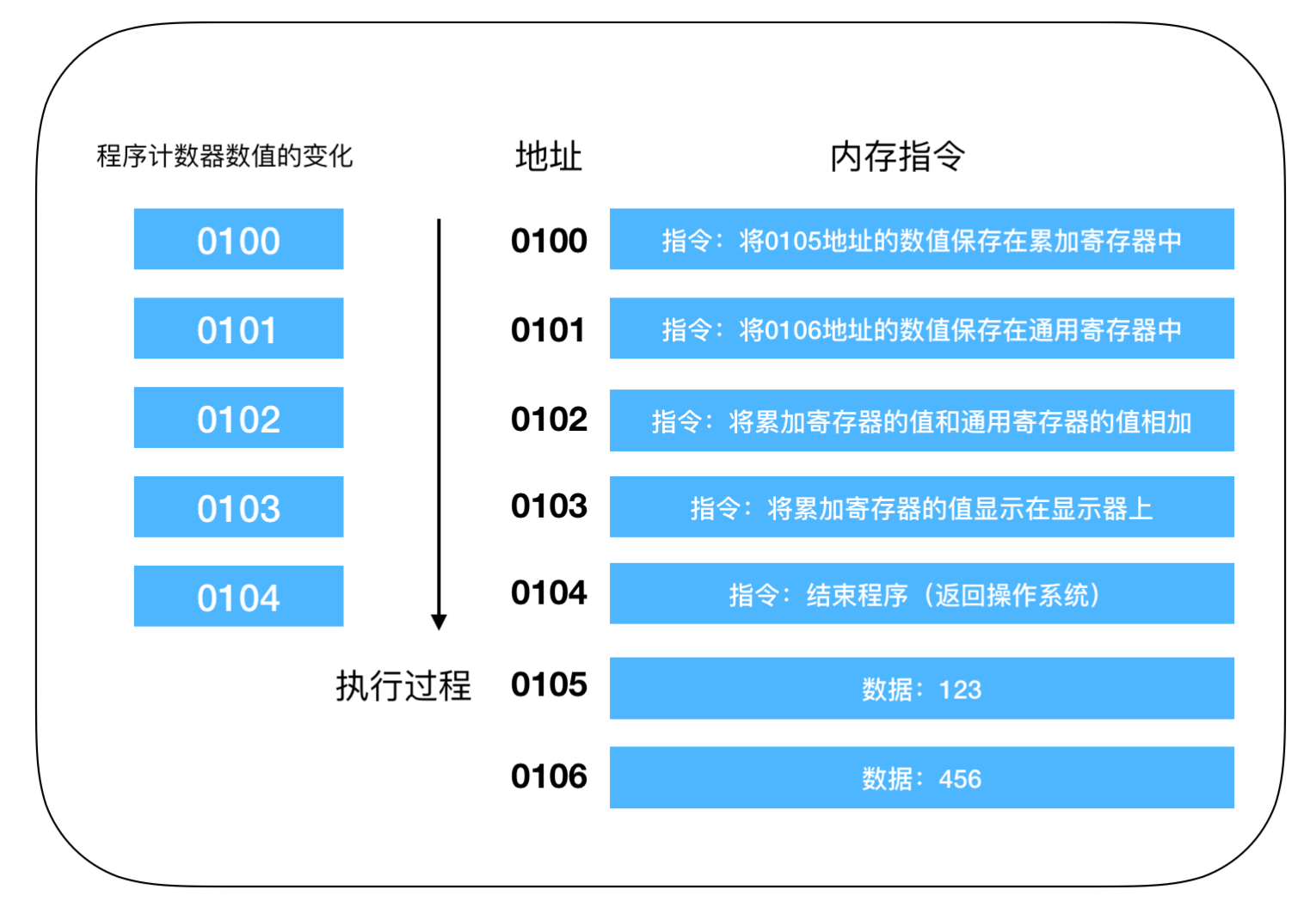
这是一段数值进行相加的操作,程序启动,在经过编译解析后会由操作系统把硬盘中的程序复制到内存中,示例中的程序是将 123 和 456 执行相加操作,并将结果输出到显示器上。由于使用机器语言难以描述,所以这是经过翻译后的结果,实际上每个指令和数据都可能分布在不同的地址上,但为了方便说明,把组成一条指令的内存和数据放在了一个内存地址上。
整数寄存器文件(register file)包含 16 个命名的位置,用来存储 64 位的值。这些寄存器可以存储地址和整型数据。有些寄存器用于跟踪程序状态,而另一些寄存器用于保存临时数据,例如过程的参数和局部变量,以及函数要返回的值。这个 文件 是和磁盘文件无关的,它只是 CPU 内部的一块高速存储单元。有专用的寄存器,也有通用的寄存器用来存储操作数。
条件码寄存器 用来保存有关最近执行的算术或逻辑指令的状态信息。这些用于实现控件或数据流中的条件更改,例如实现 if 和 while 语句所需的条件更改。我们都学过高级语言,高级语言中的条件控制流程主要分为三种:顺序执行、条件分支、循环判断三种,顺序执行是按照地址的内容顺序的执行指令。条件分支是根据条件执行任意地址的指令。循环是重复执行同一地址的指令。
顺序执行的情况比较简单,每执行一条指令程序计数器的值就是 + 1。
条件和循环分支会使程序计数器的值指向任意的地址,这样一来,程序便可以返回到上一个地址来重复执行同一个指令,或者跳转到任意指令。
下面以条件分支为例来说明程序的执行过程(循环也很相似)

程序的开始过程和顺序流程是一样的,CPU 从 0100 处开始执行命令,在 0100 和 0101 都是顺序执行,PC 的值顺序+1,执行到 0102 地址的指令时,判断 0106 寄存器的数值大于 0,跳转(jump)到 0104 地址的指令,将数值输出到显示器中,然后结束程序,0103 的指令被跳过了,这就和我们程序中的 if() 判断是一样的,在不满足条件的情况下,指令会直接跳过。所以 PC 的执行过程也就没有直接+1,而是下一条指令的地址。
一组 向量寄存器用来存储一个或者多个整数或者浮点数值,向量寄存器是对一维数据上进行操作。
机器指令只会执行非常简单的操作,例如将存放在寄存器的两个数进行相加,把数据从内存转移到寄存器中或者是条件分支转移到新的指令地址。编译器必须生成此类指令的序列,以实现程序构造,例如算术表达式求值,循环或过程调用和返回
认识汇编我相信各位应该都知道汇编语言的出现背景吧,那就是二进制表示数据,太复杂太庞大了,为了解决这个问题,出现了汇编语言,汇编语言和机器指令的区别就在于表示方法上,汇编使用操作数来表示,机器指令使用二进制来表示,我之前多次提到机器码就是汇编,你也不能说我错,但是不准确。
但是汇编适合二进制代码存在转换关系的。