

Redisson是用于在Java程序中操作Redis的库,利用Redisson我们可以在程序中轻松地使用Redis。Redisson这个客户端工具实现了布隆过滤器,其底层就是通过bitmap这种数据结构来实现的。
Redis 4.0提供了插件功能之后,Redis就提供了布隆过滤器功能。布隆过滤器作为一个插件加载到了Redis Server之中,给Redis提供了强大的布隆去重功能。此文就不细讲了,大家感兴趣地可到官方查看详细文档介绍。它又如下常用命令:
bf.add:添加元素
bf.madd:批量添加元素
bf.exists:检索元素是否存在
bf.mexists:检索多个元素是否存在
bf.reserve:自定义布隆过滤器,设置key,error_rate和initial_size
下面演示是在本地单节点Redis实现的,如果数据量很大,并且误差率又很低的情况下,那单节点内存可能会不足。当然,在集群Redis中,也是可以通过Redisson实现分布式布隆过滤器的。
引入依赖
<!-- https://mvnrepository.com/artifact/org.redisson/redisson --> <dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>3.13.6</version> </dependency>代码测试
package com.nobody; import org.redisson.Redisson; import org.redisson.api.RBloomFilter; import org.redisson.api.RedissonClient; import org.redisson.config.Config; /** * @Description * @Author Mr.nobody * @Date 2021/3/6 * @Version 1.0 */ public class RedissonDemo { public static void main(String[] args) { Config config = new Config(); config.useSingleServer().setAddress("redis://127.0.0.1:6379"); // config.useSingleServer().setPassword("123456"); RedissonClient redissonClient = Redisson.create(config); // 获取一个redis key为users的布隆过滤器 RBloomFilter<Integer> bloomFilter = redissonClient.getBloomFilter("users"); // 假设元素个数为10万 int size = 100000; // 进行初始化,预计元素为10万,误差率为1% bloomFilter.tryInit(size, 0.01); // 将1至100000这十万个数映射到布隆过滤器中 for (int i = 1; i <= size; i++) { bloomFilter.add(i); } // 检查已在过滤器中的值,是否有匹配不上的 for (int i = 1; i <= size; i++) { if (!bloomFilter.contains(i)) { System.out.println("存在不匹配的值:" + i); } } // 检查不在过滤器中的1000个值,是否有匹配上的 int matchCount = 0; for (int i = size + 1; i <= size + 1000; i++) { if (bloomFilter.contains(i)) { matchCount++; } } System.out.println("误判个数:" + matchCount); } }结果存在的10万个元素都匹配上了;不存在布隆过滤器中的1千个元素,有23个误判。
误判个数:23 四 Guava实现布隆过滤器有许多实现与优化,Guava中就提供了一种实现。Google Guava提供的布隆过滤器的位数组是存储在JVM内存中,故是单机版的,并且最大位长为int类型的最大值。
使用布隆过滤器时,重要关注点是预估数据量n以及期望的误判率fpp。
实现布隆过滤器时,重要关注点是hash函数的选取以及bit数组的大小。
Bit数组大小选择
根据预估数据量n以及误判率fpp,bit数组大小的m的计算方式:
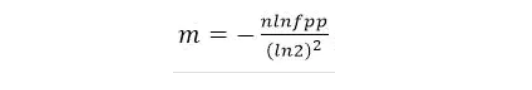
Guava中源码实现如下:
@VisibleForTesting static long optimalNumOfBits(long n, double p) { if (p == 0) { p = Double.MIN_VALUE; } return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2))); }哈希函数选择
哈希函数的个数的选择也是挺讲究的,哈希函数的选择影响着性能的好坏,而且一个好的哈希函数能近似等概率的将元素映射到各个Bit。如何选择构造k个函数呢,一种简单的方法是选择一个哈希函数,然后送入k个不同的参数。
哈希函数的个数k,可以根据预估数据量n和bit数组长度m计算而来:
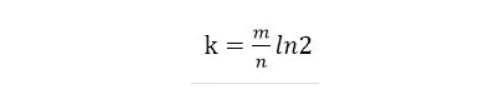
Guava中源码实现如下:
@VisibleForTesting static int optimalNumOfHashFunctions(long n, long m) { // (m / n) * log(2), but avoid truncation due to division! return Math.max(1, (int) Math.round((double) m / n * Math.log(2))); }引入依赖
<!-- https://mvnrepository.com/artifact/com.google.guava/guava --> <dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>28.2-jre</version> </dependency>