
假如有一个15亿用户的系统,每天有几亿用户访问系统,要如何快速判断是否为系统中的用户呢?
方法一,将15亿用户存储在数据库中,每次用户访问系统,都到数据库进行查询判断,准确性高,但是查询速度会比较慢。
方法二,将15亿用户缓存在Redis内存中,每次用户访问系统,都到Redis中进行查询判断,准确性高,查询速度也快,但是占用内存极大。即使只存储用户ID,一个用户ID一个字符,则15亿*8字节=12GB,对于一些内存空间有限的服务器来说相对浪费。
还有对于网站爬虫的项目,我们都知道世界上的网站数量及其之多,每当我们爬一个新的网站url时,如何快速判断是否爬虫过了呢?还有垃圾邮箱的过滤,广告电话的过滤等等。如果还是用上面2种方法,显然不是最好的解决方案。
再者,查询是一个系统最高频的操作,当查询一个数据,首先会先到缓存查询(例如Redis),如果缓存没命中,于是到持久层数据库(mongo,mysql等)查询,发现也没有此数据,于是本此查询失败。如果用户很多的时候,并且缓存都没命中,进而全部请求了持久层数据库,这就给数据库带来很大压力,严重可能拖垮数据库。俗称缓存穿透。
可能大家也听到另一个词叫缓存击穿,它是指一个热点key,不停着扛着高并发,突然这个key失效了,在失效的瞬间,大量的请求缓存就没命中,全部请求到数据库。
对于以上这些以及类似的场景,如何高效的解决呢?针对此,布隆过滤器应运而生了。
二 布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
二进制向量,简单理解就是一个二进制数组。这个数组里面存放的值要么是0,要么是1。
映射函数,它可以将一个元素映射成一个位阵列(Bit array)中的一个点。所以通过这个点,就能判断集合中是否有此元素。
基本思想
当一个元素被加入集合时,通过K个散列函数将这个元素映射到一个位数组中的K个点,把它们置为1。
检索某个元素时,再通过这K个散列函数将这个元素映射,看看这些位置是不是都是1就能知道集合中这个元素存不存在。如果这些位置有任何一个0,则该元素一定不存在;如果都是1,则被检元素很可能存在。
Bloom Filter跟单个哈希函数映射不同,Bloom Filter使用了k个哈希函数,每个元素跟k个bit对应。从而降低了冲突的概率。

优点
二进制组成的数组,内存占用空间少,并且插入和查询速度很快,常数级别。
Hash函数相互之间没有必然联系,方便由硬件并行实现。
只存储0和1,不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
缺点
存在误差率。随着存入的元素数量增加,误算率随之增加。(比如现实中你是否遇到正常邮件也被放入垃圾邮件目录,正常短信被拦截)可以增加一个小的白名单,存储那些可能被误判的元素。
删除困难。一个元素映射到bit数组的k个位置上是1,删除的时候不能简单的直接置为0,可能会影响其他元素的判断。因为其他元素的映射也有可能在相同的位置置为1。可以采用Counting Bloom Filter解决。
三 Redis实现在Redis中,有一种数据结构叫位图,即bitmap。以下是一些常用的操作命令。
在Redis命令中,SETBIT key offset value,此命令表示将key对应的值的二进制数组,从左向右起,offset下标的二进制数字设置为value。

键k1对应的值为keke,对应ASCII码为107 101 107 101,对应的二进制为 0110 1011,0110 0101,0110 1011,0110 0101。将下标5的位置设置为1,所以变成 0110 1111,0110 0101,0110 1011,0110 0101。即 oeke。
GETBIT key offset命令,它用来获取指定下标的值。
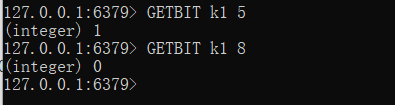
还有一个比较常用的命令,BITCOUNT key [start end],用来获取位图中指定范围值为1的个数。注意,start和end指定的是字节的个数,而不是位数组下标。